 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
Paper and Code

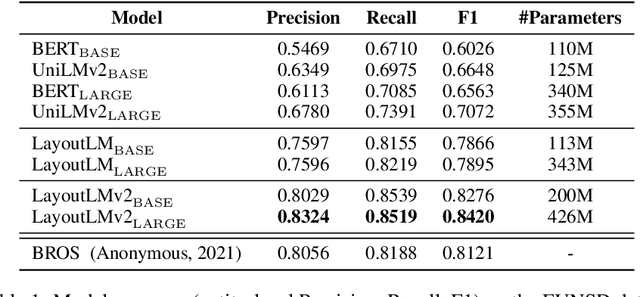
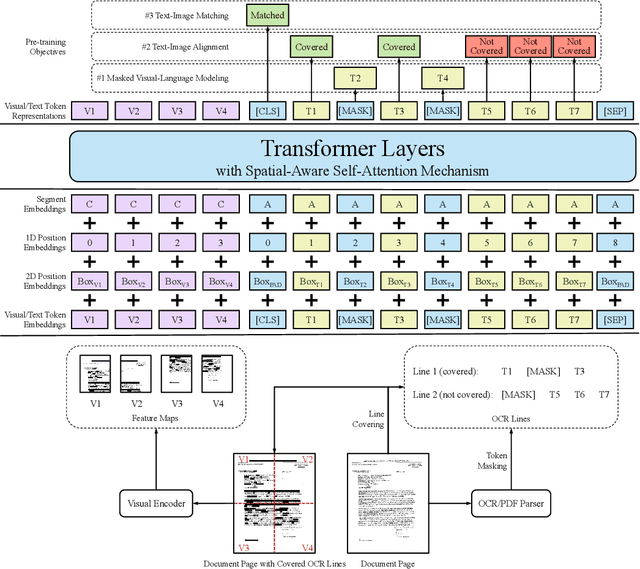
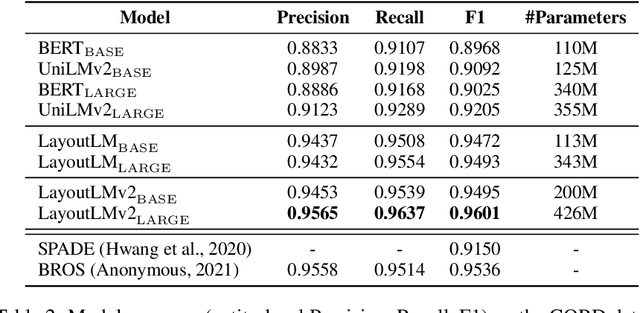
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this paper, we present \textbf{LayoutLMv2} by pre-training text, layout and image in a multi-modal framework, where new model architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention mechanism into the Transformer architecture, so that the model can fully understand the relative positional relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852), RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672).