 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVP: Pre-trained Visual Parameter-Efficient Tuning
Paper and Code
Apr 26, 2023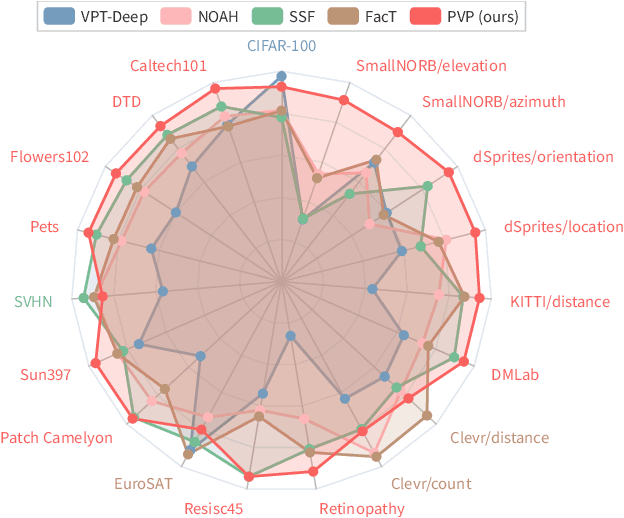
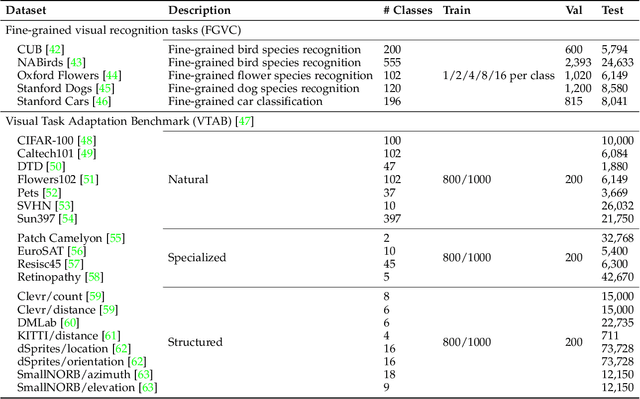
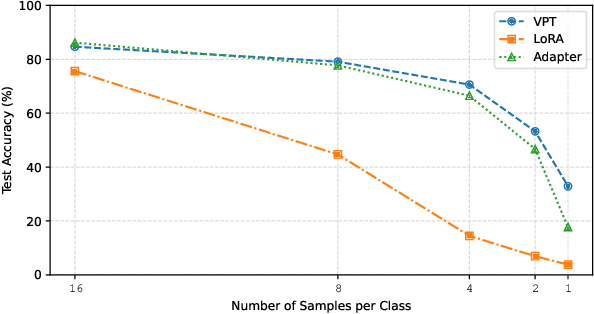
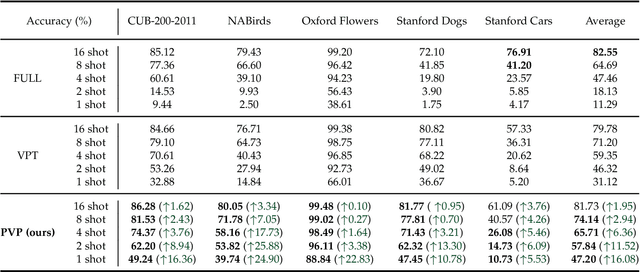
Large-scale pre-trained transformers have demonstrated remarkable success in various computer vision tasks. However, it is still highly challenging to fully fine-tune these models for downstream tasks due to their high computational and storage costs. Recently, Parameter-Efficient Tuning (PETuning) techniques, e.g., Visual Prompt Tuning (VPT) and Low-Rank Adaptation (LoRA), have significantly reduced the computation and storage cost by inserting lightweight prompt modules into the pre-trained models and tuning these prompt modules with a small number of trainable parameters, while keeping the transformer backbone frozen. Although only a few parameters need to be adjusted, most PETuning methods still require a significant amount of downstream task training data to achieve good results. The performance is inadequate on low-data regimes, especially when there are only one or two examples per class. To this end, we first empirically identify the poor performance is mainly due to the inappropriate way of initializing prompt modules, which has also been verified in the pre-trained language models. Next, we propose a Pre-trained Visual Parameter-efficient (PVP) Tuning framework, which pre-trains the parameter-efficient tuning modules first and then leverages the pre-trained modules along with the pre-trained transformer backbone to perform parameter-efficient tuning on downstream tasks. Experiment results on five Fine-Grained Visual Classification (FGVC) and VTAB-1k datasets demonstrate that our proposed method significantly outperforms state-of-the-art PETuning methods.