 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Cross-Domain Knowledge Distillation for Cross-Dataset Text-to-Image Person Retrieval
Jan 25, 2025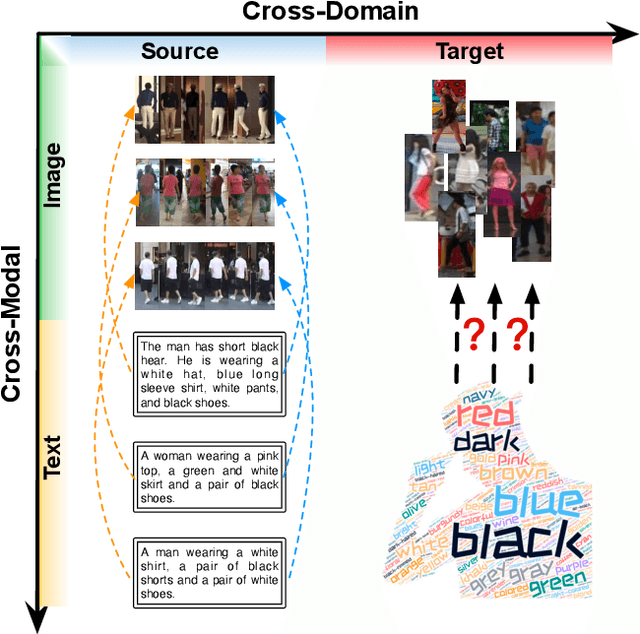
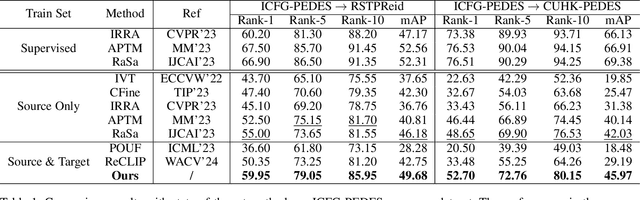
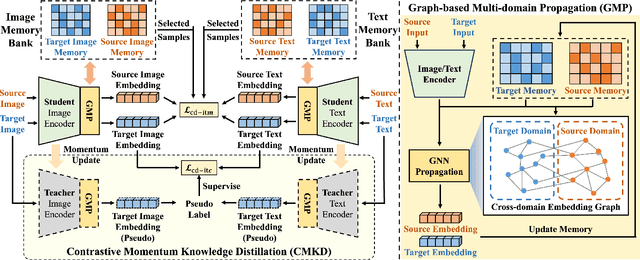
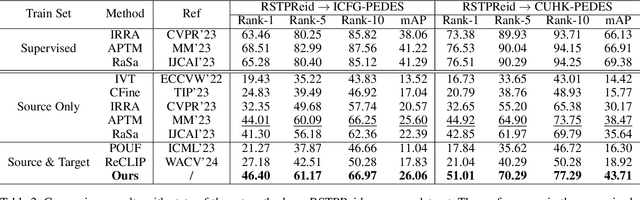
Video surveillance systems are crucial components for ensuring public safety and management in smart city. As a fundamental task in video surveillance, text-to-image person retrieval aims to retrieve the target person from an image gallery that best matches the given text description. Most existing text-to-image person retrieval methods are trained in a supervised manner that requires sufficient labeled data in the target domain. However, it is common in practice that only unlabeled data is available in the target domain due to the difficulty and cost of data annotation, which limits the generalization of existing methods in practical application scenarios. To address this issue, we propose a novel unsupervised domain adaptation method, termed Graph-Based Cross-Domain Knowledge Distillation (GCKD), to learn the cross-modal feature representation for text-to-image person retrieval in a cross-dataset scenario. The proposed GCKD method consists of two main components. Firstly, a graph-based multi-modal propagation module is designed to bridge the cross-domain correlation among the visual and textual samples. Secondly, a contrastive momentum knowledge distillation module is proposed to learn the cross-modal feature representation using the online knowledge distillation strategy. By jointly optimizing the two modules, the proposed method is able to achieve efficient performance for cross-dataset text-to-image person retrieval. acExtensive experiments on three publicly available text-to-image person retrieval datasets demonstrate the effectiveness of the proposed GCKD method, which consistently outperforms the state-of-the-art baselines.
Multi-Energy Guided Image Translation with Stochastic Differential Equations for Near-Infrared Facial Expression Recognition
Dec 10, 2023
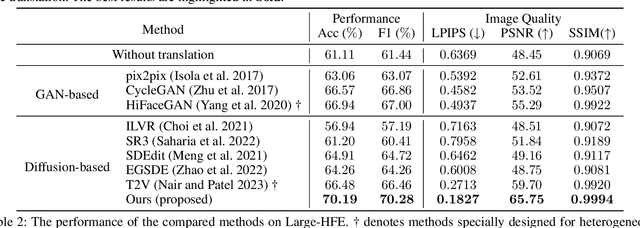

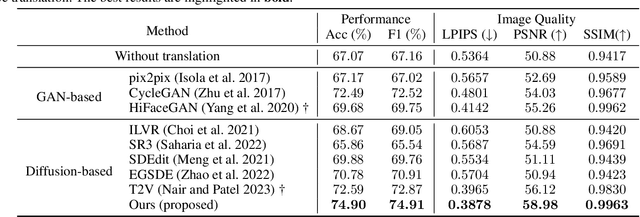
Illumination variation has been a long-term challenge in real-world facial expression recognition(FER). Under uncontrolled or non-visible light conditions, Near-infrared (NIR) can provide a simple and alternative solution to obtain high-quality images and supplement the geometric and texture details that are missing in the visible domain. Due to the lack of existing large-scale NIR facial expression datasets, directly extending VIS FER methods to the NIR spectrum may be ineffective. Additionally, previous heterogeneous image synthesis methods are restricted by low controllability without prior task knowledge. To tackle these issues, we present the first approach, called for NIR-FER Stochastic Differential Equations (NFER-SDE), that transforms face expression appearance between heterogeneous modalities to the overfitting problem on small-scale NIR data. NFER-SDE is able to take the whole VIS source image as input and, together with domain-specific knowledge, guide the preservation of modality-invariant information in the high-frequency content of the image. Extensive experiments and ablation studies show that NFER-SDE significantly improves the performance of NIR FER and achieves state-of-the-art results on the only two available NIR FER datasets, Oulu-CASIA and Large-HFE.
Hypergraph-Guided Disentangled Spectrum Transformer Networks for Near-Infrared Facial Expression Recognition
Dec 10, 2023



With the strong robusticity on illumination variations, near-infrared (NIR) can be an effective and essential complement to visible (VIS) facial expression recognition in low lighting or complete darkness conditions. However, facial expression recognition (FER) from NIR images presents more challenging problem than traditional FER due to the limitations imposed by the data scale and the difficulty of extracting discriminative features from incomplete visible lighting contents. In this paper, we give the first attempt to deep NIR facial expression recognition and proposed a novel method called near-infrared facial expression transformer (NFER-Former). Specifically, to make full use of the abundant label information in the field of VIS, we introduce a Self-Attention Orthogonal Decomposition mechanism that disentangles the expression information and spectrum information from the input image, so that the expression features can be extracted without the interference of spectrum variation. We also propose a Hypergraph-Guided Feature Embedding method that models some key facial behaviors and learns the structure of the complex correlations between them, thereby alleviating the interference of inter-class similarity. Additionally, we have constructed a large NIR-VIS Facial Expression dataset that includes 360 subjects to better validate the efficiency of NFER-Former. Extensive experiments and ablation studies show that NFER-Former significantly improves the performance of NIR FER and achieves state-of-the-art results on the only two available NIR FER datasets, Oulu-CASIA and Large-HFE.