 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowRU: Knowledge Reusing via Knowledge Distillation in Multi-agent Reinforcement Learning
Paper and Code
Mar 27, 2021
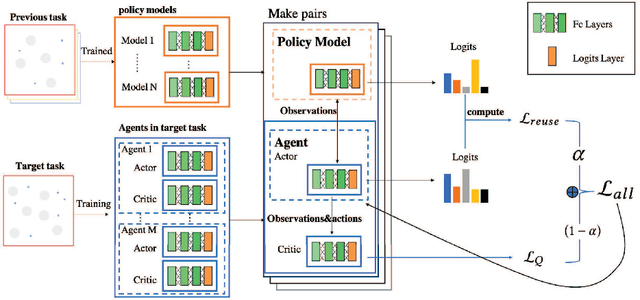


Recently, deep Reinforcement Learning (RL) algorithms have achieved dramatically progress in the multi-agent area. However, training the increasingly complex tasks would be time-consuming and resources-exhausting. To alleviate this problem, efficient leveraging the historical experience is essential, which is under-explored in previous studies as most of the exiting methods may fail to achieve this goal in a continuously variational system due to their complicated design and environmental dynamics. In this paper, we propose a method, named "KnowRU" for knowledge reusing which can be easily deployed in the majority of the multi-agent reinforcement learning algorithms without complicated hand-coded design. We employ the knowledge distillation paradigm to transfer the knowledge among agents with the goal to accelerate the training phase for new tasks, while improving the asymptotic performance of agents. To empirically demonstrate the robustness and effectiveness of KnowRU, we perform extensive experiments on state-of-the-art multi-agent reinforcement learning (MARL) algorithms on collaborative and competitive scenarios. The results show that KnowRU can outperform the recently reported methods, which emphasizes the importance of the proposed knowledge reusing for MARL.