 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing 3D Fast Spin Echo Anatomical Imaging to Reduce the Number of Contrast Preparations in $T_{1ρ}$ Quantification of Knee Cartilage Using Learning-Based Methods
Feb 13, 2025
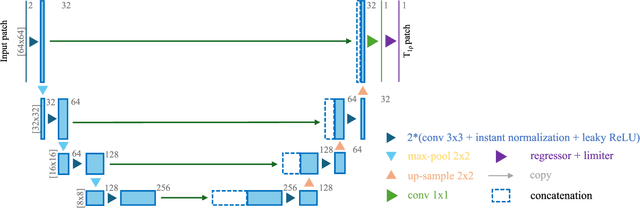
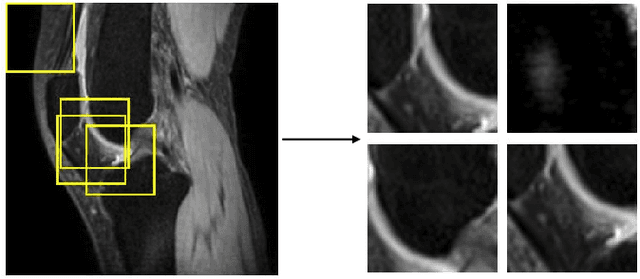

Purpose: To propose and evaluate an accelerated $T_{1\rho}$ quantification method that combines $T_{1\rho}$-weighted fast spin echo (FSE) images and proton density (PD)-weighted anatomical FSE images, leveraging deep learning models for $T_{1\rho}$ mapping. The goal is to reduce scan time and facilitate integration into routine clinical workflows for osteoarthritis (OA) assessment. Methods: This retrospective study utilized MRI data from 40 participants (30 OA patients and 10 healthy volunteers). A volume of PD-weighted anatomical FSE images and a volume of $T_{1\rho}$-weighted images acquired at a non-zero spin-lock time were used as input to train deep learning models, including a 2D U-Net and a multi-layer perceptron (MLP). $T_{1\rho}$ maps generated by these models were compared with ground truth maps derived from a traditional non-linear least squares (NLLS) fitting method using four $T_{1\rho}$-weighted images. Evaluation metrics included mean absolute error (MAE), mean absolute percentage error (MAPE), regional error (RE), and regional percentage error (RPE). Results: Deep learning models achieved RPEs below 5% across all evaluated scenarios, outperforming NLLS methods, especially in low signal-to-noise conditions. The best results were obtained using the 2D U-Net, which effectively leveraged spatial information for accurate $T_{1\rho}$ fitting. The proposed method demonstrated compatibility with shorter TSLs, alleviating RF hardware and specific absorption rate (SAR) limitations. Conclusion: The proposed approach enables efficient $T_{1\rho}$ mapping using PD-weighted anatomical images, reducing scan time while maintaining clinical standards. This method has the potential to facilitate the integration of quantitative MRI techniques into routine clinical practice, benefiting OA diagnosis and monitoring.
Chemical Shift Encoding based Double Bonds Quantification in Triglycerides using Deep Image Prior
Jul 02, 2024



This study evaluated a deep learning-based method using Deep Image Prior (DIP) to quantify triglyceride double bonds from chemical-shift encoded multi-echo gradient echo images without network training. We employed a cost function based on signal constraints to iteratively update the neural network on a single dataset. The method was validated using phantom experiments and in vivo scans. Results showed close alignment between measured and reference double bond values, with phantom experiments yielding a Pearson correlation coefficient of 0.96 (p = .0005). In vivo results demonstrated good agreement in subcutaneous fat. We conclude that Deep Image Prior shows feasibility for quantifying double bonds and fatty acid content from chemical-shift encoded multi-echo MRI.
An Uncertainty Aided Framework for Learning based Liver $T_1ρ$ Mapping and Analysis
Jul 07, 2023Objective: Quantitative $T_1\rho$ imaging has potential for assessment of biochemical alterations of liver pathologies. Deep learning methods have been employed to accelerate quantitative $T_1\rho$ imaging. To employ artificial intelligence-based quantitative imaging methods in complicated clinical environment, it is valuable to estimate the uncertainty of the predicated $T_1\rho$ values to provide the confidence level of the quantification results. The uncertainty should also be utilized to aid the post-hoc quantitative analysis and model learning tasks. Approach: To address this need, we propose a parametric map refinement approach for learning-based $T_1\rho$ mapping and train the model in a probabilistic way to model the uncertainty. We also propose to utilize the uncertainty map to spatially weight the training of an improved $T_1\rho$ mapping network to further improve the mapping performance and to remove pixels with unreliable $T_1\rho$ values in the region of interest. The framework was tested on a dataset of 51 patients with different liver fibrosis stages. Main results: Our results indicate that the learning-based map refinement method leads to a relative mapping error of less than 3% and provides uncertainty estimation simultaneously. The estimated uncertainty reflects the actual error level, and it can be used to further reduce relative $T_1\rho$ mapping error to 2.60% as well as removing unreliable pixels in the region of interest effectively. Significance: Our studies demonstrate the proposed approach has potential to provide a learning-based quantitative MRI system for trustworthy $T_1\rho$ mapping of the liver.
Uncertainty-weighted Multi-tasking for $T_{1ρ}$ and T$_2$ Mapping in the Liver with Self-supervised Learning
Mar 14, 2023Multi-parametric mapping of MRI relaxations in liver has the potential of revealing pathological information of the liver. A self-supervised learning based multi-parametric mapping method is proposed to map T$T_{1\rho}$ and T$_2$ simultaneously, by utilising the relaxation constraint in the learning process. Data noise of different mapping tasks is utilised to make the model uncertainty-aware, which adaptively weight different mapping tasks during learning. The method was examined on a dataset of 51 patients with non-alcoholic fatter liver disease. Results showed that the proposed method can produce comparable parametric maps to the traditional multi-contrast pixel wise fitting method, with a reduced number of images and less computation time. The uncertainty weighting also improves the model performance. It has the potential of accelerating MRI quantitative imaging.
Uncertainty-Aware Self-supervised Neural Network for Liver $T_{1ρ}$ Mapping with Relaxation Constraint
Jul 07, 2022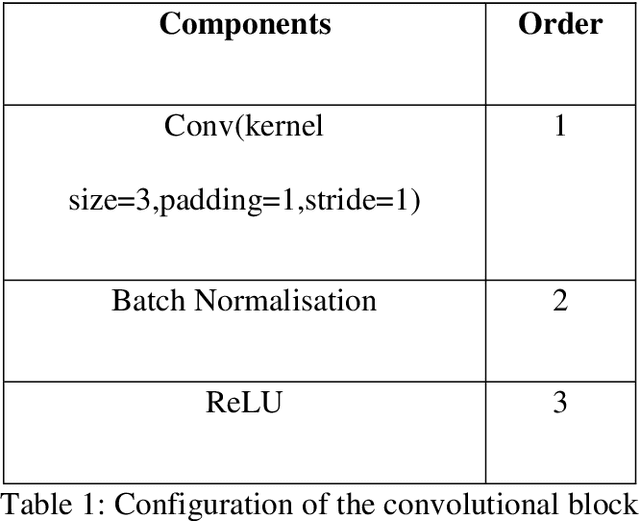

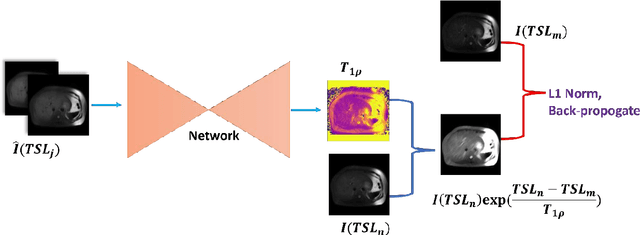
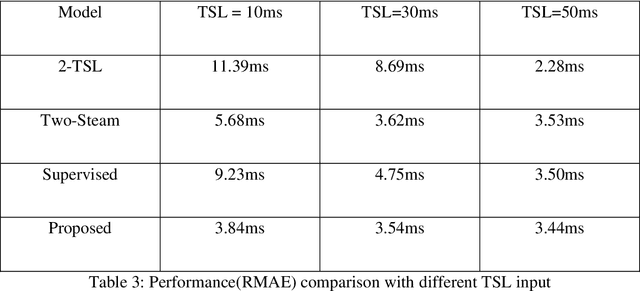
$T_{1\rho}$ mapping is a promising quantitative MRI technique for the non-invasive assessment of tissue properties. Learning-based approaches can map $T_{1\rho}$ from a reduced number of $T_{1\rho}$ weighted images, but requires significant amounts of high quality training data. Moreover, existing methods do not provide the confidence level of the $T_{1\rho}$ estimation. To address these problems, we proposed a self-supervised learning neural network that learns a $T_{1\rho}$ mapping using the relaxation constraint in the learning process. Epistemic uncertainty and aleatoric uncertainty are modelled for the $T_{1\rho}$ quantification network to provide a Bayesian confidence estimation of the $T_{1\rho}$ mapping. The uncertainty estimation can also regularize the model to prevent it from learning imperfect data. We conducted experiments on $T_{1\rho}$ data collected from 52 patients with non-alcoholic fatty liver disease. The results showed that our method outperformed the existing methods for $T_{1\rho}$ quantification of the liver using as few as two $T_{1\rho}$-weighted images. Our uncertainty estimation provided a feasible way of modelling the confidence of the self-supervised learning based $T_{1\rho}$ estimation, which is consistent with the reality in liver $T_{1\rho}$ imaging.
Event-based Timestamp Image Encoding Network for Human Action Recognition and Anticipation
Apr 13, 2021

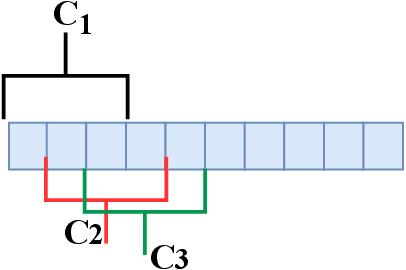
Event camera is an asynchronous, high frequency vision sensor with low power consumption, which is suitable for human action understanding task. It is vital to encode the spatial-temporal information of event data properly and use standard computer vision tool to learn from the data. In this work, we propose a timestamp image encoding 2D network, which takes the encoded spatial-temporal images with polarity information of the event data as input and output the action label. In addition, we propose a future timestamp image generator to generate futureaction information to aid the model to anticipate the human action when the action is not completed. Experiment results show that our method can achieve the same level of performance as those RGB-based benchmarks on real world action recognition,and also achieve the state of the art (SOTA) result on gesture recognition. Our future timestamp image generating model can effectively improve the prediction accuracy when the action is not completed. We also provide insight discussion on the importance of motion and appearance information in action recognition and anticipation.
Event-based Action Recognition Using Timestamp Image Encoding Network
Sep 28, 2020

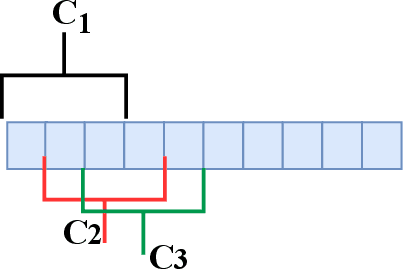
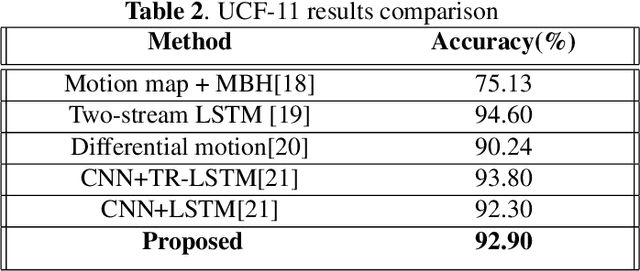
Event camera is an asynchronous, high frequency vision sensor with low power consumption, which is suitable for human action recognition task. It is vital to encode the spatial-temporal information of event data properly and use standard computer vision tool to learn from the data. In this work, we propose a timestamp image encoding 2D network, which takes the encoded spatial-temporal images of the event data as input and output the action label. Experiment results show that our method can achieve the same level of performance as those RGB-based benchmarks on real world action recognition, and also achieve the SOTA result on gesture recognition.
A Genetic Feature Selection Based Two-stream Neural Network for Anger Veracity Recognition
Sep 12, 2020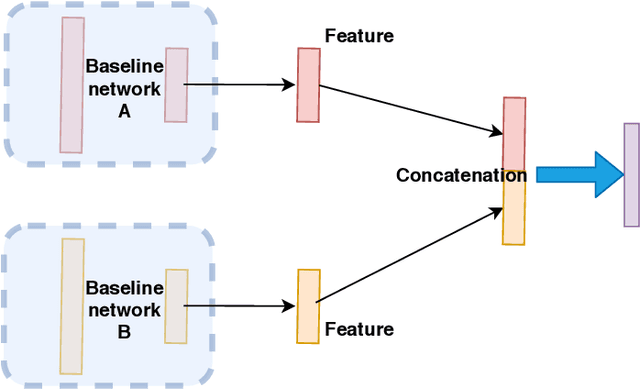

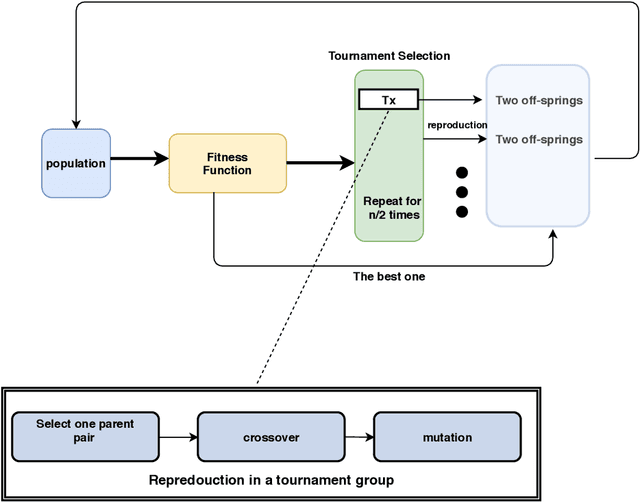

People can manipulate emotion expressions when interacting with others. For example, acted anger can be expressed when stimuli is not genuinely angry with an aim to manipulate the observer. In this paper, we aim to examine if the veracity of anger can be recognized with observers' pupillary data with computational approaches. We use Genetic-based Feature Selection (GFS) methods to select time-series pupillary features of of observers who observe acted and genuine anger of the video stimuli. We then use the selected features to train a simple fully connected neural work and a two-stream neural network. Our results show that the two-stream architecture is able to achieve a promising recognition result with an accuracy of 93.58% when the pupillary responses from both eyes are available. It also shows that genetic algorithm based feature selection method can effectively improve the classification accuracy by 3.07%. We hope our work could help daily research such as human machine interaction and psychology studies that require emotion recognition .