 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeGroup: Multi-Layer Depth Estimation of Transparent Surfaces via Self-Determined Grouping
May 27, 2026Transparent objects are common in daily life, and it is important to understand their multilayer depth, including the transparent surface and the objects behind it. Existing methods for multilayer depth typically extend single-layer prediction. They define layers by the front-to-back ordering of 3D points and predict the layers sequentially. However, as layered geometry can admit multiple valid groupings of 3D points into layers, a predefined grouping strategy is inherently restrictive. In this work, we propose SeeGroup, a multi-layer depth estimation method that avoids imposing a predefined grouping and allows the model itself to adaptively assign surfaces to depth maps. We formulate per-pixel multi-layer depth as a point process, treating depth layers as unordered events along each camera ray. This induces a permutation-invariant likelihood over the observed depth layers, yielding a loss that naturally supports arbitrary layer groupings. Experiments demonstrate that our method significantly advances the state of the art of multi-layer depth estimation, improving quadruplet relative depth accuracy on LayeredDepth benchmark from 61.34% to 70.09%. Code is available at https://github.com/princeton-vl/SeeGroup.
Zero-Shot Depth from Defocus
Mar 27, 2026Depth from Defocus (DfD) is the task of estimating a dense metric depth map from a focus stack. Unlike previous works overfitting to a certain dataset, this paper focuses on the challenging and practical setting of zero-shot generalization. We first propose a new real-world DfD benchmark ZEDD, which contains 8.3x more scenes and significantly higher quality images and ground-truth depth maps compared to previous benchmarks. We also design a novel network architecture named FOSSA. FOSSA is a Transformer-based architecture with novel designs tailored to the DfD task. The key contribution is a stack attention layer with a focus distance embedding, allowing efficient information exchange across the focus stack. Finally, we develop a new training data pipeline allowing us to utilize existing large-scale RGBD datasets to generate synthetic focus stacks. Experiment results on ZEDD and other benchmarks show a significant improvement over the baselines, reducing errors by up to 55.7%. The ZEDD benchmark is released at https://zedd.cs.princeton.edu. The code and checkpoints are released at https://github.com/princeton-vl/FOSSA.
Infinigen-Sim: Procedural Generation of Articulated Simulation Assets
May 19, 2025



We introduce Infinigen-Sim, a toolkit which enables users to create diverse and realistic articulated object procedural generators. These tools are composed of high-level utilities for use creating articulated assets in Blender, as well as an export pipeline to integrate the resulting assets into common robotics simulators. We demonstrate our system by creating procedural generators for 5 common articulated object categories. Experiments show that assets sampled from these generators are useful for movable object segmentation, training generalizable reinforcement learning policies, and sim-to-real transfer of imitation learning policies.
Seeing and Seeing Through the Glass: Real and Synthetic Data for Multi-Layer Depth Estimation
Mar 14, 2025Transparent objects are common in daily life, and understanding their multi-layer depth information -- perceiving both the transparent surface and the objects behind it -- is crucial for real-world applications that interact with transparent materials. In this paper, we introduce LayeredDepth, the first dataset with multi-layer depth annotations, including a real-world benchmark and a synthetic data generator, to support the task of multi-layer depth estimation. Our real-world benchmark consists of 1,500 images from diverse scenes, and evaluating state-of-the-art depth estimation methods on it reveals that they struggle with transparent objects. The synthetic data generator is fully procedural and capable of providing training data for this task with an unlimited variety of objects and scene compositions. Using this generator, we create a synthetic dataset with 15,300 images. Baseline models training solely on this synthetic dataset produce good cross-domain multi-layer depth estimation. Fine-tuning state-of-the-art single-layer depth models on it substantially improves their performance on transparent objects, with quadruplet accuracy on our benchmark increased from 55.14% to 75.20%. All images and validation annotations are available under CC0 at https://layereddepth.cs.princeton.edu.
AudioCIL: A Python Toolbox for Audio Class-Incremental Learning with Multiple Scenes
Dec 16, 2024Deep learning, with its robust aotomatic feature extraction capabilities, has demonstrated significant success in audio signal processing. Typically, these methods rely on static, pre-collected large-scale datasets for training, performing well on a fixed number of classes. However, the real world is characterized by constant change, with new audio classes emerging from streaming or temporary availability due to privacy. This dynamic nature of audio environments necessitates models that can incrementally learn new knowledge for new classes without discarding existing information. Introducing incremental learning to the field of audio signal processing, i.e., Audio Class-Incremental Learning (AuCIL), is a meaningful endeavor. We propose such a toolbox named AudioCIL to align audio signal processing algorithms with real-world scenarios and strengthen research in audio class-incremental learning.
LayeredFlow: A Real-World Benchmark for Non-Lambertian Multi-Layer Optical Flow
Sep 09, 2024



Achieving 3D understanding of non-Lambertian objects is an important task with many useful applications, but most existing algorithms struggle to deal with such objects. One major obstacle towards progress in this field is the lack of holistic non-Lambertian benchmarks -- most benchmarks have low scene and object diversity, and none provide multi-layer 3D annotations for objects occluded by transparent surfaces. In this paper, we introduce LayeredFlow, a real world benchmark containing multi-layer ground truth annotation for optical flow of non-Lambertian objects. Compared to previous benchmarks, our benchmark exhibits greater scene and object diversity, with 150k high quality optical flow and stereo pairs taken over 185 indoor and outdoor scenes and 360 unique objects. Using LayeredFlow as evaluation data, we propose a new task called multi-layer optical flow. To provide training data for this task, we introduce a large-scale densely-annotated synthetic dataset containing 60k images within 30 scenes tailored for non-Lambertian objects. Training on our synthetic dataset enables model to predict multi-layer optical flow, while fine-tuning existing optical flow methods on the dataset notably boosts their performance on non-Lambertian objects without compromising the performance on diffuse objects. Data is available at https://layeredflow.cs.princeton.edu.
Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation
Jun 17, 2024



We introduce Infinigen Indoors, a Blender-based procedural generator of photorealistic indoor scenes. It builds upon the existing Infinigen system, which focuses on natural scenes, but expands its coverage to indoor scenes by introducing a diverse library of procedural indoor assets, including furniture, architecture elements, appliances, and other day-to-day objects. It also introduces a constraint-based arrangement system, which consists of a domain-specific language for expressing diverse constraints on scene composition, and a solver that generates scene compositions that maximally satisfy the constraints. We provide an export tool that allows the generated 3D objects and scenes to be directly used for training embodied agents in real-time simulators such as Omniverse and Unreal. Infinigen Indoors is open-sourced under the BSD license. Please visit https://infinigen.org for code and videos.
Infinite Photorealistic Worlds using Procedural Generation
Jun 26, 2023
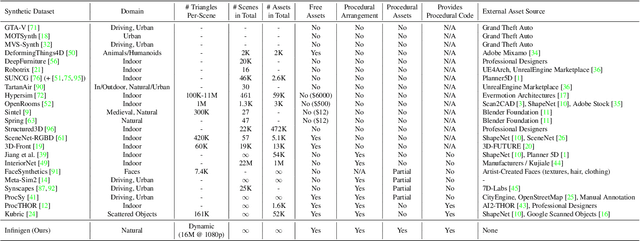


We introduce Infinigen, a procedural generator of photorealistic 3D scenes of the natural world. Infinigen is entirely procedural: every asset, from shape to texture, is generated from scratch via randomized mathematical rules, using no external source and allowing infinite variation and composition. Infinigen offers broad coverage of objects and scenes in the natural world including plants, animals, terrains, and natural phenomena such as fire, cloud, rain, and snow. Infinigen can be used to generate unlimited, diverse training data for a wide range of computer vision tasks including object detection, semantic segmentation, optical flow, and 3D reconstruction. We expect Infinigen to be a useful resource for computer vision research and beyond. Please visit https://infinigen.org for videos, code and pre-generated data.
ASFormer: Transformer for Action Segmentation
Oct 16, 2021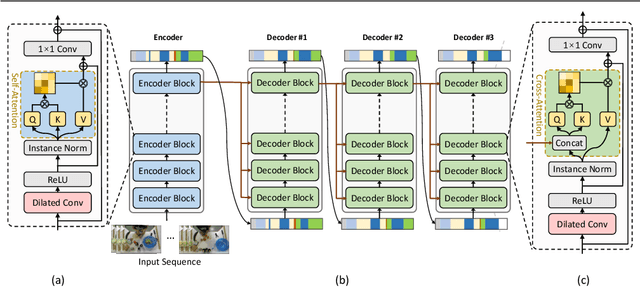


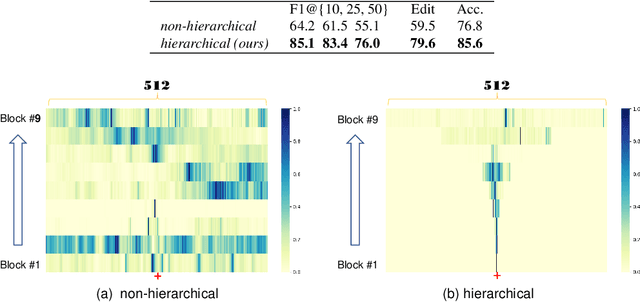
Algorithms for the action segmentation task typically use temporal models to predict what action is occurring at each frame for a minute-long daily activity. Recent studies have shown the potential of Transformer in modeling the relations among elements in sequential data. However, there are several major concerns when directly applying the Transformer to the action segmentation task, such as the lack of inductive biases with small training sets, the deficit in processing long input sequence, and the limitation of the decoder architecture to utilize temporal relations among multiple action segments to refine the initial predictions. To address these concerns, we design an efficient Transformer-based model for action segmentation task, named ASFormer, with three distinctive characteristics: (i) We explicitly bring in the local connectivity inductive priors because of the high locality of features. It constrains the hypothesis space within a reliable scope, and is beneficial for the action segmentation task to learn a proper target function with small training sets. (ii) We apply a pre-defined hierarchical representation pattern that efficiently handles long input sequences. (iii) We carefully design the decoder to refine the initial predictions from the encoder. Extensive experiments on three public datasets demonstrate that effectiveness of our methods. Code is available at \url{https://github.com/ChinaYi/ASFormer}.