 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Robustness of Monocular Depth Estimation with Procedural Scene Perturbations
Jul 01, 2025Recent years have witnessed substantial progress on monocular depth estimation, particularly as measured by the success of large models on standard benchmarks. However, performance on standard benchmarks does not offer a complete assessment, because most evaluate accuracy but not robustness. In this work, we introduce PDE (Procedural Depth Evaluation), a new benchmark which enables systematic robustness evaluation. PDE uses procedural generation to create 3D scenes that test robustness to various controlled perturbations, including object, camera, material and lighting changes. Our analysis yields interesting findings on what perturbations are challenging for state-of-the-art depth models, which we hope will inform further research. Code and data are available at https://github.com/princeton-vl/proc-depth-eval.
Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation
Jun 17, 2024



We introduce Infinigen Indoors, a Blender-based procedural generator of photorealistic indoor scenes. It builds upon the existing Infinigen system, which focuses on natural scenes, but expands its coverage to indoor scenes by introducing a diverse library of procedural indoor assets, including furniture, architecture elements, appliances, and other day-to-day objects. It also introduces a constraint-based arrangement system, which consists of a domain-specific language for expressing diverse constraints on scene composition, and a solver that generates scene compositions that maximally satisfy the constraints. We provide an export tool that allows the generated 3D objects and scenes to be directly used for training embodied agents in real-time simulators such as Omniverse and Unreal. Infinigen Indoors is open-sourced under the BSD license. Please visit https://infinigen.org for code and videos.
Infinite Photorealistic Worlds using Procedural Generation
Jun 26, 2023
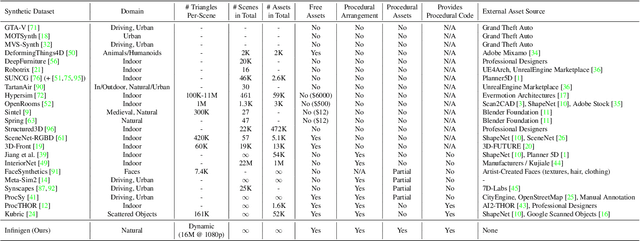


We introduce Infinigen, a procedural generator of photorealistic 3D scenes of the natural world. Infinigen is entirely procedural: every asset, from shape to texture, is generated from scratch via randomized mathematical rules, using no external source and allowing infinite variation and composition. Infinigen offers broad coverage of objects and scenes in the natural world including plants, animals, terrains, and natural phenomena such as fire, cloud, rain, and snow. Infinigen can be used to generate unlimited, diverse training data for a wide range of computer vision tasks including object detection, semantic segmentation, optical flow, and 3D reconstruction. We expect Infinigen to be a useful resource for computer vision research and beyond. Please visit https://infinigen.org for videos, code and pre-generated data.
FALCON: Fast Visual Concept Learning by Integrating Images, Linguistic descriptions, and Conceptual Relations
Mar 30, 2022
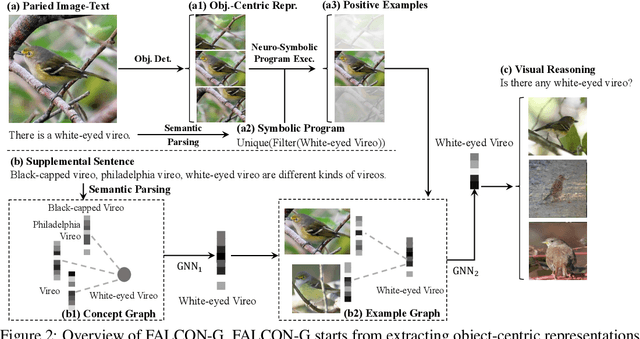
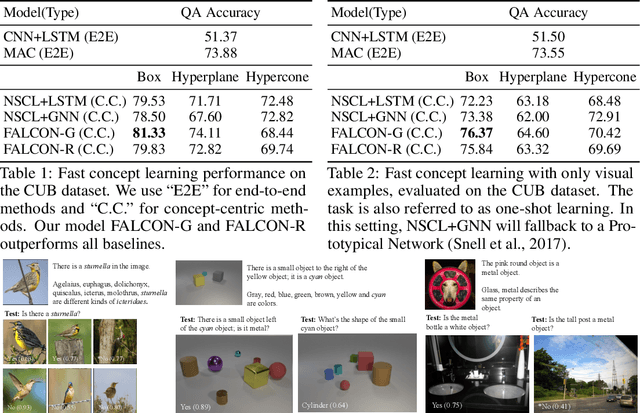
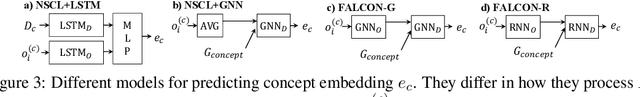
We present a meta-learning framework for learning new visual concepts quickly, from just one or a few examples, guided by multiple naturally occurring data streams: simultaneously looking at images, reading sentences that describe the objects in the scene, and interpreting supplemental sentences that relate the novel concept with other concepts. The learned concepts support downstream applications, such as answering questions by reasoning about unseen images. Our model, namely FALCON, represents individual visual concepts, such as colors and shapes, as axis-aligned boxes in a high-dimensional space (the "box embedding space"). Given an input image and its paired sentence, our model first resolves the referential expression in the sentence and associates the novel concept with particular objects in the scene. Next, our model interprets supplemental sentences to relate the novel concept with other known concepts, such as "X has property Y" or "X is a kind of Y". Finally, it infers an optimal box embedding for the novel concept that jointly 1) maximizes the likelihood of the observed instances in the image, and 2) satisfies the relationships between the novel concepts and the known ones. We demonstrate the effectiveness of our model on both synthetic and real-world datasets.