 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMotion: Concurrent Multi-person 3D Motion
Apr 16, 2025We introduce an approach for detecting and tracking detailed 3D poses of multiple people from a single monocular camera stream. Our system maintains temporally coherent predictions in crowded scenes filled with difficult poses and occlusions. Our model performs both strong per-frame detection and a learned pose update to track people from frame to frame. Rather than match detections across time, poses are updated directly from a new input image, which enables online tracking through occlusion. We train on numerous image and video datasets leveraging pseudo-labeled annotations to produce a model that matches state-of-the-art systems in 3D pose estimation accuracy while being faster and more accurate in tracking multiple people through time. Code and weights are provided at https://github.com/apple/ml-comotion
Deep Patch Visual SLAM
Aug 03, 2024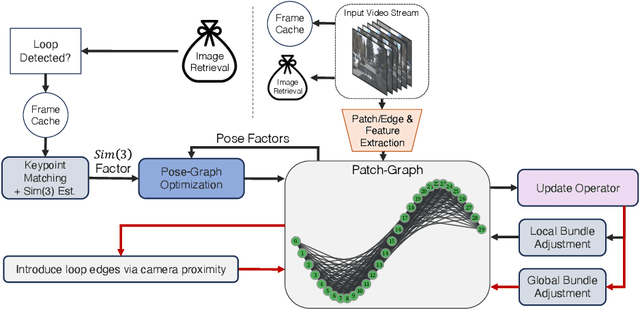
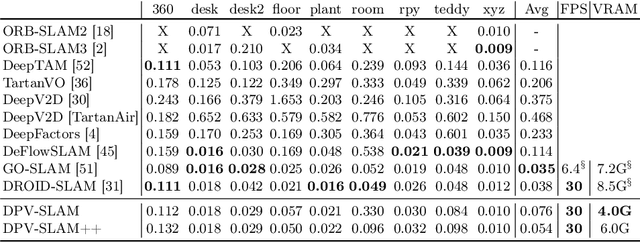
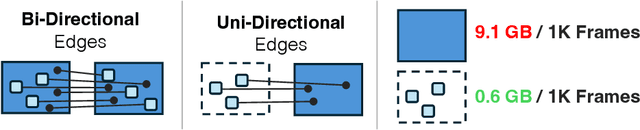
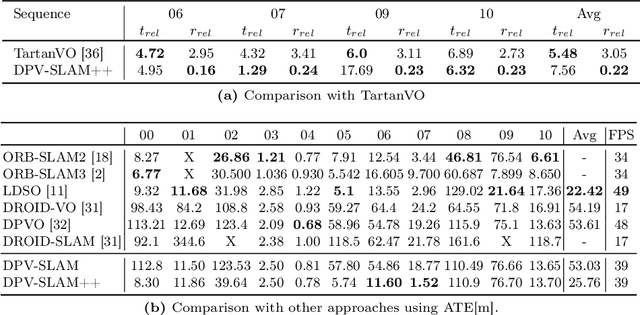
Recent work in visual SLAM has shown the effectiveness of using deep network backbones. Despite excellent accuracy, however, such approaches are often expensive to run or do not generalize well zero-shot. Their runtime can also fluctuate wildly while their frontend and backend fight for access to GPU resources. To address these problems, we introduce Deep Patch Visual (DPV) SLAM, a method for monocular visual SLAM on a single GPU. DPV-SLAM maintains a high minimum framerate and small memory overhead (5-7G) compared to existing deep SLAM systems. On real-world datasets, DPV-SLAM runs at 1x-4x real-time framerates. We achieve comparable accuracy to DROID-SLAM on EuRoC and TartanAir while running 2.5x faster using a fraction of the memory. DPV-SLAM is an extension to the DPVO visual odometry system; its code can be found in the same repository: https://github.com/princeton-vl/DPVO
Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation
Jun 17, 2024



We introduce Infinigen Indoors, a Blender-based procedural generator of photorealistic indoor scenes. It builds upon the existing Infinigen system, which focuses on natural scenes, but expands its coverage to indoor scenes by introducing a diverse library of procedural indoor assets, including furniture, architecture elements, appliances, and other day-to-day objects. It also introduces a constraint-based arrangement system, which consists of a domain-specific language for expressing diverse constraints on scene composition, and a solver that generates scene compositions that maximally satisfy the constraints. We provide an export tool that allows the generated 3D objects and scenes to be directly used for training embodied agents in real-time simulators such as Omniverse and Unreal. Infinigen Indoors is open-sourced under the BSD license. Please visit https://infinigen.org for code and videos.
SEA-RAFT: Simple, Efficient, Accurate RAFT for Optical Flow
May 23, 2024



We introduce SEA-RAFT, a more simple, efficient, and accurate RAFT for optical flow. Compared with RAFT, SEA-RAFT is trained with a new loss (mixture of Laplace). It directly regresses an initial flow for faster convergence in iterative refinements and introduces rigid-motion pre-training to improve generalization. SEA-RAFT achieves state-of-the-art accuracy on the Spring benchmark with a 3.69 endpoint-error (EPE) and a 0.36 1-pixel outlier rate (1px), representing 22.9% and 17.8% error reduction from best published results. In addition, SEA-RAFT obtains the best cross-dataset generalization on KITTI and Spring. With its high efficiency, SEA-RAFT operates at least 2.3x faster than existing methods while maintaining competitive performance. The code is publicly available at https://github.com/princeton-vl/SEA-RAFT.
Multi-Session SLAM with Differentiable Wide-Baseline Pose Optimization
Apr 23, 2024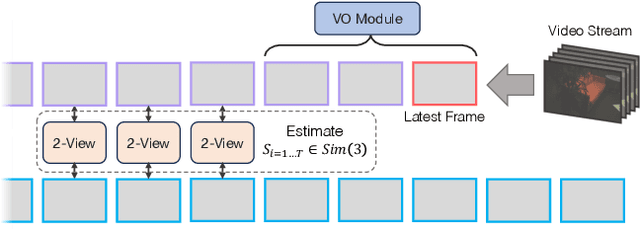

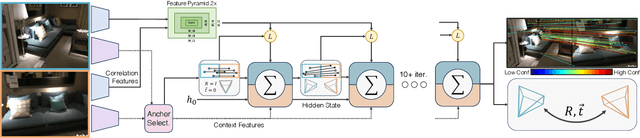

We introduce a new system for Multi-Session SLAM, which tracks camera motion across multiple disjoint videos under a single global reference. Our approach couples the prediction of optical flow with solver layers to estimate camera pose. The backbone is trained end-to-end using a novel differentiable solver for wide-baseline two-view pose. The full system can connect disjoint sequences, perform visual odometry, and global optimization. Compared to existing approaches, our design is accurate and robust to catastrophic failures. Code is available at github.com/princeton-vl/MultiSlam_DiffPose
View-Dependent Octree-based Mesh Extraction in Unbounded Scenes for Procedural Synthetic Data
Dec 13, 2023Procedural synthetic data generation has received increasing attention in computer vision. Procedural signed distance functions (SDFs) are a powerful tool for modeling large-scale detailed scenes, but existing mesh extraction methods have artifacts or performance profiles that limit their use for synthetic data. We propose OcMesher, a mesh extraction algorithm that efficiently handles high-detail unbounded scenes with perfect view-consistency, with easy export to downstream real-time engines. The main novelty of our solution is an algorithm to construct an octree based on a given SDF and multiple camera views. We performed extensive experiments, and show our solution produces better synthetic data for training and evaluation of computer vision models.
Infinite Photorealistic Worlds using Procedural Generation
Jun 26, 2023
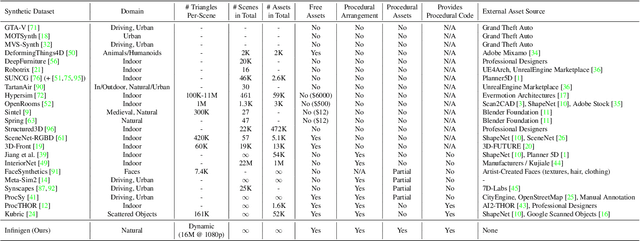


We introduce Infinigen, a procedural generator of photorealistic 3D scenes of the natural world. Infinigen is entirely procedural: every asset, from shape to texture, is generated from scratch via randomized mathematical rules, using no external source and allowing infinite variation and composition. Infinigen offers broad coverage of objects and scenes in the natural world including plants, animals, terrains, and natural phenomena such as fire, cloud, rain, and snow. Infinigen can be used to generate unlimited, diverse training data for a wide range of computer vision tasks including object detection, semantic segmentation, optical flow, and 3D reconstruction. We expect Infinigen to be a useful resource for computer vision research and beyond. Please visit https://infinigen.org for videos, code and pre-generated data.
Deep Patch Visual Odometry
Aug 08, 2022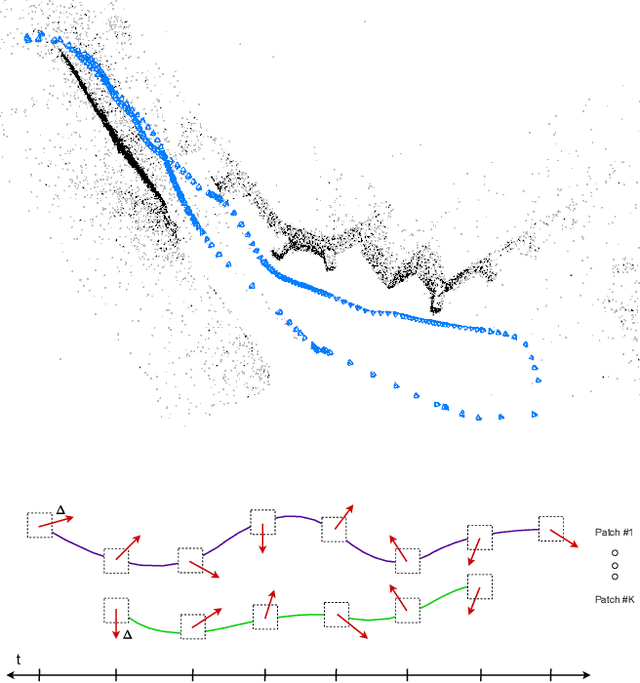
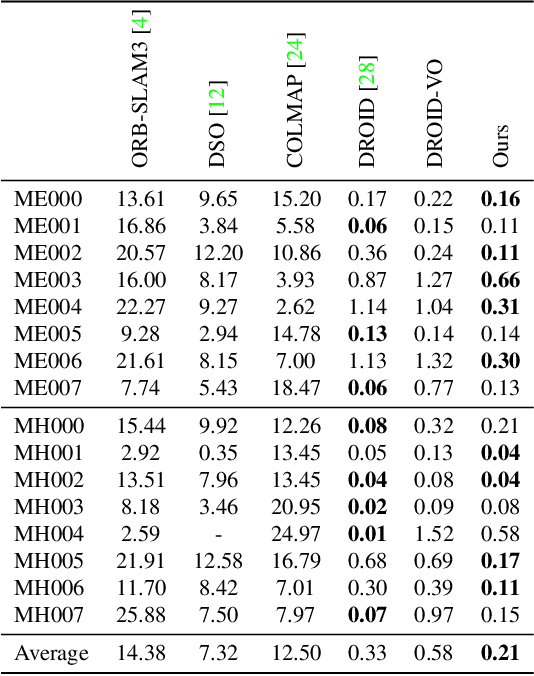
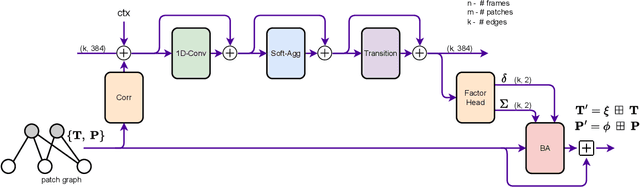
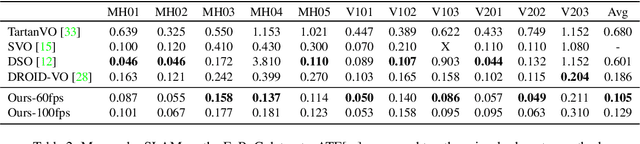
We propose Deep Patch Visual Odometry (DPVO), a new deep learning system for monocular Visual Odometry (VO). DPVO is accurate and robust while running at 2x-5x real-time speeds on a single RTX-3090 GPU using only 4GB of memory. We perform evaluation on standard benchmarks and outperform all prior work (classical or learned) in both accuracy and speed. Code is available at https://github.com/princeton-vl/DPVO.
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation
Apr 26, 2022
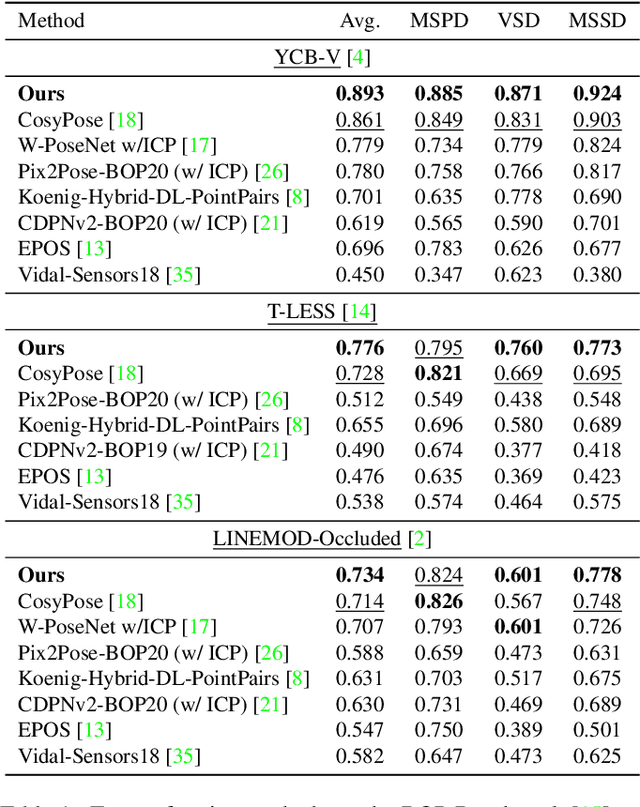
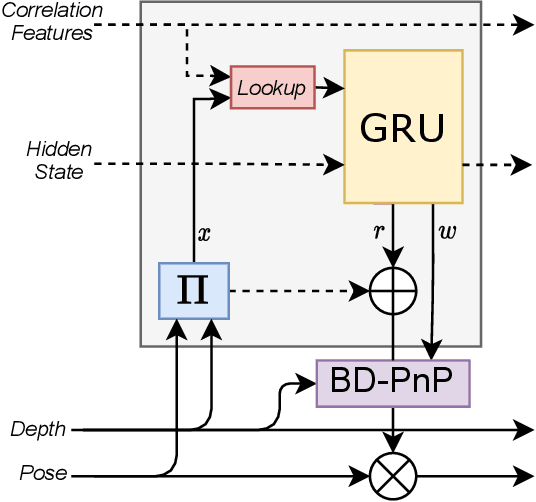
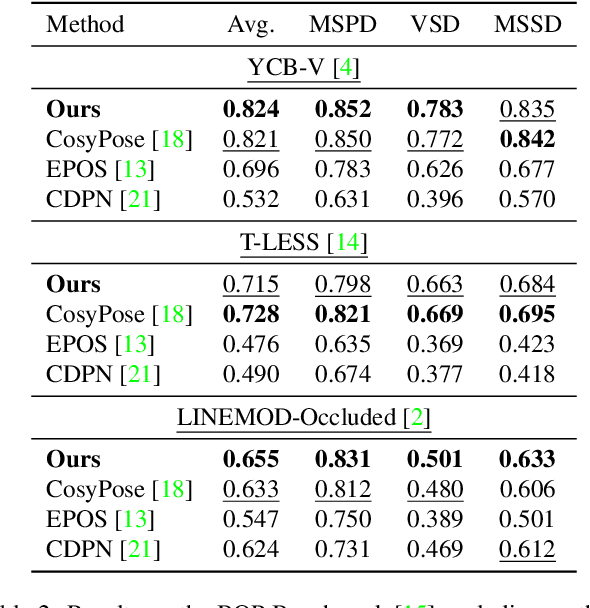
We address the task of 6D multi-object pose: given a set of known 3D objects and an RGB or RGB-D input image, we detect and estimate the 6D pose of each object. We propose a new approach to 6D object pose estimation which consists of an end-to-end differentiable architecture that makes use of geometric knowledge. Our approach iteratively refines both pose and correspondence in a tightly coupled manner, allowing us to dynamically remove outliers to improve accuracy. We use a novel differentiable layer to perform pose refinement by solving an optimization problem we refer to as Bidirectional Depth-Augmented Perspective-N-Point (BD-PnP). Our method achieves state-of-the-art accuracy on standard 6D Object Pose benchmarks. Code is available at https://github.com/princeton-vl/Coupled-Iterative-Refinement.
RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching
Sep 15, 2021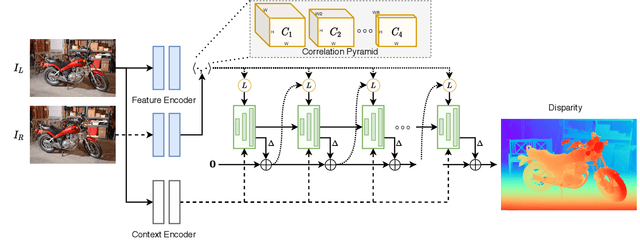
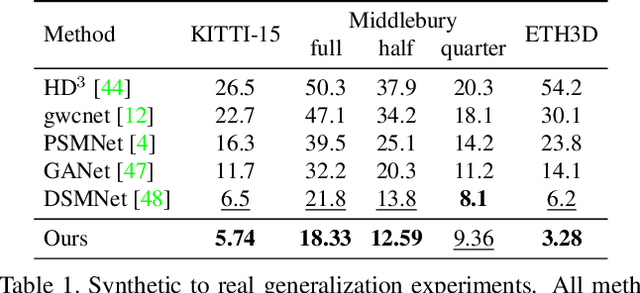
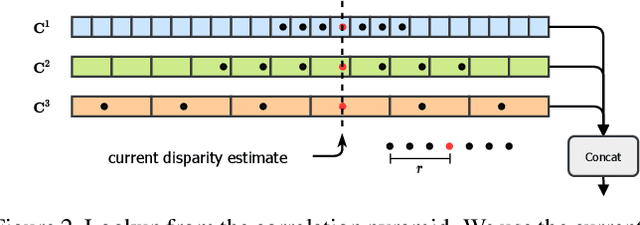
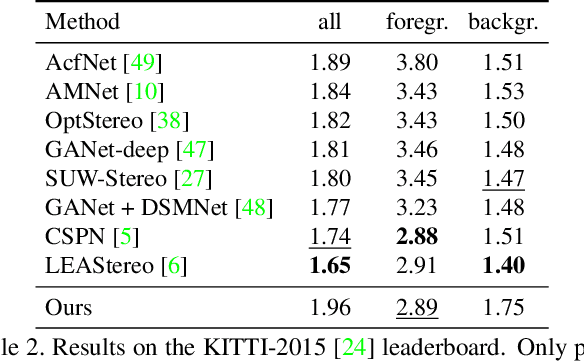
We introduce RAFT-Stereo, a new deep architecture for rectified stereo based on the optical flow network RAFT. We introduce multi-level convolutional GRUs, which more efficiently propagate information across the image. A modified version of RAFT-Stereo can perform accurate real-time inference. RAFT-stereo ranks first on the Middlebury leaderboard, outperforming the next best method on 1px error by 29% and outperforms all published work on the ETH3D two-view stereo benchmark. Code is available at https://github.com/princeton-vl/RAFT-Stereo.