 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Patch Visual SLAM
Aug 03, 2024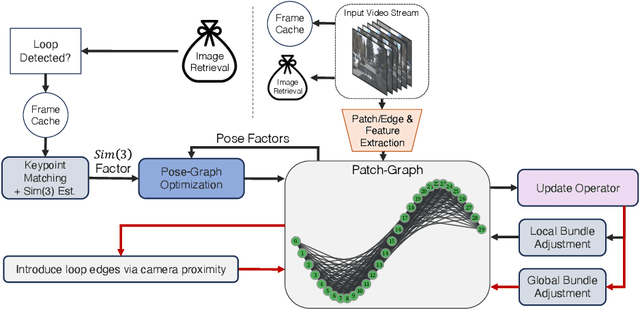
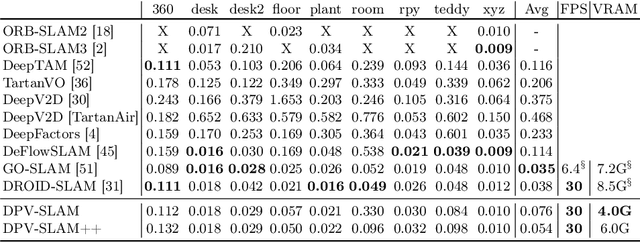
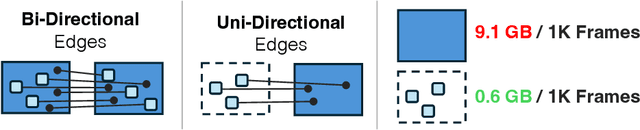
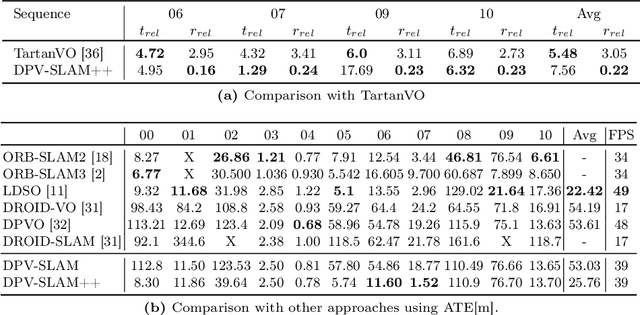
Recent work in visual SLAM has shown the effectiveness of using deep network backbones. Despite excellent accuracy, however, such approaches are often expensive to run or do not generalize well zero-shot. Their runtime can also fluctuate wildly while their frontend and backend fight for access to GPU resources. To address these problems, we introduce Deep Patch Visual (DPV) SLAM, a method for monocular visual SLAM on a single GPU. DPV-SLAM maintains a high minimum framerate and small memory overhead (5-7G) compared to existing deep SLAM systems. On real-world datasets, DPV-SLAM runs at 1x-4x real-time framerates. We achieve comparable accuracy to DROID-SLAM on EuRoC and TartanAir while running 2.5x faster using a fraction of the memory. DPV-SLAM is an extension to the DPVO visual odometry system; its code can be found in the same repository: https://github.com/princeton-vl/DPVO
Deep Patch Visual Odometry
Aug 08, 2022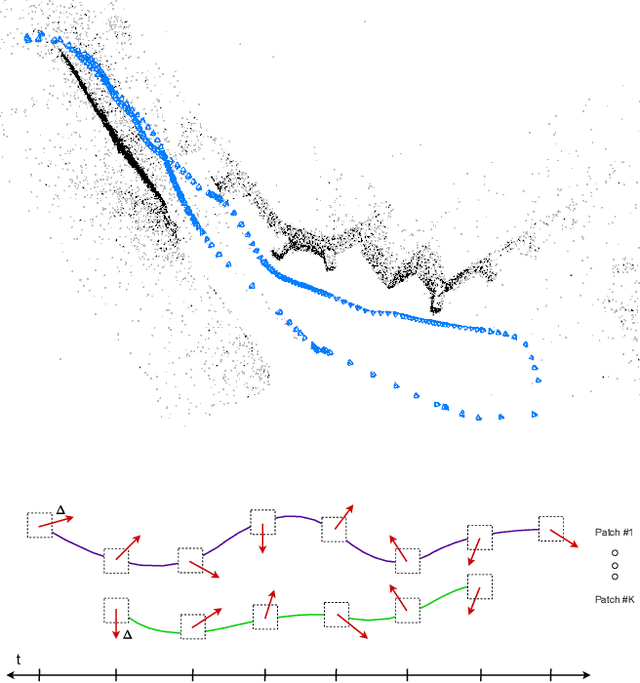
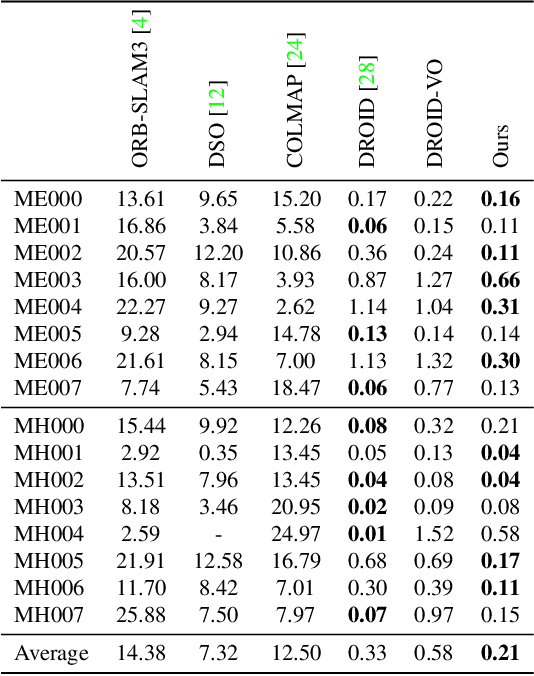
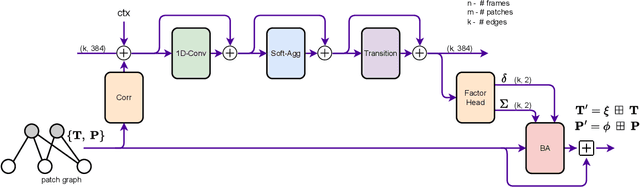
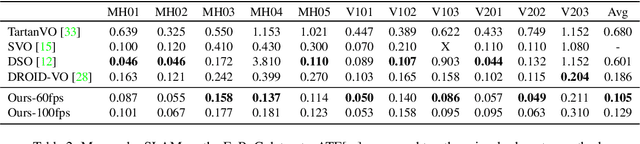
We propose Deep Patch Visual Odometry (DPVO), a new deep learning system for monocular Visual Odometry (VO). DPVO is accurate and robust while running at 2x-5x real-time speeds on a single RTX-3090 GPU using only 4GB of memory. We perform evaluation on standard benchmarks and outperform all prior work (classical or learned) in both accuracy and speed. Code is available at https://github.com/princeton-vl/DPVO.
Multiview Stereo with Cascaded Epipolar RAFT
May 09, 2022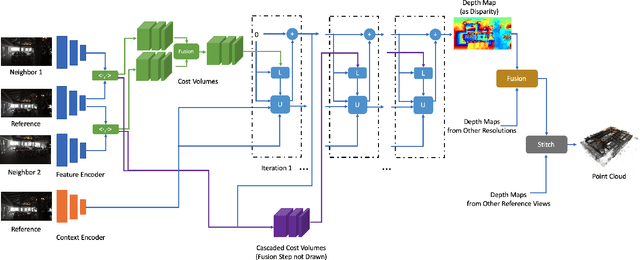
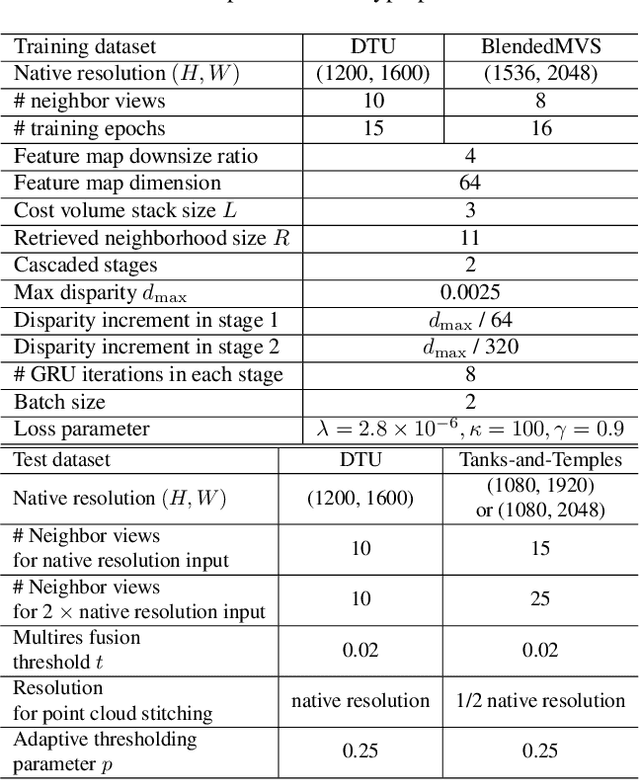
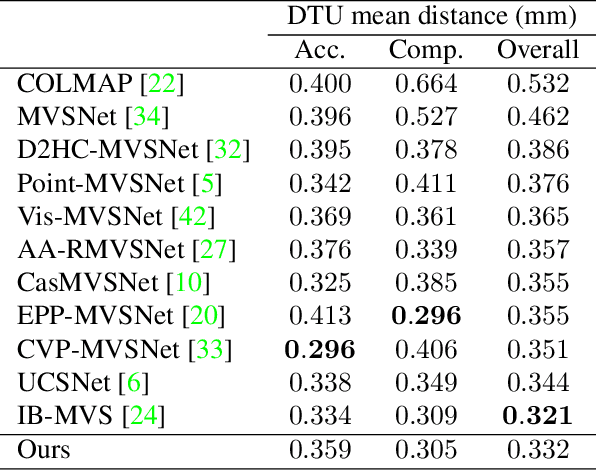

We address multiview stereo (MVS), an important 3D vision task that reconstructs a 3D model such as a dense point cloud from multiple calibrated images. We propose CER-MVS (Cascaded Epipolar RAFT Multiview Stereo), a new approach based on the RAFT (Recurrent All-Pairs Field Transforms) architecture developed for optical flow. CER-MVS introduces five new changes to RAFT: epipolar cost volumes, cost volume cascading, multiview fusion of cost volumes, dynamic supervision, and multiresolution fusion of depth maps. CER-MVS is significantly different from prior work in multiview stereo. Unlike prior work, which operates by updating a 3D cost volume, CER-MVS operates by updating a disparity field. Furthermore, we propose an adaptive thresholding method to balance the completeness and accuracy of the reconstructed point clouds. Experiments show that our approach achieves competitive performance on DTU (the second best among known results) and state-of-the-art performance on the Tanks-and-Temples benchmark (both the intermediate and advanced set). Code is available at https://github.com/princeton-vl/CER-MVS
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation
Apr 26, 2022
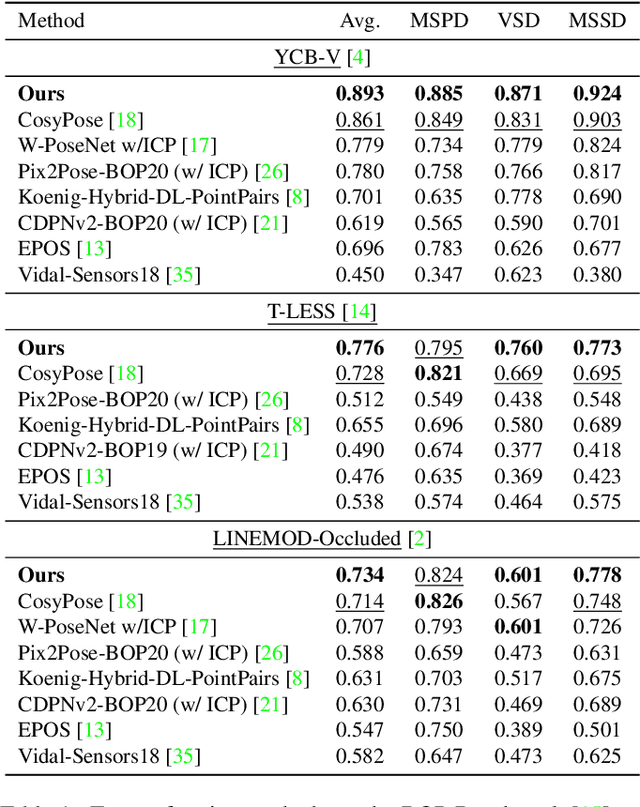
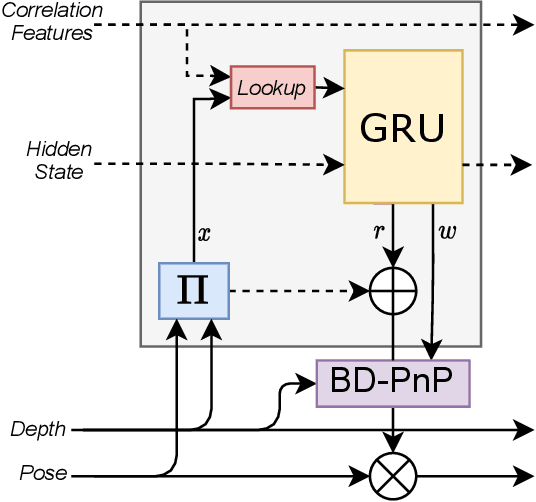
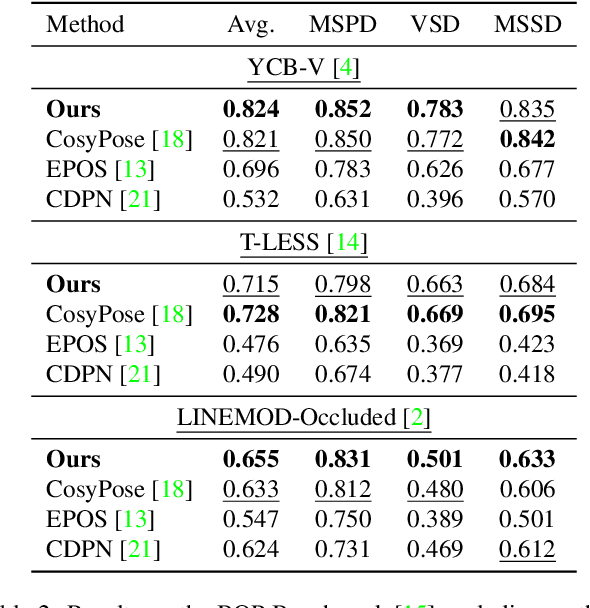
We address the task of 6D multi-object pose: given a set of known 3D objects and an RGB or RGB-D input image, we detect and estimate the 6D pose of each object. We propose a new approach to 6D object pose estimation which consists of an end-to-end differentiable architecture that makes use of geometric knowledge. Our approach iteratively refines both pose and correspondence in a tightly coupled manner, allowing us to dynamically remove outliers to improve accuracy. We use a novel differentiable layer to perform pose refinement by solving an optimization problem we refer to as Bidirectional Depth-Augmented Perspective-N-Point (BD-PnP). Our method achieves state-of-the-art accuracy on standard 6D Object Pose benchmarks. Code is available at https://github.com/princeton-vl/Coupled-Iterative-Refinement.
RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching
Sep 15, 2021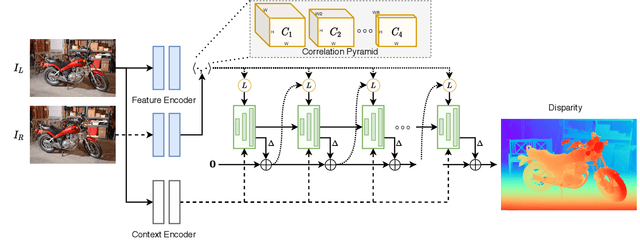
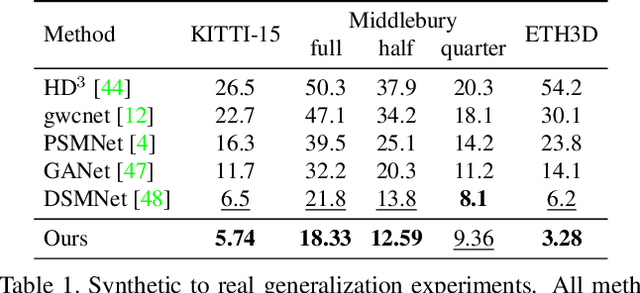
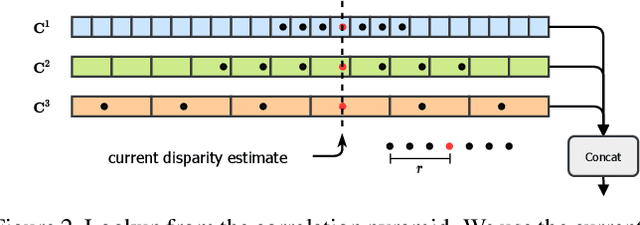
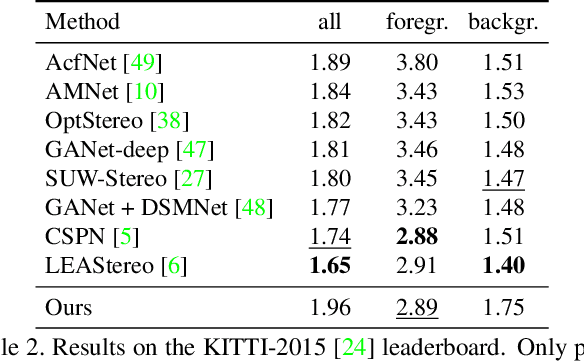
We introduce RAFT-Stereo, a new deep architecture for rectified stereo based on the optical flow network RAFT. We introduce multi-level convolutional GRUs, which more efficiently propagate information across the image. A modified version of RAFT-Stereo can perform accurate real-time inference. RAFT-stereo ranks first on the Middlebury leaderboard, outperforming the next best method on 1px error by 29% and outperforms all published work on the ETH3D two-view stereo benchmark. Code is available at https://github.com/princeton-vl/RAFT-Stereo.
DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras
Aug 24, 2021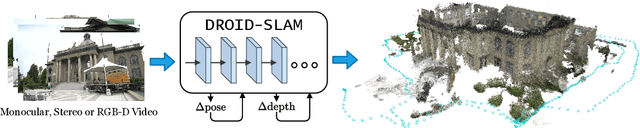

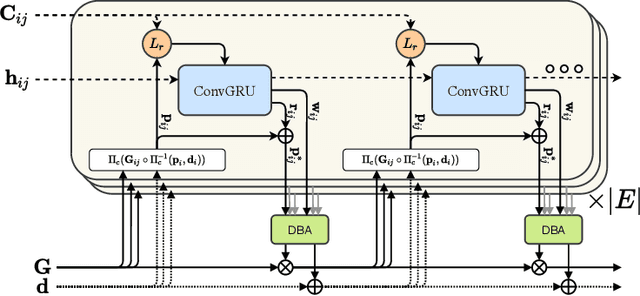

We introduce DROID-SLAM, a new deep learning based SLAM system. DROID-SLAM consists of recurrent iterative updates of camera pose and pixelwise depth through a Dense Bundle Adjustment layer. DROID-SLAM is accurate, achieving large improvements over prior work, and robust, suffering from substantially fewer catastrophic failures. Despite training on monocular video, it can leverage stereo or RGB-D video to achieve improved performance at test time. The URL to our open source code is https://github.com/princeton-vl/DROID-SLAM.
Tangent Space Backpropagation for 3D Transformation Groups
Mar 25, 2021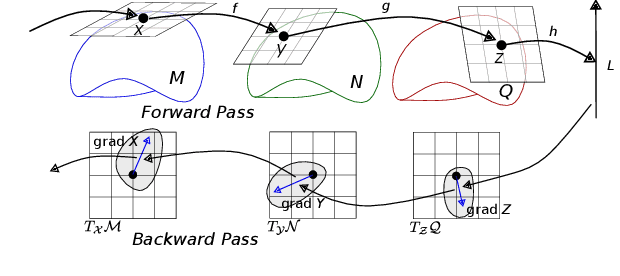


We address the problem of performing backpropagation for computation graphs involving 3D transformation groups SO(3), SE(3), and Sim(3). 3D transformation groups are widely used in 3D vision and robotics, but they do not form vector spaces and instead lie on smooth manifolds. The standard backpropagation approach, which embeds 3D transformations in Euclidean spaces, suffers from numerical difficulties. We introduce a new library, which exploits the group structure of 3D transformations and performs backpropagation in the tangent spaces of manifolds. We show that our approach is numerically more stable, easier to implement, and beneficial to a diverse set of tasks. Our plug-and-play PyTorch library is available at https://github.com/princeton-vl/lietorch.
RAFT-3D: Scene Flow using Rigid-Motion Embeddings
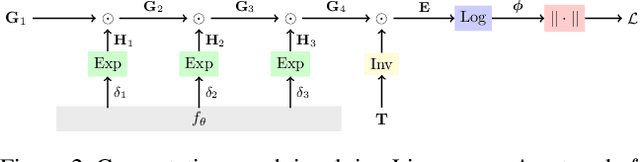
Dec 01, 2020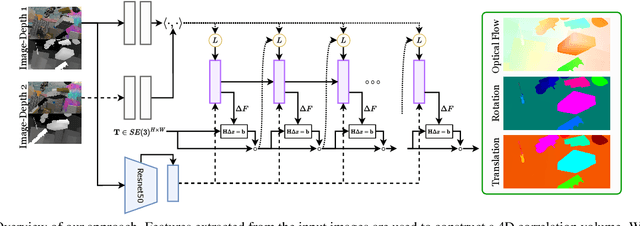


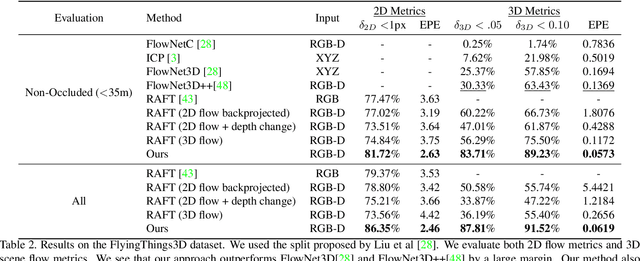
We address the problem of scene flow: given a pair of stereo or RGB-D video frames, estimate pixelwise 3D motion. We introduce RAFT-3D, a new deep architecture for scene flow. RAFT-3D is based on the RAFT model developed for optical flow but iteratively updates a dense field of pixelwise SE3 motion instead of 2D motion. A key innovation of RAFT-3D is rigid-motion embeddings, which represent a soft grouping of pixels into rigid objects. Integral to rigid-motion embeddings is Dense-SE3, a differentiable layer that enforces geometric consistency of the embeddings. Experiments show that RAFT-3D achieves state-of-the-art performance. On FlyingThings3D, under the two-view evaluation, we improved the best published accuracy (d < 0.05) from 30.33% to 83.71%. On KITTI, we achieve an error of 5.77, outperforming the best published method (6.31), despite using no object instance supervision.
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
Mar 26, 2020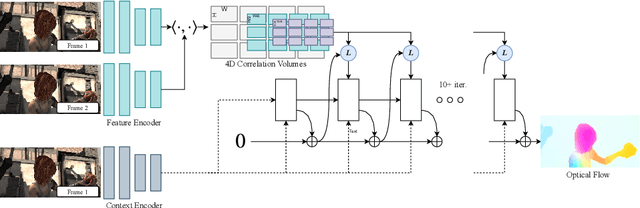
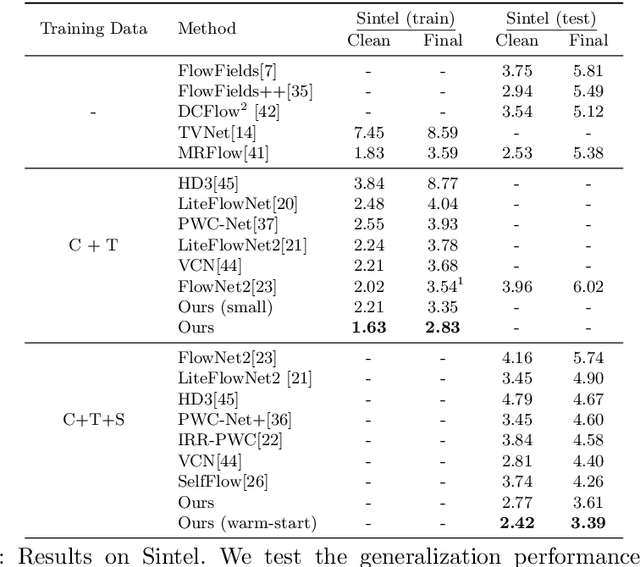
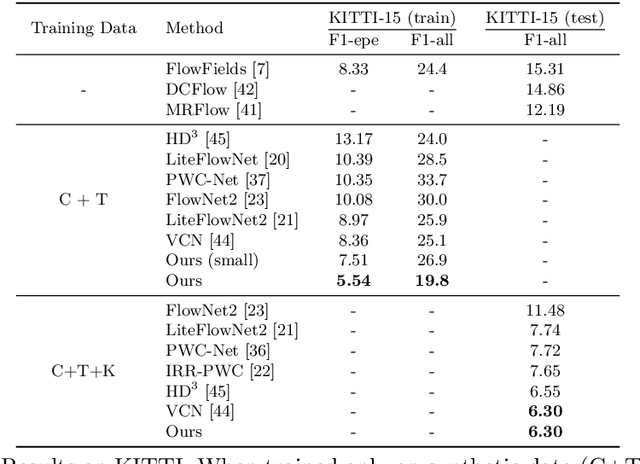
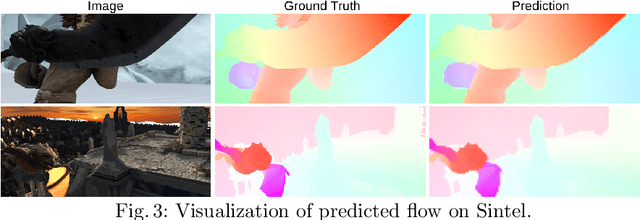
We introduce Recurrent All-Pairs Field Transforms (RAFT), a new deep network architecture for optical flow. RAFT extracts per-pixel features, builds multi-scale 4D correlation volumes for all pairs of pixels, and iteratively updates a flow field through a recurrent unit that performs lookups on the correlation volumes. RAFT achieves state-of-the-art performance, with strong cross-dataset generalization and high efficiency in inference time, training speed, and parameter count. Code is available \url{https://github.com/princeton-vl/RAFT}.
DeepV2D: Video to Depth with Differentiable Structure from Motion
Dec 11, 2018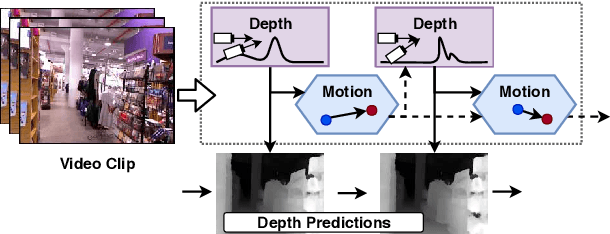
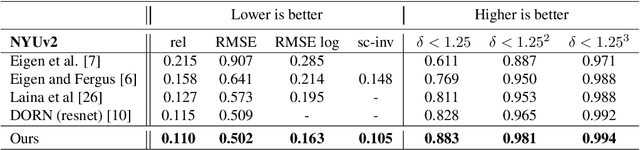
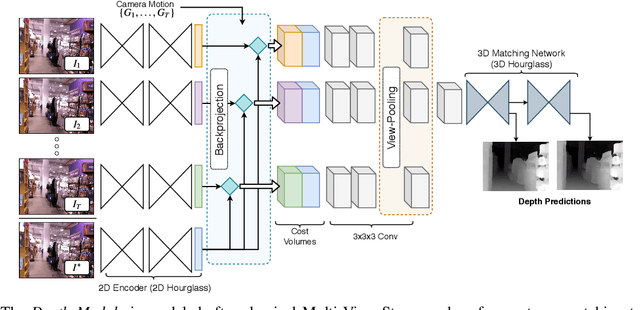
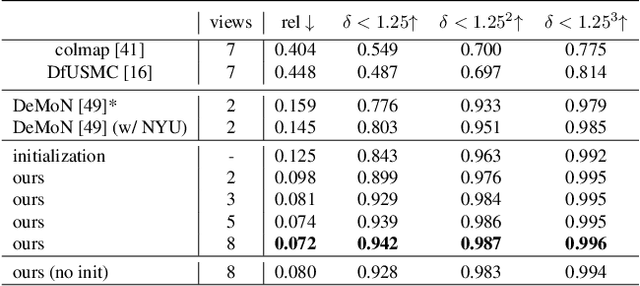
We propose DeepV2D, an end-to-end differentiable deep learning architecture for predicting depth from a video sequence. We incorporate elements of classical Structure from Motion into an end-to-end trainable pipeline by designing a set of differentiable geometric modules. Our full system alternates between predicting depth and refining camera pose. We estimate depth by building a cost volume over learned features and apply a multi-scale 3D convolutional network for stereo matching. The predicted depth is then sent to the motion module which performs iterative pose updates by mapping optical flow to a camera motion update. We evaluate our proposed system on NYU, KITTI, and SUN3D datasets and show improved results over monocular baselines and deep and classical stereo reconstruction.