 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepV2D: Video to Depth with Differentiable Structure from Motion
Paper and Code
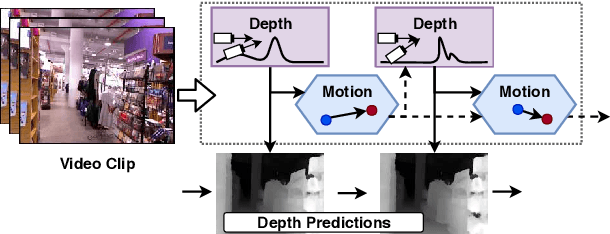
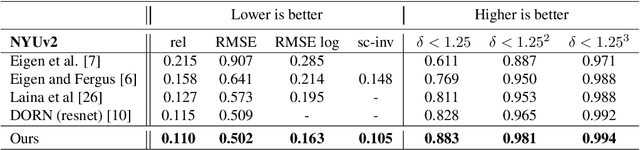
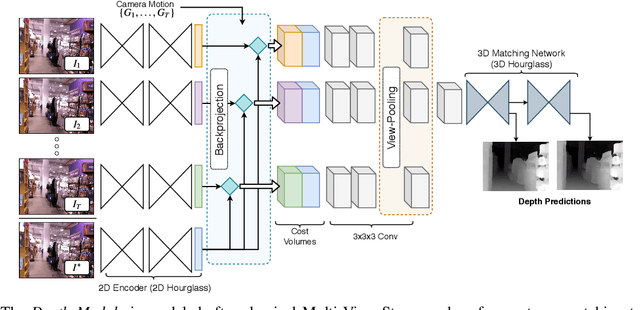
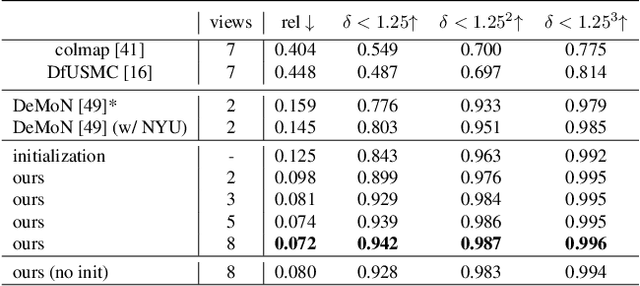
We propose DeepV2D, an end-to-end differentiable deep learning architecture for predicting depth from a video sequence. We incorporate elements of classical Structure from Motion into an end-to-end trainable pipeline by designing a set of differentiable geometric modules. Our full system alternates between predicting depth and refining camera pose. We estimate depth by building a cost volume over learned features and apply a multi-scale 3D convolutional network for stereo matching. The predicted depth is then sent to the motion module which performs iterative pose updates by mapping optical flow to a camera motion update. We evaluate our proposed system on NYU, KITTI, and SUN3D datasets and show improved results over monocular baselines and deep and classical stereo reconstruction.