 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMERIPPLE: Accelerating vDiTs by Understanding the Spatio-Temporal Correlations in Latent Space
Nov 15, 2025



The recent surge in video generation has shown the growing demand for high-quality video synthesis using large vision models. Existing video generation models are predominantly based on the video diffusion transformer (vDiT), however, they suffer from substantial inference delay due to self-attention. While prior studies have focused on reducing redundant computations in self-attention, they often overlook the inherent spatio-temporal correlations in video streams and directly leverage sparsity patterns from large language models to reduce attention computations. In this work, we take a principled approach to accelerate self-attention in vDiTs by leveraging the spatio-temporal correlations in the latent space. We show that the attention patterns within vDiT are primarily due to the dominant spatial and temporal correlations at the token channel level. Based on this insight, we propose a lightweight and adaptive reuse strategy that approximates attention computations by reusing partial attention scores of spatially or temporally correlated tokens along individual channels. We demonstrate that our method achieves significantly higher computational savings (85\%) compared to state-of-the-art techniques over 4 vDiTs, while preserving almost identical video quality ($<$0.06\% loss on VBench).
AudioCIL: A Python Toolbox for Audio Class-Incremental Learning with Multiple Scenes
Dec 16, 2024Deep learning, with its robust aotomatic feature extraction capabilities, has demonstrated significant success in audio signal processing. Typically, these methods rely on static, pre-collected large-scale datasets for training, performing well on a fixed number of classes. However, the real world is characterized by constant change, with new audio classes emerging from streaming or temporary availability due to privacy. This dynamic nature of audio environments necessitates models that can incrementally learn new knowledge for new classes without discarding existing information. Introducing incremental learning to the field of audio signal processing, i.e., Audio Class-Incremental Learning (AuCIL), is a meaningful endeavor. We propose such a toolbox named AudioCIL to align audio signal processing algorithms with real-world scenarios and strengthen research in audio class-incremental learning.
Convolutional Dictionary Pair Learning Network for Image Representation Learning
Jan 15, 2020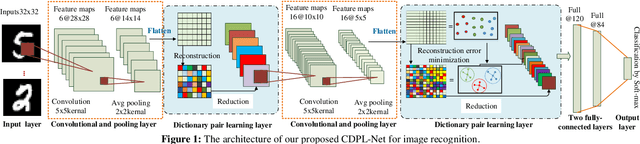
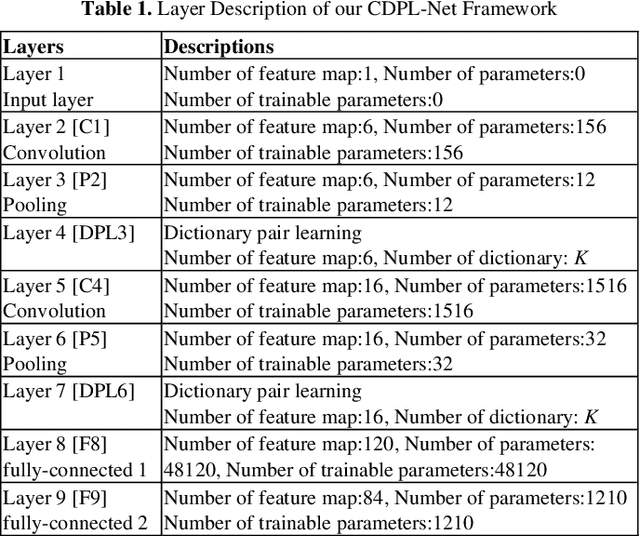
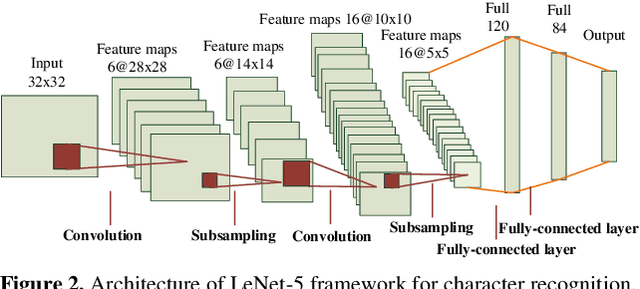
Both the Dictionary Learning (DL) and Convolutional Neural Networks (CNN) are powerful image representation learning systems based on different mechanisms and principles, however whether we can seamlessly integrate them to improve the per-formance is noteworthy exploring. To address this issue, we propose a novel generalized end-to-end representation learning architecture, dubbed Convolutional Dictionary Pair Learning Network (CDPL-Net) in this paper, which integrates the learning schemes of the CNN and dictionary pair learning into a unified framework. Generally, the architecture of CDPL-Net includes two convolutional/pooling layers and two dictionary pair learn-ing (DPL) layers in the representation learning module. Besides, it uses two fully-connected layers as the multi-layer perception layer in the nonlinear classification module. In particular, the DPL layer can jointly formulate the discriminative synthesis and analysis representations driven by minimizing the batch based reconstruction error over the flatted feature maps from the convolution/pooling layer. Moreover, DPL layer uses l1-norm on the analysis dictionary so that sparse representation can be delivered, and the embedding process will also be robust to noise. To speed up the training process of DPL layer, the efficient stochastic gradient descent is used. Extensive simulations on real databases show that our CDPL-Net can deliver enhanced performance over other state-of-the-art methods.
Discriminative Local Sparse Representation by Robust Adaptive Dictionary Pair Learning
Nov 20, 2019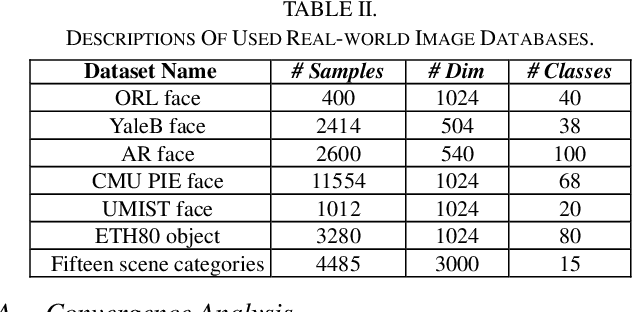
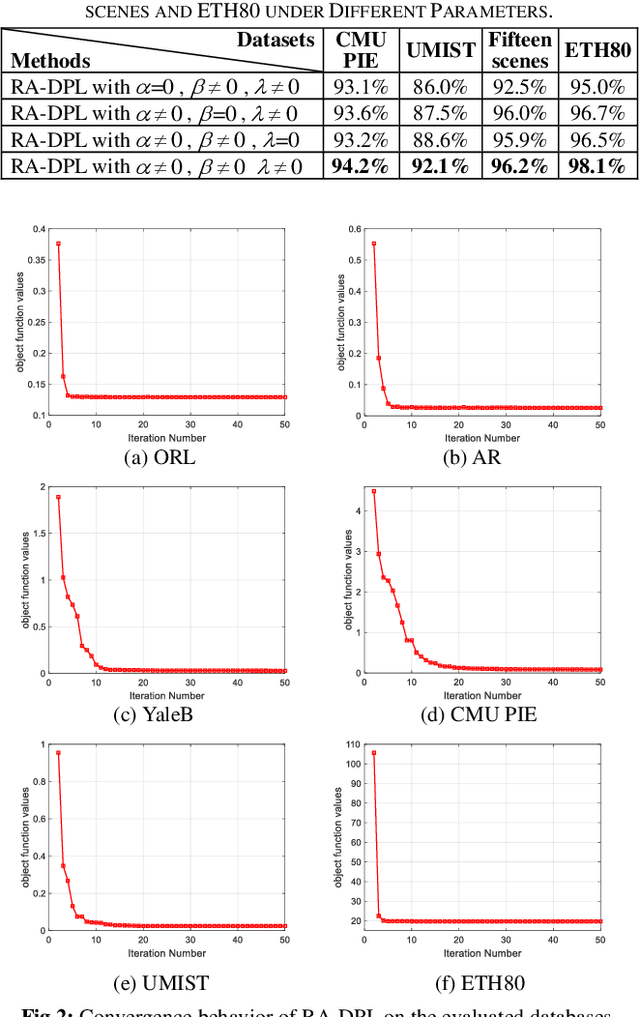

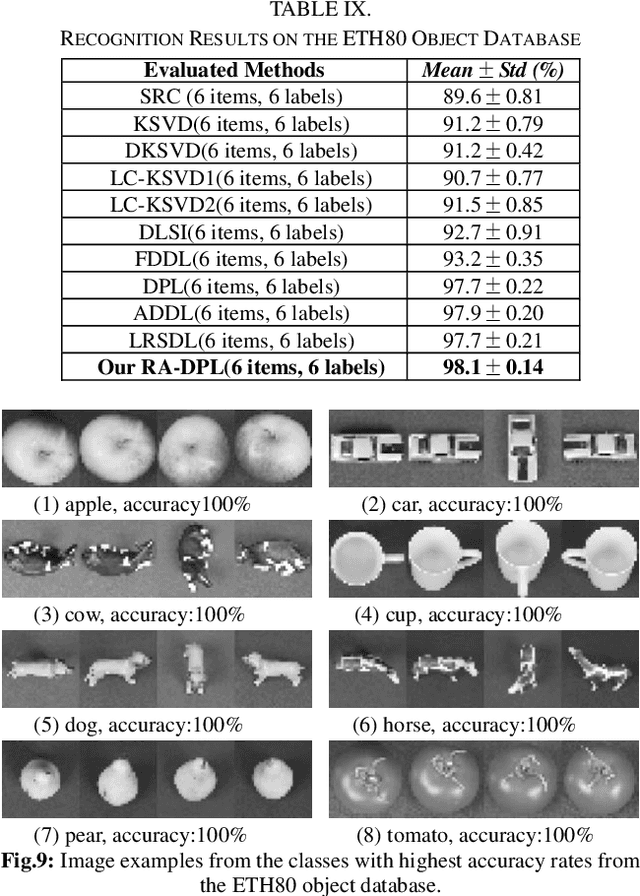
In this paper, we propose a structured Robust Adaptive Dic-tionary Pair Learning (RA-DPL) framework for the discrim-inative sparse representation learning. To achieve powerful representation ability of the available samples, the setting of RA-DPL seamlessly integrates the robust projective dictionary pair learning, locality-adaptive sparse representations and discriminative coding coefficients learning into a unified learning framework. Specifically, RA-DPL improves existing projective dictionary pair learning in four perspectives. First, it applies a sparse l2,1-norm based metric to encode the recon-struction error to deliver the robust projective dictionary pairs, and the l2,1-norm has the potential to minimize the error. Sec-ond, it imposes the robust l2,1-norm clearly on the analysis dictionary to ensure the sparse property of the coding coeffi-cients rather than using the costly l0/l1-norm. As such, the robustness of the data representation and the efficiency of the learning process are jointly considered to guarantee the effi-cacy of our RA-DPL. Third, RA-DPL conceives a structured reconstruction weight learning paradigm to preserve the local structures of the coding coefficients within each class clearly in an adaptive manner, which encourages to produce the locality preserving representations. Fourth, it also considers improving the discriminating ability of coding coefficients and dictionary by incorporating a discriminating function, which can ensure high intra-class compactness and inter-class separation in the code space. Extensive experiments show that our RA-DPL can obtain superior performance over other state-of-the-arts.
Learning Structured Twin-Incoherent Twin-Projective Latent Dictionary Pairs for Classification
Aug 21, 2019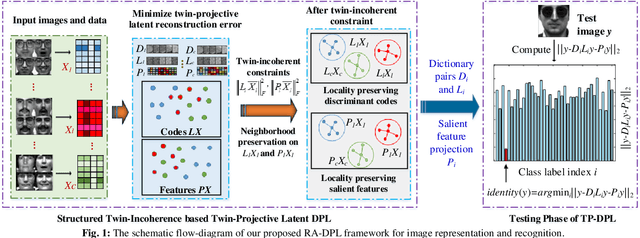
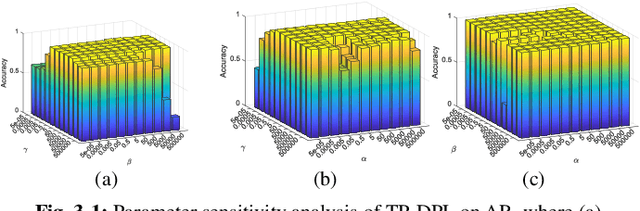
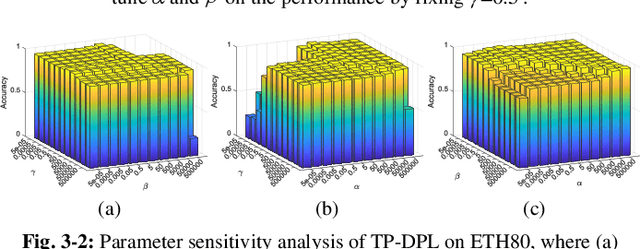

In this paper, we extend the popular dictionary pair learning (DPL) into the scenario of twin-projective latent flexible DPL under a structured twin-incoherence. Technically, a novel framework called Twin-Projective Latent Flexible DPL (TP-DPL) is proposed, which minimizes the twin-incoherence constrained flexibly-relaxed reconstruction error to avoid the possible over-fitting issue and produce accurate reconstruction. In this setting, our TP-DPL integrates the twin-incoherence based latent flexible DPL and the joint embedding of codes as well as salient features by twin-projection into a unified model in an adaptive neighborhood-preserving manner. As a result, TP-DPL unifies the salient feature extraction, representation and classification. The twin-incoherence constraint on codes and features can explicitly ensure high intra-class compactness and inter-class separation over them. TP-DPL also integrates the adaptive weighting to preserve the local neighborhood of the coefficients and salient features within each class explicitly. For efficiency, TP-DPL uses Frobenius-norm and abandons the costly l0/l1-norm for group sparse representation. Another byproduct is that TP-DPL can directly apply the class-specific twin-projective reconstruction residual to compute the label of data. Extensive results on public databases show that TP-DPL can deliver the state-of-the-art performance.