 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Empirical Compute-Supervision Tradeoffs in RLVR
May 27, 2026Reinforcement learning with verifiable rewards (RLVR) has become a standard paradigm for post-training language models, but in practice, verifiers are rarely perfect. Recent theoretical work predicts that verifier noise affects the rate of learning but not its final outcome, implying that sufficient compute should close any gap induced by imperfect supervision. We test this prediction empirically by post-training Qwen2.5 (0.5B, 1.5B) with GRPO on GSM8K while injecting controlled false-positive and false-negative noise into the binary correctness signal, and varying rollouts per prompt as a compute axis. In practice, the gap in validation accuracy persists under substantial compute scaling, with returns to compute that are sharply diminishing. We further find a structural asymmetry where false negatives monotonically degrade performance more quickly than false positives. These findings suggest verifier quality and training compute are not interchangeable, and that reducing false negatives is a more effective lever than scaling compute alone.
Zero-Shot Depth from Defocus
Mar 27, 2026Depth from Defocus (DfD) is the task of estimating a dense metric depth map from a focus stack. Unlike previous works overfitting to a certain dataset, this paper focuses on the challenging and practical setting of zero-shot generalization. We first propose a new real-world DfD benchmark ZEDD, which contains 8.3x more scenes and significantly higher quality images and ground-truth depth maps compared to previous benchmarks. We also design a novel network architecture named FOSSA. FOSSA is a Transformer-based architecture with novel designs tailored to the DfD task. The key contribution is a stack attention layer with a focus distance embedding, allowing efficient information exchange across the focus stack. Finally, we develop a new training data pipeline allowing us to utilize existing large-scale RGBD datasets to generate synthetic focus stacks. Experiment results on ZEDD and other benchmarks show a significant improvement over the baselines, reducing errors by up to 55.7%. The ZEDD benchmark is released at https://zedd.cs.princeton.edu. The code and checkpoints are released at https://github.com/princeton-vl/FOSSA.
Static Scene Reconstruction from Dynamic Egocentric Videos
Mar 23, 2026Egocentric videos present unique challenges for 3D reconstruction due to rapid camera motion and frequent dynamic interactions. State-of-the-art static reconstruction systems, such as MapAnything, often degrade in these settings, suffering from catastrophic trajectory drift and "ghost" geometry caused by moving hands. We bridge this gap by proposing a robust pipeline that adapts static reconstruction backbones to long-form egocentric video. Our approach introduces a mask-aware reconstruction mechanism that explicitly suppresses dynamic foreground in the attention layers, preventing hand artifacts from contaminating the static map. Furthermore, we employ a chunked reconstruction strategy with pose-graph stitching to ensure global consistency and eliminate long-term drift. Experiments on HD-EPIC and indoor drone datasets demonstrate that our pipeline significantly improves absolute trajectory error and yields visually clean static geometry compared to naive baselines, effectively extending the capability of foundation models to dynamic first-person scenes.
Seeing and Seeing Through the Glass: Real and Synthetic Data for Multi-Layer Depth Estimation
Mar 14, 2025Transparent objects are common in daily life, and understanding their multi-layer depth information -- perceiving both the transparent surface and the objects behind it -- is crucial for real-world applications that interact with transparent materials. In this paper, we introduce LayeredDepth, the first dataset with multi-layer depth annotations, including a real-world benchmark and a synthetic data generator, to support the task of multi-layer depth estimation. Our real-world benchmark consists of 1,500 images from diverse scenes, and evaluating state-of-the-art depth estimation methods on it reveals that they struggle with transparent objects. The synthetic data generator is fully procedural and capable of providing training data for this task with an unlimited variety of objects and scene compositions. Using this generator, we create a synthetic dataset with 15,300 images. Baseline models training solely on this synthetic dataset produce good cross-domain multi-layer depth estimation. Fine-tuning state-of-the-art single-layer depth models on it substantially improves their performance on transparent objects, with quadruplet accuracy on our benchmark increased from 55.14% to 75.20%. All images and validation annotations are available under CC0 at https://layereddepth.cs.princeton.edu.
Fast and Accurate Factual Inconsistency Detection Over Long Documents
Oct 23, 2023Generative AI models exhibit remarkable potential; however, hallucinations across various tasks present a significant challenge, particularly for longer inputs that current approaches struggle to address effectively. We introduce SCALE (Source Chunking Approach for Large-scale inconsistency Evaluation), a task-agnostic model for detecting factual inconsistencies using a novel chunking strategy. Specifically, SCALE is a Natural Language Inference (NLI) based model that uses large text chunks to condition over long texts. This approach achieves state-of-the-art performance in factual inconsistency detection for diverse tasks and long inputs. Additionally, we leverage the chunking mechanism and employ a novel algorithm to explain SCALE's decisions through relevant source sentence retrieval. Our evaluations reveal that SCALE outperforms existing methods on both standard benchmarks and a new long-form dialogue dataset ScreenEval we constructed. Moreover, SCALE surpasses competitive systems in efficiency and model explanation evaluations. We have released our code and data publicly to GitHub.
Sign-OPT: A Query-Efficient Hard-label Adversarial Attack
Sep 28, 2019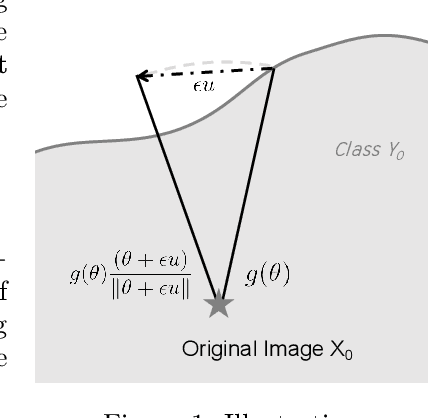
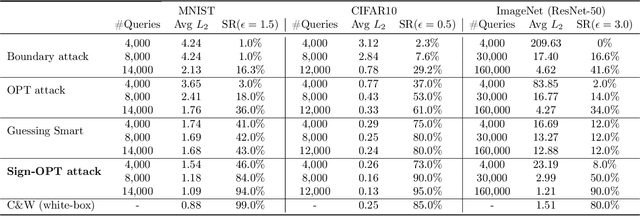

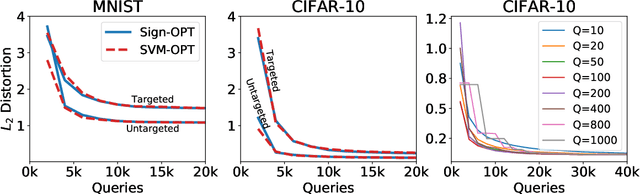
We study the most practical problem setup for evaluating adversarial robustness of a machine learning system with limited access: the hard-label black-box attack setting for generating adversarial examples, where limited model queries are allowed and only the decision is provided to a queried data input. Several algorithms have been proposed for this problem but they typically require huge amount (>20,000) of queries for attacking one example. Among them, one of the state-of-the-art approaches (Cheng et al., 2019) showed that hard-label attack can be modeled as an optimization problem where the objective function can be evaluated by binary search with additional model queries, thereby a zeroth order optimization algorithm can be applied. In this paper, we adopt the same optimization formulation but propose to directly estimate the sign of gradient at any direction instead of the gradient itself, which enjoys the benefit of single query. Using this single query oracle for retrieving sign of directional derivative, we develop a novel query-efficient Sign-OPT approach for hard-label black-box attack. We provide a convergence analysis of the new algorithm and conduct experiments on several models on MNIST, CIFAR-10 and ImageNet. We find that Sign-OPT attack consistently requires 5X to 10X fewer queries when compared to the current state-of-the-art approaches, and usually converges to an adversarial example with smaller perturbation.