 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Exploration via Temporal Inconsistency in Reinforcement Learning
Aug 24, 2022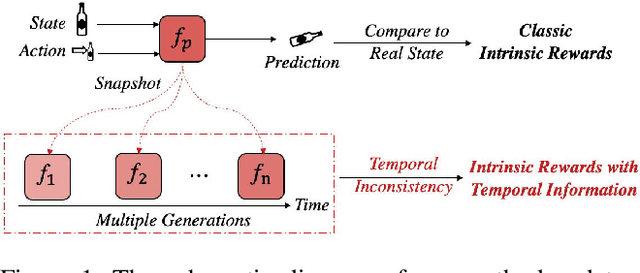
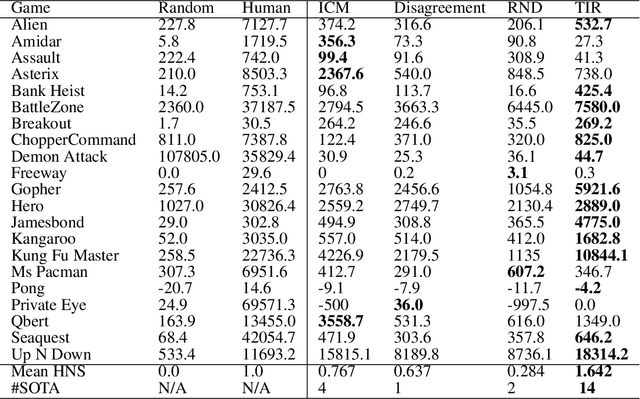
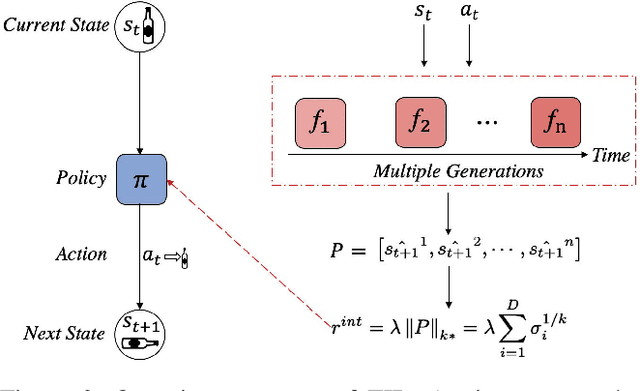

In real-world scenarios, reinforcement learning under sparse-reward synergistic settings has remained challenging, despite surging interests in this field. Previous attempts suggest that intrinsic reward can alleviate the issue caused by sparsity. In this paper, we present a novel intrinsic reward that is inspired by human learning, as humans evaluate curiosity by comparing current observations with historical knowledge. Specifically, we train a self-supervised prediction model and save a set of snapshots of the model parameters, without incurring addition training cost. Then we employ nuclear norm to evaluate the temporal inconsistency between the predictions of different snapshots, which can be further deployed as the intrinsic reward. Moreover, a variational weighting mechanism is proposed to assign weight to different snapshots in an adaptive manner. We demonstrate the efficacy of the proposed method in various benchmark environments. The results suggest that our method can provide overwhelming state-of-the-art performance compared with other intrinsic reward-based methods, without incurring additional training costs and maintaining higher noise tolerance. Our code will be released publicly to enhance reproducibility.