 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Sensitive Information Leakage in LLMs4Code through Machine Unlearning
Feb 09, 2025



Large Language Models for Code (LLMs4Code) excel at code generation tasks, yielding promise to release developers from huge software development burdens. Nonetheless, these models have been shown to suffer from the significant privacy risks due to the potential leakage of sensitive information embedded during training, known as the memorization problem. Addressing this issue is crucial for ensuring privacy compliance and upholding user trust, but till now there is a dearth of dedicated studies in the literature that focus on this specific direction. Recently, machine unlearning has emerged as a promising solution by enabling models to "forget" sensitive information without full retraining, offering an efficient and scalable approach compared to traditional data cleaning methods. In this paper, we empirically evaluate the effectiveness of unlearning techniques for addressing privacy concerns in LLMs4Code.Specifically, we investigate three state-of-the-art unlearning algorithms and three well-known open-sourced LLMs4Code, on a benchmark that takes into consideration both the privacy data to be forgotten as well as the code generation capabilites of these models. Results show that it is feasible to mitigate the privacy concerns of LLMs4Code through machine unlearning while maintain their code generation capabilities at the same time. We also dissect the forms of privacy protection/leakage after unlearning and observe that there is a shift from direct leakage to indirect leakage, which underscores the need for future studies addressing this risk.
Seen to Unseen: Exploring Compositional Generalization of Multi-Attribute Controllable Dialogue Generation
Jun 17, 2023



Existing controllable dialogue generation work focuses on the single-attribute control and lacks generalization capability to out-of-distribution multiple attribute combinations. In this paper, we explore the compositional generalization for multi-attribute controllable dialogue generation where a model can learn from seen attribute values and generalize to unseen combinations. We propose a prompt-based disentangled controllable dialogue generation model, DCG. It learns attribute concept composition by generating attribute-oriented prompt vectors and uses a disentanglement loss to disentangle different attributes for better generalization. Besides, we design a unified reference-free evaluation framework for multiple attributes with different levels of granularities. Experiment results on two benchmarks prove the effectiveness of our method and the evaluation metric.
Semi-Supervised Knowledge-Grounded Pre-training for Task-Oriented Dialog Systems
Oct 17, 2022
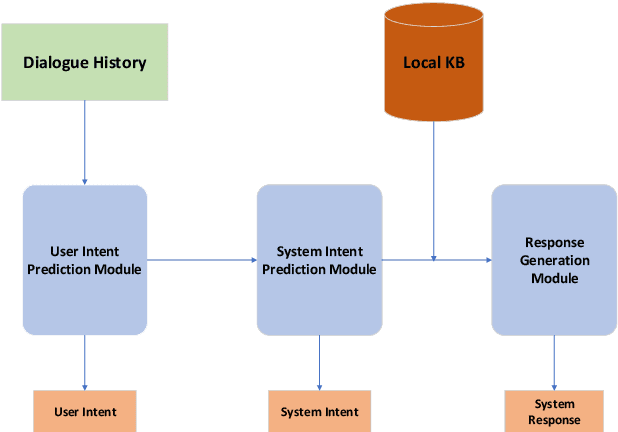
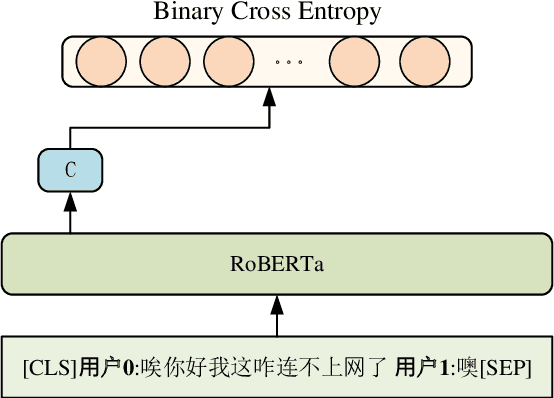
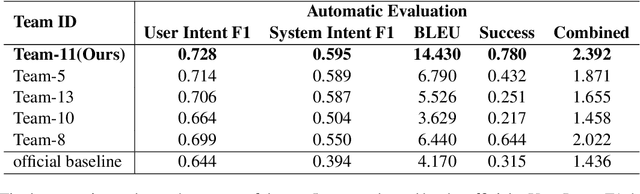
Recent advances in neural approaches greatly improve task-oriented dialogue (TOD) systems which assist users to accomplish their goals. However, such systems rely on costly manually labeled dialogs which are not available in practical scenarios. In this paper, we present our models for Track 2 of the SereTOD 2022 challenge, which is the first challenge of building semi-supervised and reinforced TOD systems on a large-scale real-world Chinese TOD dataset MobileCS. We build a knowledge-grounded dialog model to formulate dialog history and local KB as input and predict the system response. And we perform semi-supervised pre-training both on the labeled and unlabeled data. Our system achieves the first place both in the automatic evaluation and human interaction, especially with higher BLEU (+7.64) and Success (+13.6\%) than the second place.