 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-as-context: Modulating Explicit 3D in Scene-consistent Video Generation to Geometry Context
Feb 25, 2026Scene-consistent video generation aims to create videos that explore 3D scenes based on a camera trajectory. Previous methods rely on video generation models with external memory for consistency, or iterative 3D reconstruction and inpainting, which accumulate errors during inference due to incorrect intermediary outputs, non-differentiable processes, and separate models. To overcome these limitations, we introduce ``geometry-as-context". It iteratively completes the following steps using an autoregressive camera-controlled video generation model: (1) estimates the geometry of the current view necessary for 3D reconstruction, and (2) simulates and restores novel view images rendered by the 3D scene. Under this multi-task framework, we develop the camera gated attention module to enhance the model's capability to effectively leverage camera poses. During the training phase, text contexts are utilized to ascertain whether geometric or RGB images should be generated. To ensure that the model can generate RGB-only outputs during inference, the geometry context is randomly dropped from the interleaved text-image-geometry training sequence. The method has been tested on scene video generation with one-direction and forth-and-back trajectories. The results show its superiority over previous approaches in maintaining scene consistency and camera control.
Bridging Information Asymmetry: A Hierarchical Framework for Deterministic Blind Face Restoration
Jan 27, 2026Blind face restoration remains a persistent challenge due to the inherent ill-posedness of reconstructing holistic structures from severely constrained observations. Current generative approaches, while capable of synthesizing realistic textures, often suffer from information asymmetry -- the intrinsic disparity between the information-sparse low quality inputs and the information-dense high quality outputs. This imbalance leads to a one-to-many mapping, where insufficient constraints result in stochastic uncertainty and hallucinatory artifacts. To bridge this gap, we present \textbf{Pref-Restore}, a hierarchical framework that integrates discrete semantic logic with continuous texture generation to achieve deterministic, preference-aligned restoration. Our methodology fundamentally addresses this information disparity through two complementary strategies: (1) Augmenting Input Density: We employ an auto-regressive integrator to reformulate textual instructions into dense latent queries, injecting high-level semantic stability to constrain the degraded signals; (2) Pruning Output Distribution: We pioneer the integration of on-policy reinforcement learning directly into the diffusion restoration loop. By transforming human preferences into differentiable constraints, we explicitly penalize stochastic deviations, thereby sharpening the posterior distribution toward the desired high-fidelity outcomes. Extensive experiments demonstrate that Pref-Restore achieves state-of-the-art performance across synthetic and real-world benchmarks. Furthermore, empirical analysis confirms that our preference-aligned strategy significantly reduces solution entropy, establishing a robust pathway toward reliable and deterministic blind restoration.
RealPDEBench: A Benchmark for Complex Physical Systems with Real-World Data
Jan 05, 2026Predicting the evolution of complex physical systems remains a central problem in science and engineering. Despite rapid progress in scientific Machine Learning (ML) models, a critical bottleneck is the lack of expensive real-world data, resulting in most current models being trained and validated on simulated data. Beyond limiting the development and evaluation of scientific ML, this gap also hinders research into essential tasks such as sim-to-real transfer. We introduce RealPDEBench, the first benchmark for scientific ML that integrates real-world measurements with paired numerical simulations. RealPDEBench consists of five datasets, three tasks, eight metrics, and ten baselines. We first present five real-world measured datasets with paired simulated datasets across different complex physical systems. We further define three tasks, which allow comparisons between real-world and simulated data, and facilitate the development of methods to bridge the two. Moreover, we design eight evaluation metrics, spanning data-oriented and physics-oriented metrics, and finally benchmark ten representative baselines, including state-of-the-art models, pretrained PDE foundation models, and a traditional method. Experiments reveal significant discrepancies between simulated and real-world data, while showing that pretraining with simulated data consistently improves both accuracy and convergence. In this work, we hope to provide insights from real-world data, advancing scientific ML toward bridging the sim-to-real gap and real-world deployment. Our benchmark, datasets, and instructions are available at https://realpdebench.github.io/.
Learning-Assisted Multi-Operator Variable Neighborhood Search for Urban Cable Routing
Dec 22, 2025Urban underground cable construction is essential for enhancing the reliability of city power grids, yet its high construction costs make planning a worthwhile optimization task. In urban environments, road layouts tightly constrain cable routing. This, on the one hand, renders relation-only models (i.e., those without explicit routes) used in prior work overly simplistic, and on the other hand, dramatically enlarges the combinatorial search space, thereby imposing much higher demands on algorithm design. In this study, we formulate urban cable routing as a connectivity-path co-optimization problem and propose a learning-assisted multi-operator variable neighborhood search (L-MVNS) algorithm. The framework first introduces an auxiliary task to generate high-quality feasible initial solutions. A hybrid genetic search (HGS) and A* serve as the connectivity optimizer and the route-planning optimizer, respectively. Building on these, a multi-operator variable neighborhood search (MVNS) iteratively co-optimizes inter-substation connectivity and detailed routes via three complementary destruction operators, a modified A* repair operator, and an adaptive neighborhood-sizing mechanism. A multi-agent deep reinforcement learning module is further embedded to prioritize promising neighborhoods. We also construct a standardized and scalable benchmark suite for evaluation. Across these cases, comprehensive experiments demonstrate effectiveness and stability: relative to representative approaches, MVNS and L-MVNS reduce total construction cost by approximately 30-50%, with L-MVNS delivering additional gains on larger instances and consistently higher stability.
Large Language Model-assisted Meta-optimizer for Automated Design of Constrained Evolutionary Algorithm
Sep 16, 2025Meta-black-box optimization has been significantly advanced through the use of large language models (LLMs), yet in fancy on constrained evolutionary optimization. In this work, AwesomeDE is proposed that leverages LLMs as the strategy of meta-optimizer to generate update rules for constrained evolutionary algorithm without human intervention. On the meanwhile, $RTO^2H$ framework is introduced for standardize prompt design of LLMs. The meta-optimizer is trained on a diverse set of constrained optimization problems. Key components, including prompt design and iterative refinement, are systematically analyzed to determine their impact on design quality. Experimental results demonstrate that the proposed approach outperforms existing methods in terms of computational efficiency and solution accuracy. Furthermore, AwesomeDE is shown to generalize well across distinct problem domains, suggesting its potential for broad applicability. This research contributes to the field by providing a scalable and data-driven methodology for automated constrained algorithm design, while also highlighting limitations and directions for future work.
Learning to Branch in Combinatorial Optimization with Graph Pointer Networks
Jul 04, 2023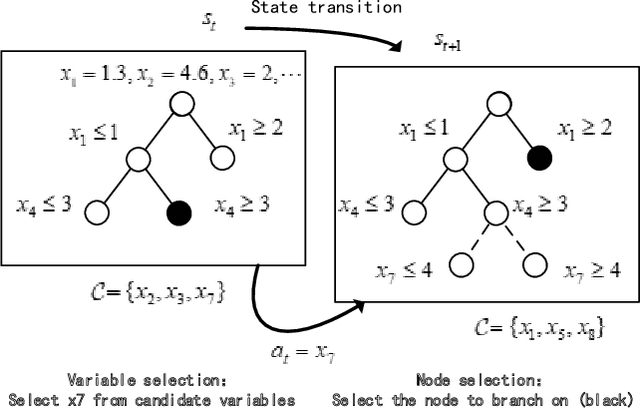
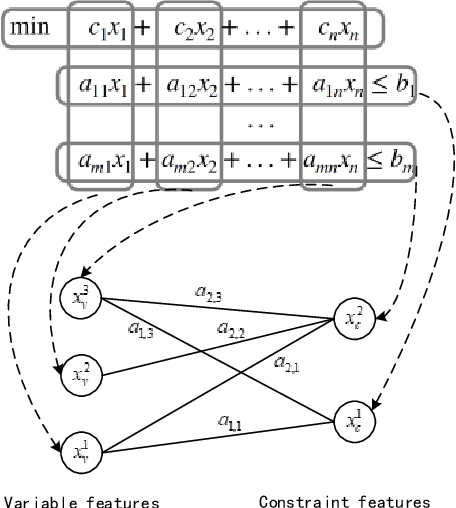


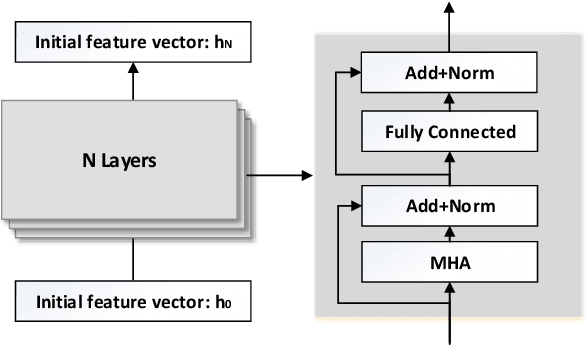
Branch-and-bound is a typical way to solve combinatorial optimization problems. This paper proposes a graph pointer network model for learning the variable selection policy in the branch-and-bound. We extract the graph features, global features and historical features to represent the solver state. The proposed model, which combines the graph neural network and the pointer mechanism, can effectively map from the solver state to the branching variable decisions. The model is trained to imitate the classic strong branching expert rule by a designed top-k Kullback-Leibler divergence loss function. Experiments on a series of benchmark problems demonstrate that the proposed approach significantly outperforms the widely used expert-designed branching rules. Our approach also outperforms the state-of-the-art machine-learning-based branch-and-bound methods in terms of solving speed and search tree size on all the test instances. In addition, the model can generalize to unseen instances and scale to larger instances.
Coevolutionary Framework for Generalized Multimodal Multi-objective Optimization
Dec 05, 2022Most multimodal multi-objective evolutionary algorithms (MMEAs) aim to find all global Pareto optimal sets (PSs) for a multimodal multi-objective optimization problem (MMOP). However, in real-world problems, decision makers (DMs) may be also interested in local PSs. Also, searching for both global and local PSs is more general in view of dealing with MMOPs, which can be seen as a generalized MMOP. In addition, the state-of-the-art MMEAs exhibit poor convergence on high-dimension MMOPs. To address the above two issues, in this study, a novel coevolutionary framework termed CoMMEA for multimodal multi-objective optimization is proposed to better obtain both global and local PSs, and simultaneously, to improve the convergence performance in dealing with high-dimension MMOPs. Specifically, the CoMMEA introduces two archives to the search process, and coevolves them simultaneously through effective knowledge transfer. The convergence archive assists the CoMMEA to quickly approaching the Pareto optimal front (PF). The knowledge of the converged solutions is then transferred to the diversity archive which utilizes the local convergence indicator and the $\epsilon$-dominance-based method to obtain global and local PSs effectively. Experimental results show that CoMMEA is competitive compared to seven state-of-the-art MMEAs on fifty-four complex MMOPs.
Hybridization of evolutionary algorithm and deep reinforcement learning for multi-objective orienteering optimization
Jun 21, 2022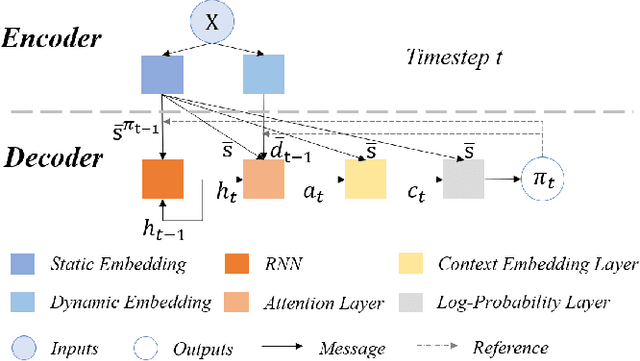
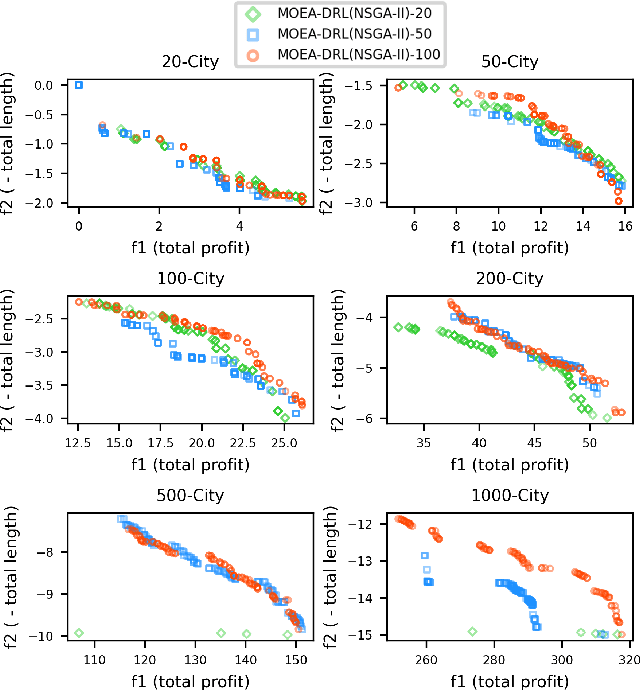
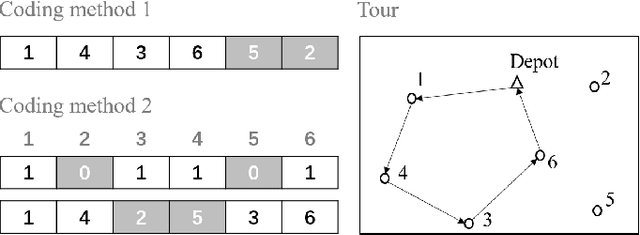
Multi-objective orienteering problems (MO-OPs) are classical multi-objective routing problems and have received a lot of attention in the past decades. This study seeks to solve MO-OPs through a problem-decomposition framework, that is, a MO-OP is decomposed into a multi-objective knapsack problem (MOKP) and a travelling salesman problem (TSP). The MOKP and TSP are then solved by a multi-objective evolutionary algorithm (MOEA) and a deep reinforcement learning (DRL) method, respectively. While the MOEA module is for selecting cities, the DRL module is for planning a Hamiltonian path for these cities. An iterative use of these two modules drives the population towards the Pareto front of MO-OPs. The effectiveness of the proposed method is compared against NSGA-II and NSGA-III on various types of MO-OP instances. Experimental results show that our method exhibits the best performance on almost all the test instances, and has shown strong generalization ability.
Deep Reinforcement Learning for Orienteering Problems Based on Decomposition
Apr 25, 2022
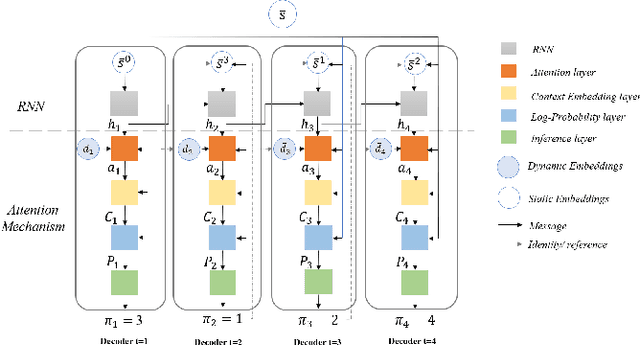
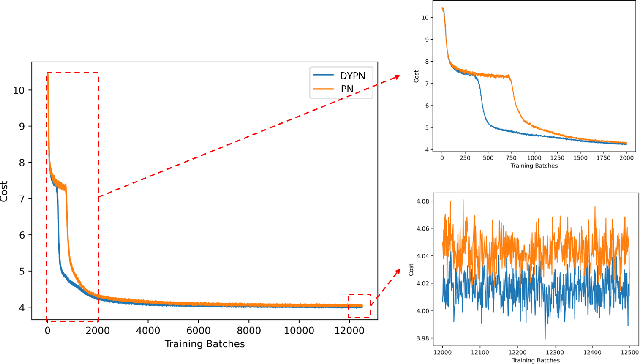
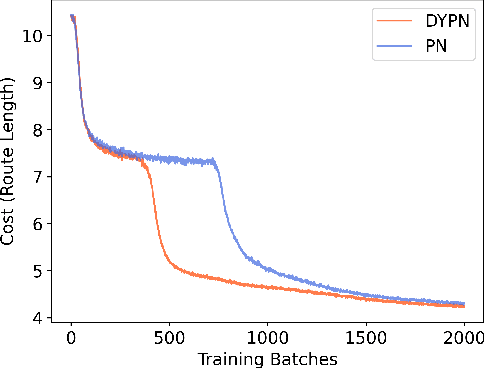
This paper presents a new method for solving an orienteering problem (OP) by breaking it down into two parts: a knapsack problem (KP) and a traveling salesman problem (TSP). A KP solver is responsible for picking nodes, while a TSP solver is responsible for designing the proper path and assisting the KP solver in judging constraint violations. To address constraints, we propose a dual-population coevolutionary algorithm (DPCA) as the KP solver, which simultaneously maintains both feasible and infeasible populations. A dynamic pointer network (DYPN) is introduced as the TSP solver, which takes city locations as inputs and immediately outputs a permutation of nodes. The model, which is trained by reinforcement learning, can capture both the structural and dynamic patterns of the given problem. The model can generalize to other instances with different scales and distributions. Experimental results show that the proposed algorithm can outperform conventional approaches in terms of training, inference, and generalization ability.
Deep Reinforcement Learning for Online Routing of Unmanned Aerial Vehicles with Wireless Power Transfer
Apr 25, 2022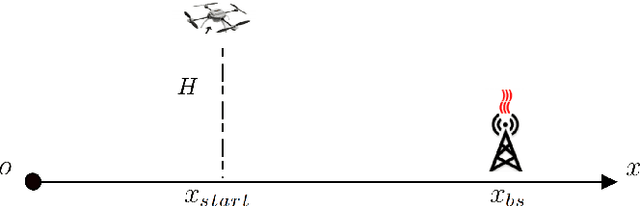
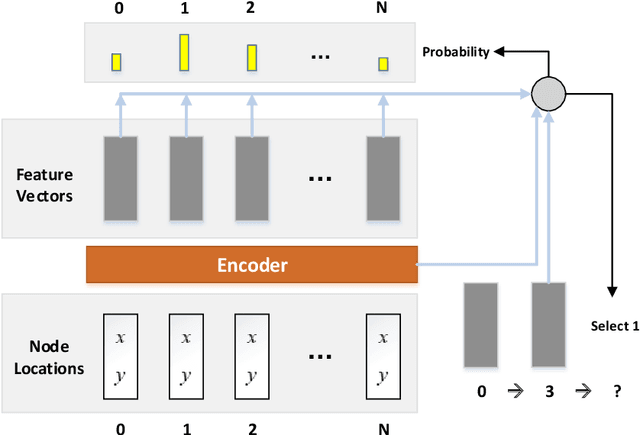
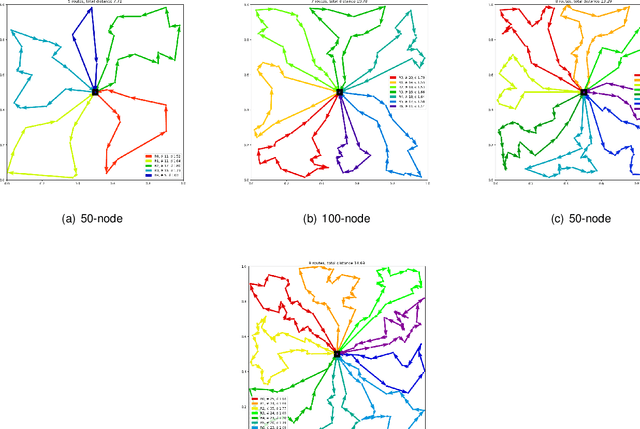
The unmanned aerial vehicle (UAV) plays an vital role in various applications such as delivery, military mission, disaster rescue, communication, etc., due to its flexibility and versatility. This paper proposes a deep reinforcement learning method to solve the UAV online routing problem with wireless power transfer, which can charge the UAV remotely without wires, thus extending the capability of the battery-limited UAV. Our study considers the power consumption of the UAV and the wireless charging process. Unlike the previous works, we solve the problem by a designed deep neural network. The model is trained using a deep reinforcement learning method offline, and is used to optimize the UAV routing problem online. On small and large scale instances, the proposed model runs from four times to 500 times faster than Google OR-tools, the state-of-the-art combinatorial optimization solver, with identical solution quality. It also outperforms different types of heuristic and local search methods in terms of both run-time and optimality. In addition, once the model is trained, it can scale to new generated problem instances with arbitrary topology that are not seen during training. The proposed method is practically applicable when the problem scale is large and the response time is crucial.