 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Multi-objective Optimization
Paper and Code
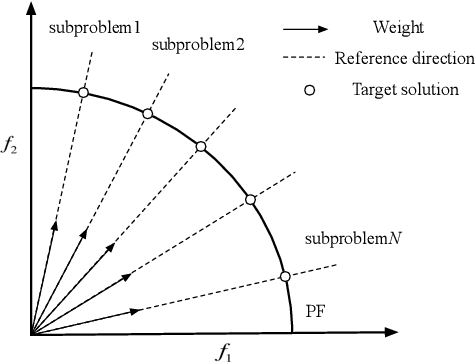



This study proposes an end-to-end framework for solving multi-objective optimization problems (MOPs) using Deep Reinforcement Learning (DRL), termed DRL-MOA. The idea of decomposition is adopted to decompose a MOP into a set of scalar optimization subproblems. The subproblems are then optimized cooperatively by a neighbourhood-based parameter transfer strategy which significantly accelerates the training procedure and makes the realization of DRL-MOA possible. The subproblems are modelled as neural networks and the RL method is used to optimize them. In specific, the multi-objective travelling salesman problem (MOTSP) is solved in this work using the DRL-MOA framework by modelling the subproblem as the Pointer Network. It is found that, once the trained model is available, it can scale to MOTSPs of any number of cities, e.g., 70-city, 100-city, even the 200-city MOTSP, without re-training the model. The Pareto Front can be directly obtained by a simple feed-forward of the network; thereby, no iteration is required and the MOP can be always solved in a reasonable time. Experimental results indicate a strong convergence ability of the DRL-MOA, especially for large-scale MOTSPs, e.g., 200-city MOTSP, for which evolutionary algorithms such as NSGA-II and MOEA/D are pretty hard to converge even implemented for a large number of iterations. The DRL-MOA can also obtain a much wider spread of the PF than the two competitors. Moreover, the DRL-MOA has a high level of modularity and can be easily generalized to other MOPs by replacing the modelling of the subproblem.