 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improved Preference Optimization Pipeline: from Data Generation to Budget-Controlled Regularization
Paper and Code
Nov 07, 2024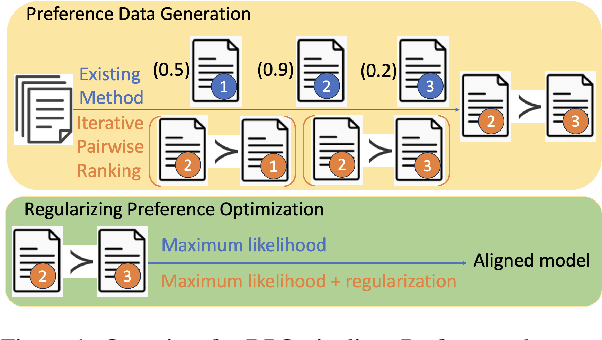

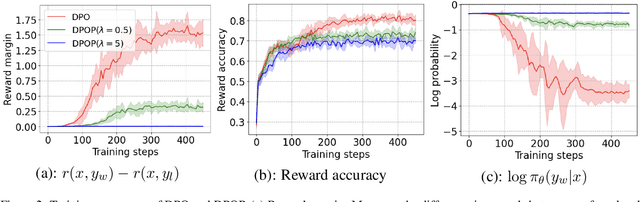
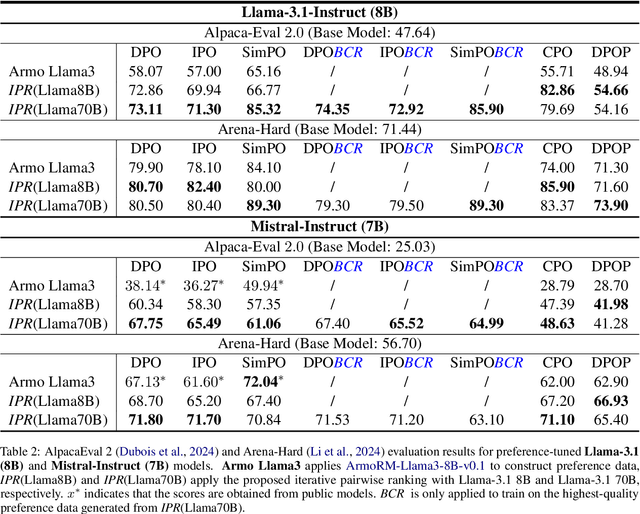
Direct Preference Optimization (DPO) and its variants have become the de facto standards for aligning large language models (LLMs) with human preferences or specific goals. However, DPO requires high-quality preference data and suffers from unstable preference optimization. In this work, we aim to improve the preference optimization pipeline by taking a closer look at preference data generation and training regularization techniques. For preference data generation, we demonstrate that existing scoring-based reward models produce unsatisfactory preference data and perform poorly on out-of-distribution tasks. This significantly impacts the LLM alignment performance when using these data for preference tuning. To ensure high-quality preference data generation, we propose an iterative pairwise ranking mechanism that derives preference ranking of completions using pairwise comparison signals. For training regularization, we observe that preference optimization tends to achieve better convergence when the LLM predicted likelihood of preferred samples gets slightly reduced. However, the widely used supervised next-word prediction regularization strictly prevents any likelihood reduction of preferred samples. This observation motivates our design of a budget-controlled regularization formulation. Empirically we show that combining the two designs leads to aligned models that surpass existing SOTA across two popular benchmarks.