Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation from Logged Human Feedback
Paper and Code
Jun 14, 2024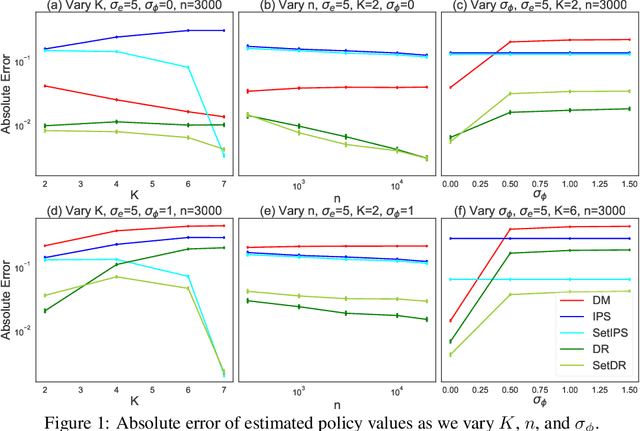
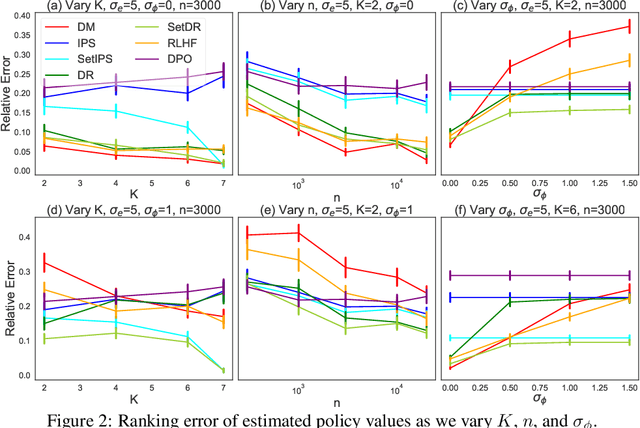
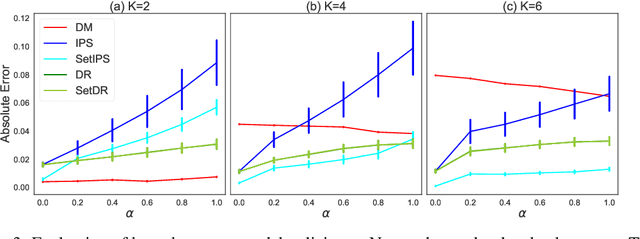

Learning from human feedback has been central to recent advances in artificial intelligence and machine learning. Since the collection of human feedback is costly, a natural question to ask is if the new feedback always needs to collected. Or could we evaluate a new model with the human feedback on responses of another model? This motivates us to study off-policy evaluation from logged human feedback. We formalize the problem, propose both model-based and model-free estimators for policy values, and show how to optimize them. We analyze unbiasedness of our estimators and evaluate them empirically. Our estimators can predict the absolute values of evaluated policies, rank them, and be optimized.
View paper on