 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Bandits with Feature Feedback
Mar 12, 2019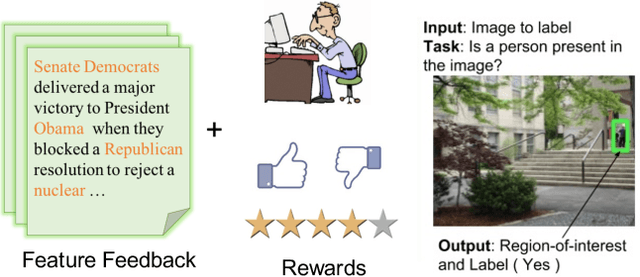
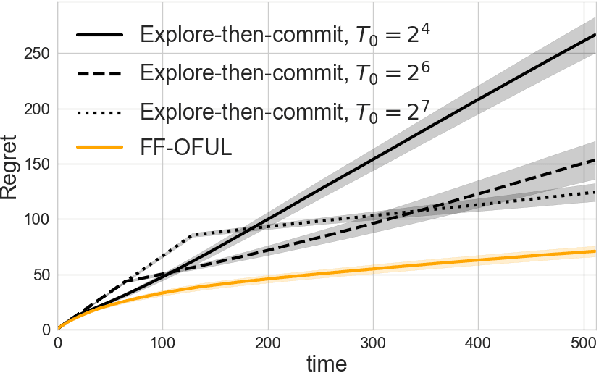

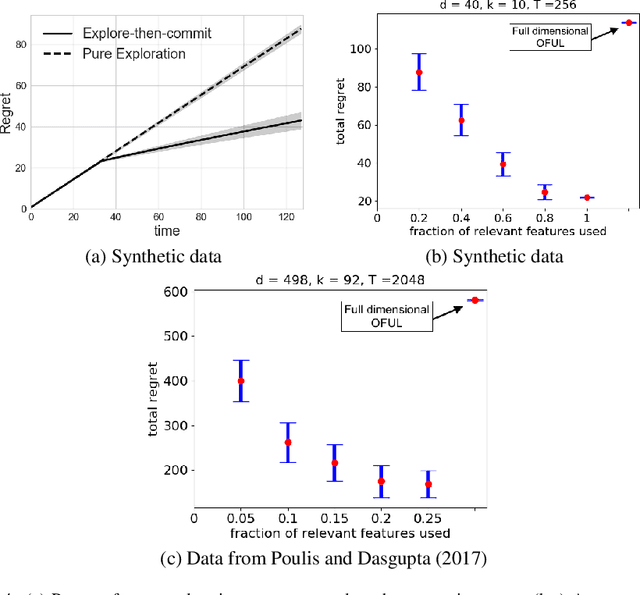
This paper explores a new form of the linear bandit problem in which the algorithm receives the usual stochastic rewards as well as stochastic feedback about which features are relevant to the rewards, the latter feedback being the novel aspect. The focus of this paper is the development of new theory and algorithms for linear bandits with feature feedback. We show that linear bandits with feature feedback can achieve regret over time horizon $T$ that scales like $k\sqrt{T}$, without prior knowledge of which features are relevant nor the number $k$ of relevant features. In comparison, the regret of traditional linear bandits is $d\sqrt{T}$, where $d$ is the total number of (relevant and irrelevant) features, so the improvement can be dramatic if $k\ll d$. The computational complexity of the new algorithm is proportional to $k$ rather than $d$, making it much more suitable for real-world applications compared to traditional linear bandits. We demonstrate the performance of the new algorithm with synthetic and real human-labeled data.
Scalable Sparse Subspace Clustering via Ordered Weighted $\ell_1$ Regression
Jul 10, 2018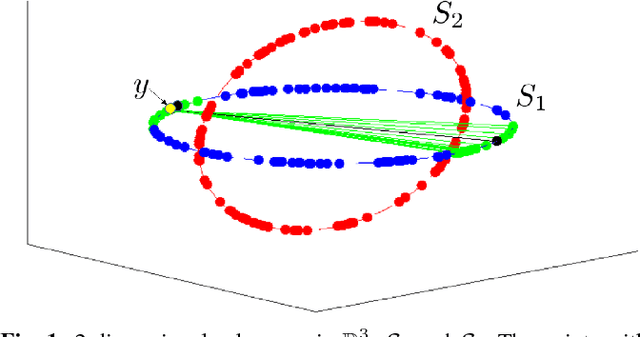


The main contribution of the paper is a new approach to subspace clustering that is significantly more computationally efficient and scalable than existing state-of-the-art methods. The central idea is to modify the regression technique in sparse subspace clustering (SSC) by replacing the $\ell_1$ minimization with a generalization called Ordered Weighted $\ell_1$ (OWL) minimization which performs simultaneous regression and clustering of correlated variables. Using random geometric graph theory, we prove that OWL regression selects more points within each subspace, resulting in better clustering results. This allows for accurate subspace clustering based on regression solutions for only a small subset of the total dataset, significantly reducing the computational complexity compared to SSC. In experiments, we find that our OWL approach can achieve a speedup of 20$\times$ to 30$\times$ for synthetic problems and 4$\times$ to 8$\times$ on real data problems.
Block CUR: Decomposing Matrices using Groups of Columns
Jul 09, 2018
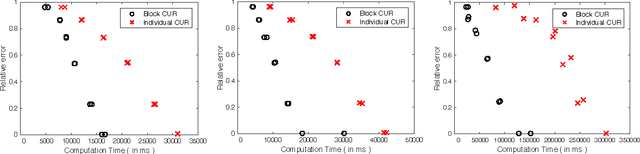
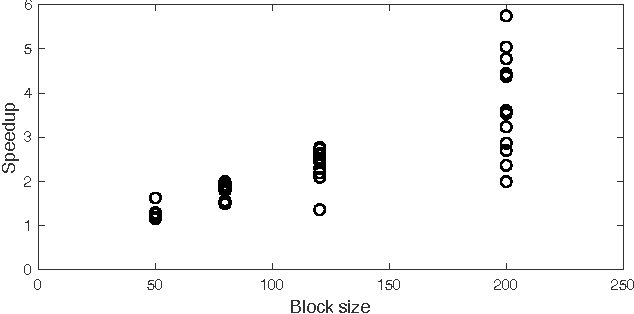
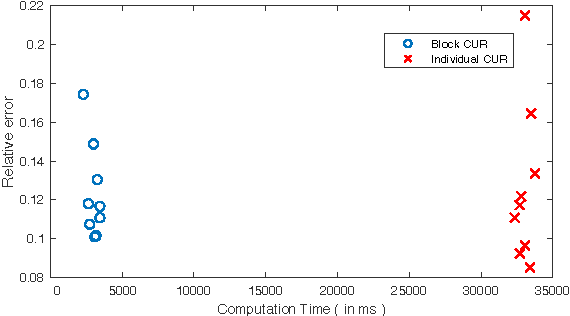
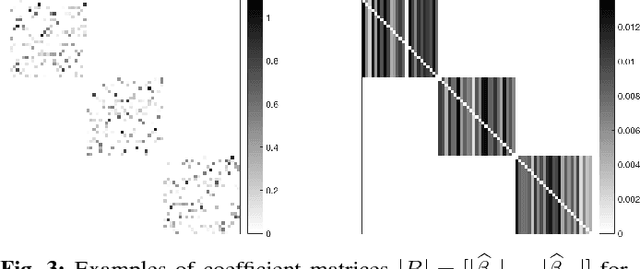
A common problem in large-scale data analysis is to approximate a matrix using a combination of specifically sampled rows and columns, known as CUR decomposition. Unfortunately, in many real-world environments, the ability to sample specific individual rows or columns of the matrix is limited by either system constraints or cost. In this paper, we consider matrix approximation by sampling predefined \emph{blocks} of columns (or rows) from the matrix. We present an algorithm for sampling useful column blocks and provide novel guarantees for the quality of the approximation. This algorithm has application in problems as diverse as biometric data analysis to distributed computing. We demonstrate the effectiveness of the proposed algorithms for computing the Block CUR decomposition of large matrices in a distributed setting with multiple nodes in a compute cluster, where such blocks correspond to columns (or rows) of the matrix stored on the same node, which can be retrieved with much less overhead than retrieving individual columns stored across different nodes. In the biometric setting, the rows correspond to different users and columns correspond to users' biometric reaction to external stimuli, {\em e.g.,}~watching video content, at a particular time instant. There is significant cost in acquiring each user's reaction to lengthy content so we sample a few important scenes to approximate the biometric response. An individual time sample in this use case cannot be queried in isolation due to the lack of context that caused that biometric reaction. Instead, collections of time segments ({\em i.e.,} blocks) must be presented to the user. The practical application of these algorithms is shown via experimental results using real-world user biometric data from a content testing environment.
A Compressed Sensing Based Decomposition of Electrodermal Activity Signals
Jan 26, 2017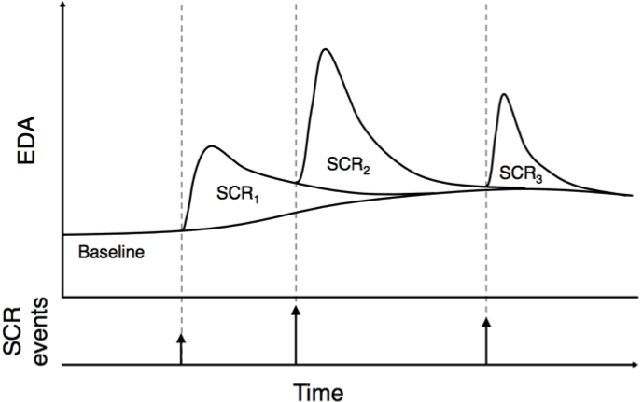
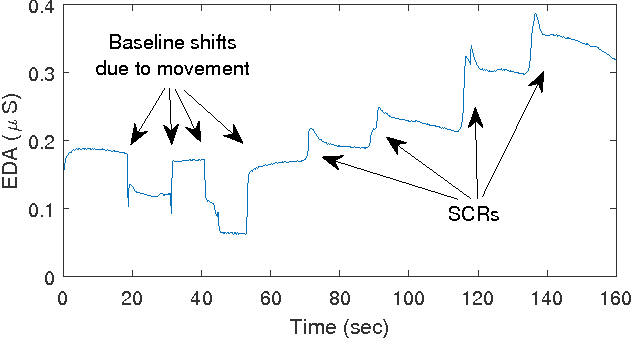

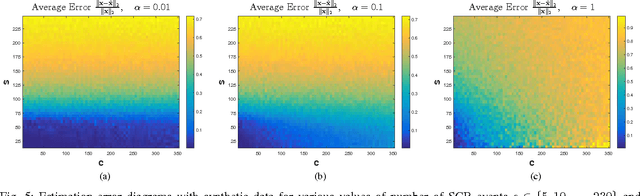
The measurement and analysis of Electrodermal Activity (EDA) offers applications in diverse areas ranging from market research, to seizure detection, to human stress analysis. Unfortunately, the analysis of EDA signals is made difficult by the superposition of numerous components which can obscure the signal information related to a user's response to a stimulus. We show how simple pre-processing followed by a novel compressed sensing based decomposition can mitigate the effects of the undesired noise components and help reveal the underlying physiological signal. The proposed framework allows for decomposition of EDA signals with provable bounds on the recovery of user responses. We test our procedure on both synthetic and real-world EDA signals from wearable sensors and demonstrate that our approach allows for more accurate recovery of user responses as compared to the existing techniques.