 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock CUR: Decomposing Matrices using Groups of Columns
Jul 09, 2018
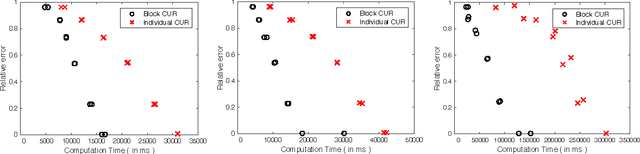
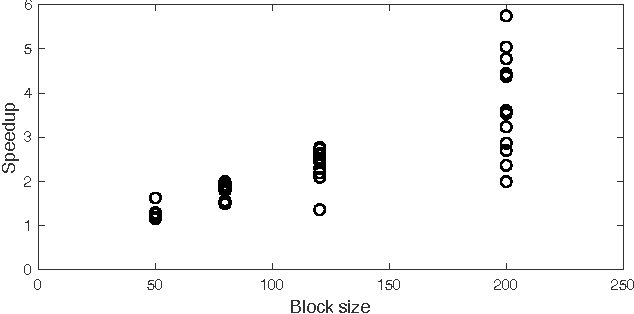
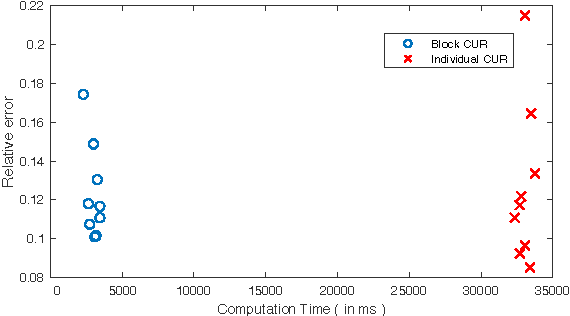
A common problem in large-scale data analysis is to approximate a matrix using a combination of specifically sampled rows and columns, known as CUR decomposition. Unfortunately, in many real-world environments, the ability to sample specific individual rows or columns of the matrix is limited by either system constraints or cost. In this paper, we consider matrix approximation by sampling predefined \emph{blocks} of columns (or rows) from the matrix. We present an algorithm for sampling useful column blocks and provide novel guarantees for the quality of the approximation. This algorithm has application in problems as diverse as biometric data analysis to distributed computing. We demonstrate the effectiveness of the proposed algorithms for computing the Block CUR decomposition of large matrices in a distributed setting with multiple nodes in a compute cluster, where such blocks correspond to columns (or rows) of the matrix stored on the same node, which can be retrieved with much less overhead than retrieving individual columns stored across different nodes. In the biometric setting, the rows correspond to different users and columns correspond to users' biometric reaction to external stimuli, {\em e.g.,}~watching video content, at a particular time instant. There is significant cost in acquiring each user's reaction to lengthy content so we sample a few important scenes to approximate the biometric response. An individual time sample in this use case cannot be queried in isolation due to the lack of context that caused that biometric reaction. Instead, collections of time segments ({\em i.e.,} blocks) must be presented to the user. The practical application of these algorithms is shown via experimental results using real-world user biometric data from a content testing environment.
Wide Compression: Tensor Ring Nets
Feb 25, 2018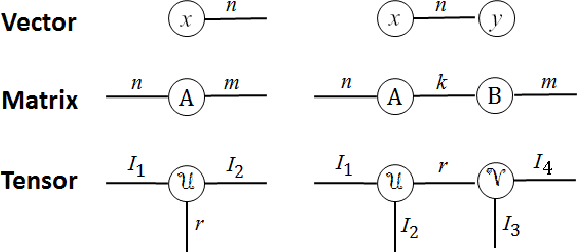

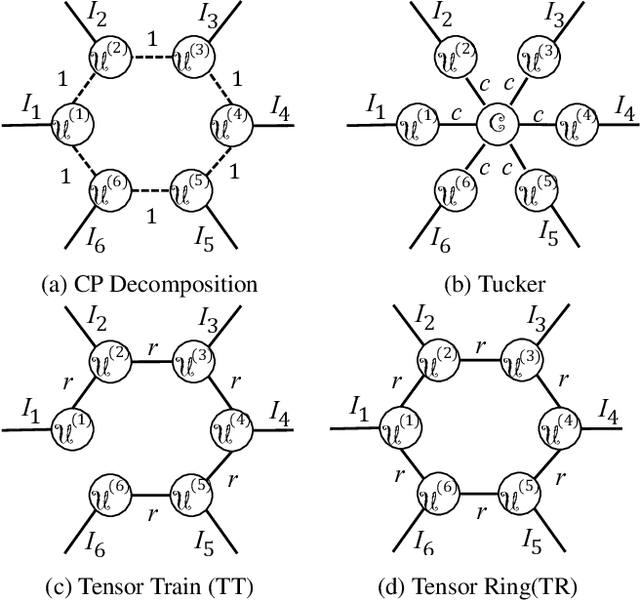
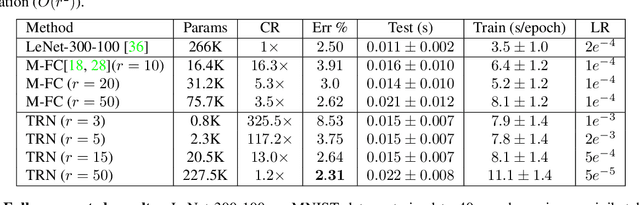
Deep neural networks have demonstrated state-of-the-art performance in a variety of real-world applications. In order to obtain performance gains, these networks have grown larger and deeper, containing millions or even billions of parameters and over a thousand layers. The trade-off is that these large architectures require an enormous amount of memory, storage, and computation, thus limiting their usability. Inspired by the recent tensor ring factorization, we introduce Tensor Ring Networks (TR-Nets), which significantly compress both the fully connected layers and the convolutional layers of deep neural networks. Our results show that our TR-Nets approach {is able to compress LeNet-5 by $11\times$ without losing accuracy}, and can compress the state-of-the-art Wide ResNet by $243\times$ with only 2.3\% degradation in {Cifar10 image classification}. Overall, this compression scheme shows promise in scientific computing and deep learning, especially for emerging resource-constrained devices such as smartphones, wearables, and IoT devices.
Deep Unsupervised Clustering Using Mixture of Autoencoders
Dec 26, 2017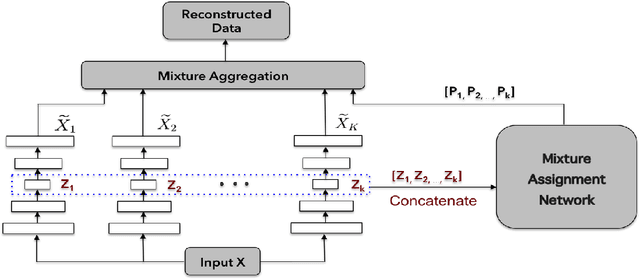
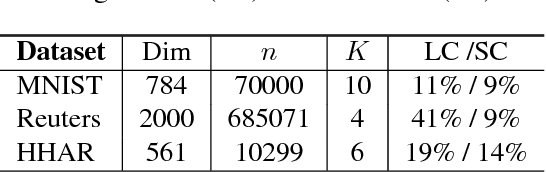
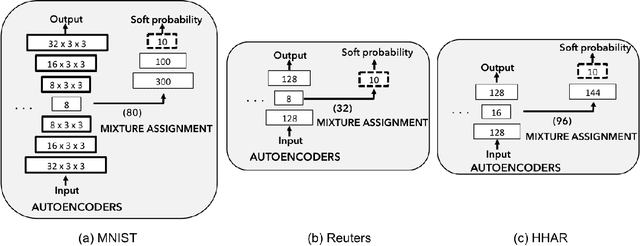
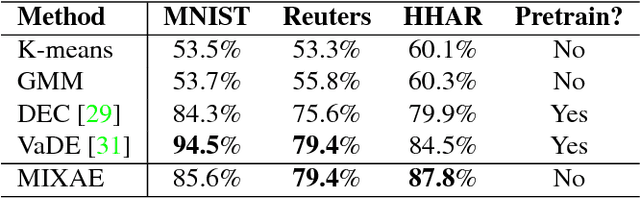
Unsupervised clustering is one of the most fundamental challenges in machine learning. A popular hypothesis is that data are generated from a union of low-dimensional nonlinear manifolds; thus an approach to clustering is identifying and separating these manifolds. In this paper, we present a novel approach to solve this problem by using a mixture of autoencoders. Our model consists of two parts: 1) a collection of autoencoders where each autoencoder learns the underlying manifold of a group of similar objects, and 2) a mixture assignment neural network, which takes the concatenated latent vectors from the autoencoders as input and infers the distribution over clusters. By jointly optimizing the two parts, we simultaneously assign data to clusters and learn the underlying manifolds of each cluster.
A Compressed Sensing Based Decomposition of Electrodermal Activity Signals
Jan 26, 2017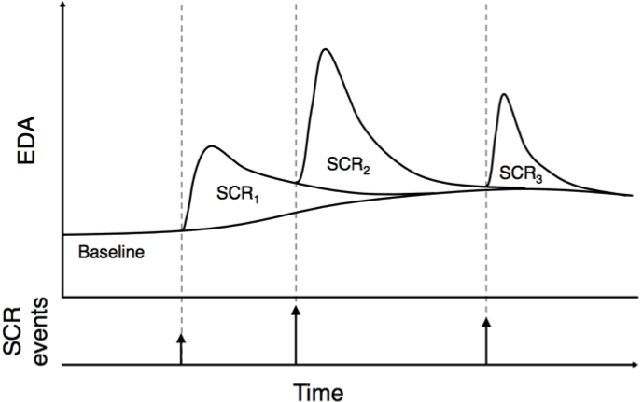
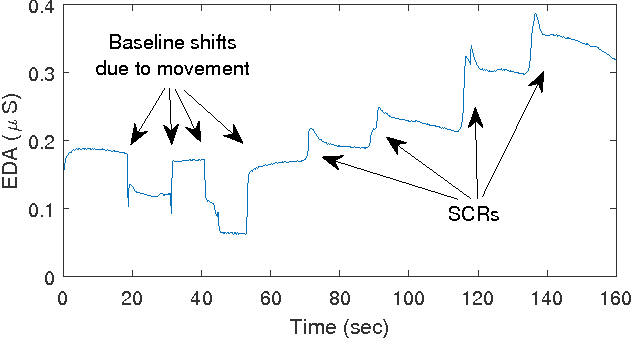

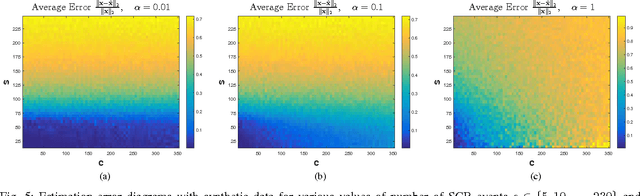
The measurement and analysis of Electrodermal Activity (EDA) offers applications in diverse areas ranging from market research, to seizure detection, to human stress analysis. Unfortunately, the analysis of EDA signals is made difficult by the superposition of numerous components which can obscure the signal information related to a user's response to a stimulus. We show how simple pre-processing followed by a novel compressed sensing based decomposition can mitigate the effects of the undesired noise components and help reveal the underlying physiological signal. The proposed framework allows for decomposition of EDA signals with provable bounds on the recovery of user responses. We test our procedure on both synthetic and real-world EDA signals from wearable sensors and demonstrate that our approach allows for more accurate recovery of user responses as compared to the existing techniques.
Matroid Bandits: Fast Combinatorial Optimization with Learning
Jun 16, 2014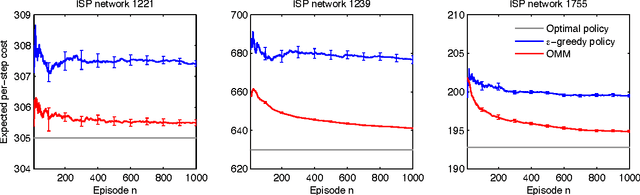
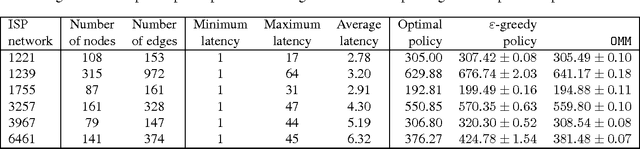
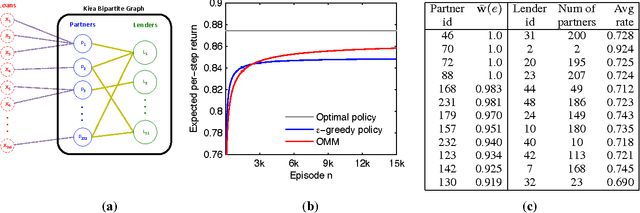

A matroid is a notion of independence in combinatorial optimization which is closely related to computational efficiency. In particular, it is well known that the maximum of a constrained modular function can be found greedily if and only if the constraints are associated with a matroid. In this paper, we bring together the ideas of bandits and matroids, and propose a new class of combinatorial bandits, matroid bandits. The objective in these problems is to learn how to maximize a modular function on a matroid. This function is stochastic and initially unknown. We propose a practical algorithm for solving our problem, Optimistic Matroid Maximization (OMM); and prove two upper bounds, gap-dependent and gap-free, on its regret. Both bounds are sublinear in time and at most linear in all other quantities of interest. The gap-dependent upper bound is tight and we prove a matching lower bound on a partition matroid bandit. Finally, we evaluate our method on three real-world problems and show that it is practical.
Learning Latent Variable Gaussian Graphical Models
Jun 10, 2014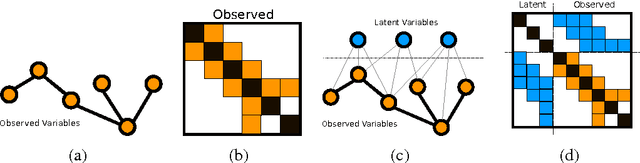
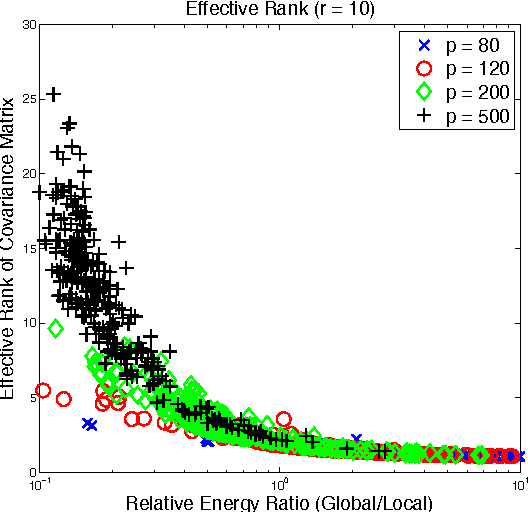
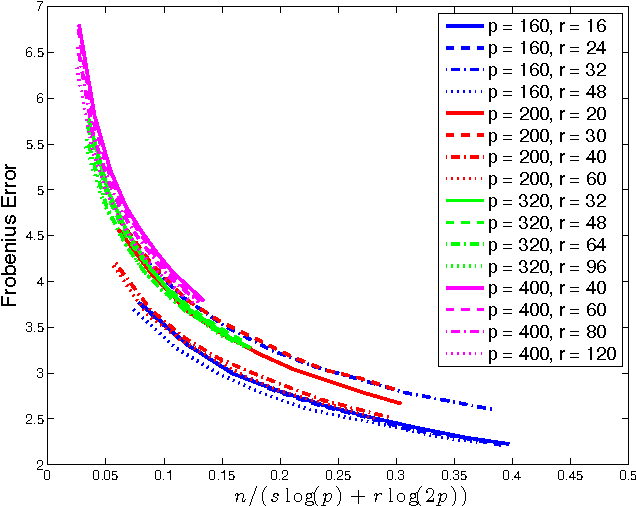
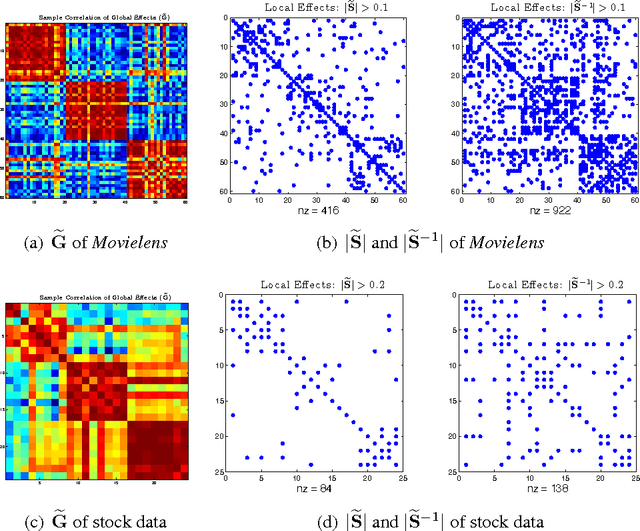
Gaussian graphical models (GGM) have been widely used in many high-dimensional applications ranging from biological and financial data to recommender systems. Sparsity in GGM plays a central role both statistically and computationally. Unfortunately, real-world data often does not fit well to sparse graphical models. In this paper, we focus on a family of latent variable Gaussian graphical models (LVGGM), where the model is conditionally sparse given latent variables, but marginally non-sparse. In LVGGM, the inverse covariance matrix has a low-rank plus sparse structure, and can be learned in a regularized maximum likelihood framework. We derive novel parameter estimation error bounds for LVGGM under mild conditions in the high-dimensional setting. These results complement the existing theory on the structural learning, and open up new possibilities of using LVGGM for statistical inference.
Hierarchical Clustering using Randomly Selected Similarities
Jul 19, 2012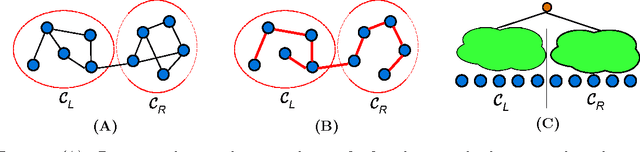
The problem of hierarchical clustering items from pairwise similarities is found across various scientific disciplines, from biology to networking. Often, applications of clustering techniques are limited by the cost of obtaining similarities between pairs of items. While prior work has been developed to reconstruct clustering using a significantly reduced set of pairwise similarities via adaptive measurements, these techniques are only applicable when choice of similarities are available to the user. In this paper, we examine reconstructing hierarchical clustering under similarity observations at-random. We derive precise bounds which show that a significant fraction of the hierarchical clustering can be recovered using fewer than all the pairwise similarities. We find that the correct hierarchical clustering down to a constant fraction of the total number of items (i.e., clusters sized O(N)) can be found using only O(N log N) randomly selected pairwise similarities in expectation.
High-Rank Matrix Completion and Subspace Clustering with Missing Data
Dec 27, 2011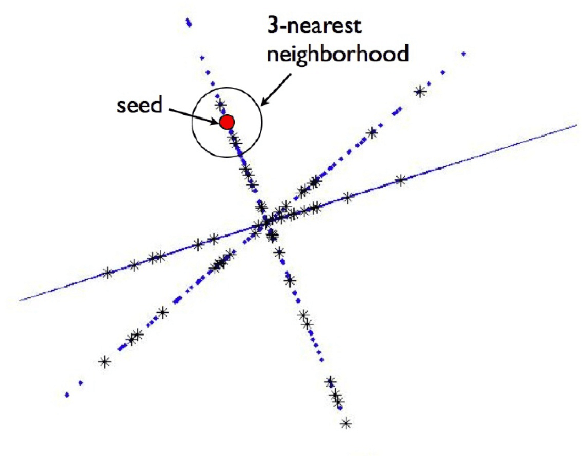
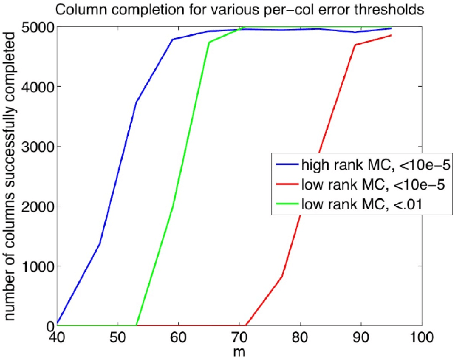
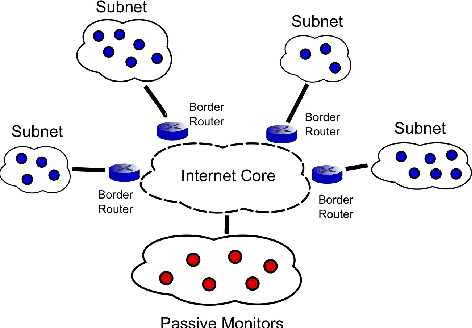
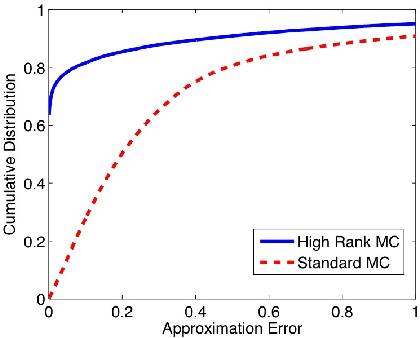
This paper considers the problem of completing a matrix with many missing entries under the assumption that the columns of the matrix belong to a union of multiple low-rank subspaces. This generalizes the standard low-rank matrix completion problem to situations in which the matrix rank can be quite high or even full rank. Since the columns belong to a union of subspaces, this problem may also be viewed as a missing-data version of the subspace clustering problem. Let X be an n x N matrix whose (complete) columns lie in a union of at most k subspaces, each of rank <= r < n, and assume N >> kn. The main result of the paper shows that under mild assumptions each column of X can be perfectly recovered with high probability from an incomplete version so long as at least CrNlog^2(n) entries of X are observed uniformly at random, with C>1 a constant depending on the usual incoherence conditions, the geometrical arrangement of subspaces, and the distribution of columns over the subspaces. The result is illustrated with numerical experiments and an application to Internet distance matrix completion and topology identification.
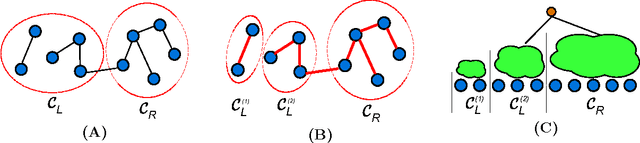
Active Clustering: Robust and Efficient Hierarchical Clustering using Adaptively Selected Similarities
Feb 18, 2011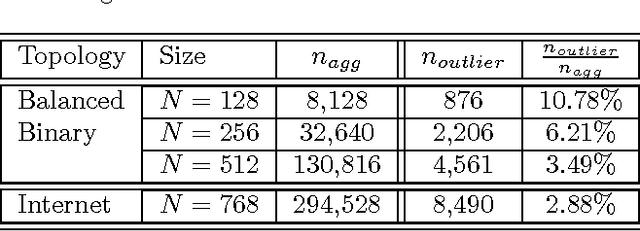

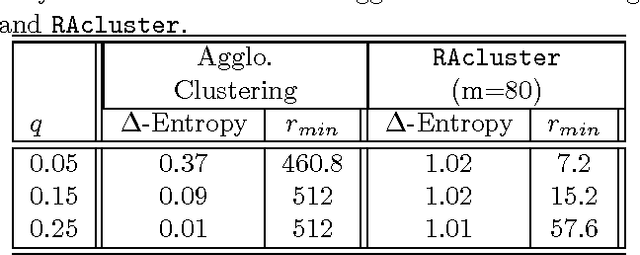
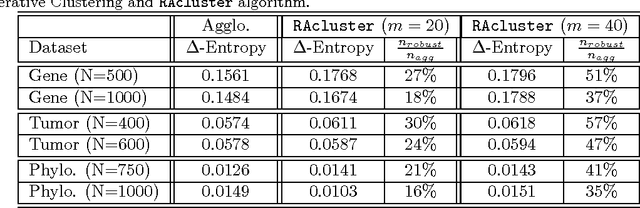
Hierarchical clustering based on pairwise similarities is a common tool used in a broad range of scientific applications. However, in many problems it may be expensive to obtain or compute similarities between the items to be clustered. This paper investigates the hierarchical clustering of N items based on a small subset of pairwise similarities, significantly less than the complete set of N(N-1)/2 similarities. First, we show that if the intracluster similarities exceed intercluster similarities, then it is possible to correctly determine the hierarchical clustering from as few as 3N log N similarities. We demonstrate this order of magnitude savings in the number of pairwise similarities necessitates sequentially selecting which similarities to obtain in an adaptive fashion, rather than picking them at random. We then propose an active clustering method that is robust to a limited fraction of anomalous similarities, and show how even in the presence of these noisy similarity values we can resolve the hierarchical clustering using only O(N log^2 N) pairwise similarities.