 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock CUR: Decomposing Matrices using Groups of Columns
Paper and Code
Jul 09, 2018
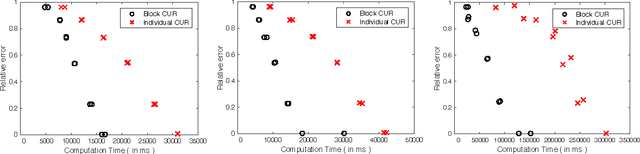
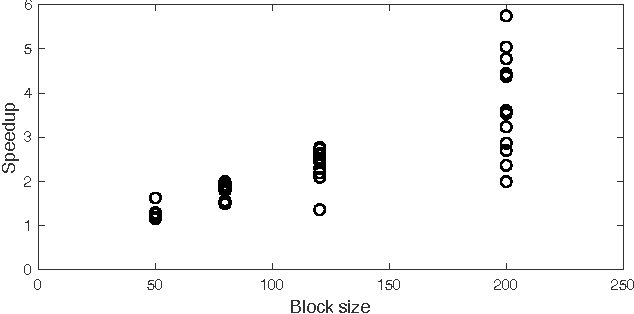
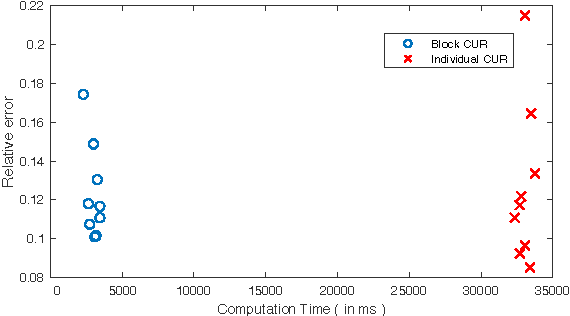
A common problem in large-scale data analysis is to approximate a matrix using a combination of specifically sampled rows and columns, known as CUR decomposition. Unfortunately, in many real-world environments, the ability to sample specific individual rows or columns of the matrix is limited by either system constraints or cost. In this paper, we consider matrix approximation by sampling predefined \emph{blocks} of columns (or rows) from the matrix. We present an algorithm for sampling useful column blocks and provide novel guarantees for the quality of the approximation. This algorithm has application in problems as diverse as biometric data analysis to distributed computing. We demonstrate the effectiveness of the proposed algorithms for computing the Block CUR decomposition of large matrices in a distributed setting with multiple nodes in a compute cluster, where such blocks correspond to columns (or rows) of the matrix stored on the same node, which can be retrieved with much less overhead than retrieving individual columns stored across different nodes. In the biometric setting, the rows correspond to different users and columns correspond to users' biometric reaction to external stimuli, {\em e.g.,}~watching video content, at a particular time instant. There is significant cost in acquiring each user's reaction to lengthy content so we sample a few important scenes to approximate the biometric response. An individual time sample in this use case cannot be queried in isolation due to the lack of context that caused that biometric reaction. Instead, collections of time segments ({\em i.e.,} blocks) must be presented to the user. The practical application of these algorithms is shown via experimental results using real-world user biometric data from a content testing environment.