 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-based Event Data Coding: A Joint Spatiotemporal and Polarity Solution
Feb 05, 2025



Neuromorphic vision sensors, commonly referred to as event cameras, have recently gained relevance for applications requiring high-speed, high dynamic range and low-latency data acquisition. Unlike traditional frame-based cameras that capture 2D images, event cameras generate a massive number of pixel-level events, composed by spatiotemporal and polarity information, with very high temporal resolution, thus demanding highly efficient coding solutions. Existing solutions focus on lossless coding of event data, assuming that no distortion is acceptable for the target use cases, mostly including computer vision tasks. One promising coding approach exploits the similarity between event data and point clouds, thus allowing to use current point cloud coding solutions to code event data, typically adopting a two-point clouds representation, one for each event polarity. This paper proposes a novel lossy Deep Learning-based Joint Event data Coding (DL-JEC) solution adopting a single-point cloud representation, thus enabling to exploit the correlation between the spatiotemporal and polarity event information. DL-JEC can achieve significant compression performance gains when compared with relevant conventional and DL-based state-of-the-art event data coding solutions. Moreover, it is shown that it is possible to use lossy event data coding with its reduced rate regarding lossless coding without compromising the target computer vision task performance, notably for event classification. The use of novel adaptive voxel binarization strategies, adapted to the target task, further enables DL-JEC to reach a superior performance.
Double Deep Learning-based Event Data Coding and Classification
Jul 22, 2024Event cameras have the ability to capture asynchronous per-pixel brightness changes, called "events", offering advantages over traditional frame-based cameras for computer vision applications. Efficiently coding event data is critical for transmission and storage, given the significant volume of events. This paper proposes a novel double deep learning-based architecture for both event data coding and classification, using a point cloud-based representation for events. In this context, the conversions from events to point clouds and back to events are key steps in the proposed solution, and therefore its impact is evaluated in terms of compression and classification performance. Experimental results show that it is possible to achieve a classification performance of compressed events which is similar to one of the original events, even after applying a lossy point cloud codec, notably the recent learning-based JPEG Pleno Point Cloud Coding standard, with a clear rate reduction. Experimental results also demonstrate that events coded using JPEG PCC achieve better classification performance than those coded using the conventional lossy MPEG Geometry-based Point Cloud Coding standard. Furthermore, the adoption of learning-based coding offers high potential for performing computer vision tasks in the compressed domain, which allows skipping the decoding stage while mitigating the impact of coding artifacts.
Deep Learning-based Compressed Domain Multimedia for Man and Machine: A Taxonomy and Application to Point Cloud Classification
Oct 28, 2023



In the current golden age of multimedia, human visualization is no longer the single main target, with the final consumer often being a machine which performs some processing or computer vision tasks. In both cases, deep learning plays a undamental role in extracting features from the multimedia representation data, usually producing a compressed representation referred to as latent representation. The increasing development and adoption of deep learning-based solutions in a wide area of multimedia applications have opened an exciting new vision where a common compressed multimedia representation is used for both man and machine. The main benefits of this vision are two-fold: i) improved performance for the computer vision tasks, since the effects of coding artifacts are mitigated; and ii) reduced computational complexity, since prior decoding is not required. This paper proposes the first taxonomy for designing compressed domain computer vision solutions driven by the architecture and weights compatibility with an available spatio-temporal computer vision processor. The potential of the proposed taxonomy is demonstrated for the specific case of point cloud classification by designing novel compressed domain processors using the JPEG Pleno Point Cloud Coding standard under development and adaptations of the PointGrid classifier. Experimental results show that the designed compressed domain point cloud classification solutions can significantly outperform the spatial-temporal domain classification benchmarks when applied to the decompressed data, containing coding artifacts, and even surpass their performance when applied to the original uncompressed data.
IT/IST/IPLeiria Response to the Call for Proposals on JPEG Pleno Point Cloud Coding
Aug 04, 2022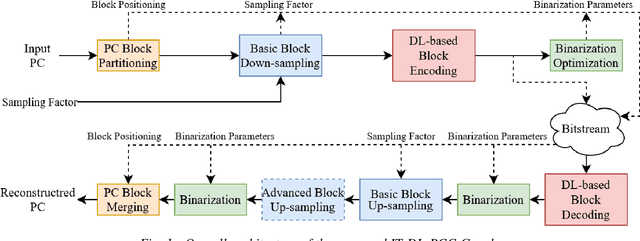
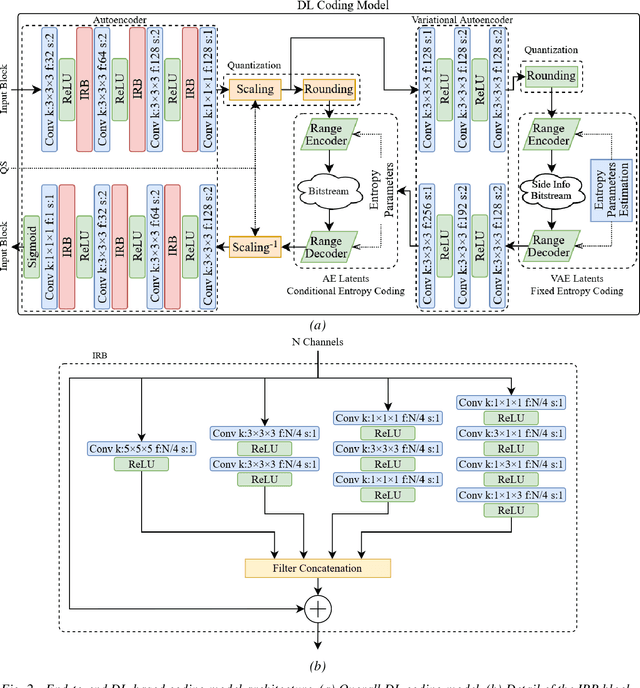
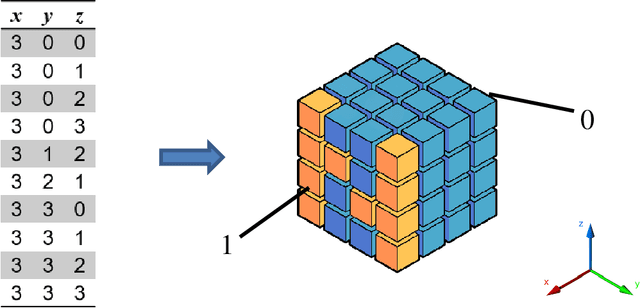
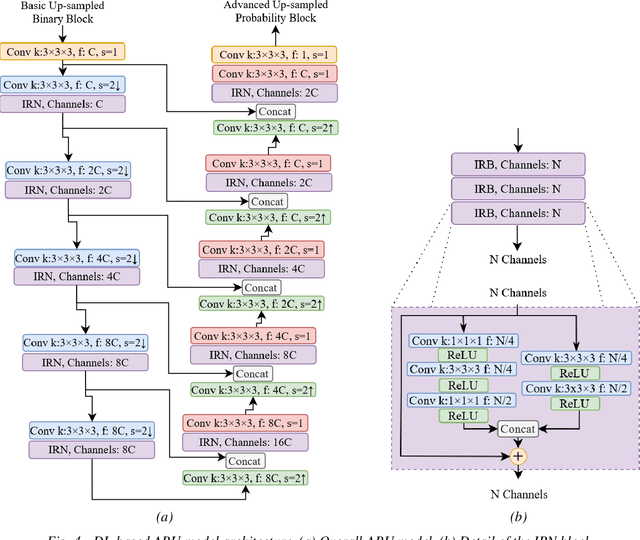
This document describes a deep learning-based point cloud geometry codec and a deep learning-based point cloud joint geometry and colour codec, submitted to the Call for Proposals on JPEG Pleno Point Cloud Coding issued in January 2022. The proposed codecs are based on recent developments in deep learning-based PC geometry coding and offer some of the key functionalities targeted by the Call for Proposals. The proposed geometry codec offers a compression efficiency that outperforms the MPEG G-PCC standard and outperforms or is competitive with the V-PCC Intra standard for the JPEG Call for Proposals test set; however, the same does not happen for the joint geometry and colour codec due to a quality saturation effect that needs to be overcome.