 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Augmentation Supported Contrastive Learning of Sentence Representations
Paper and Code



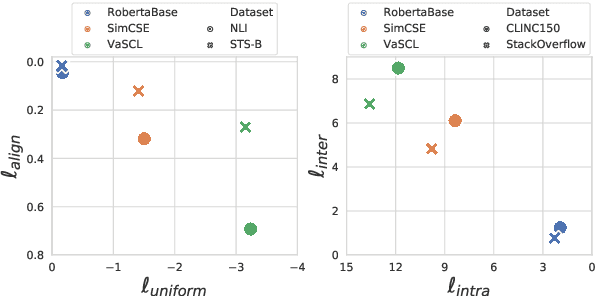
Despite profound successes, contrastive representation learning relies on carefully designed data augmentations using domain specific knowledge. This challenge is magnified in natural language processing where no general rules exist for data augmentation due to the discrete nature of natural language. We tackle this challenge by presenting a Virtual augmentation Supported Contrastive Learning of sentence representations (VaSCL). Originating from the interpretation that data augmentation essentially constructs the neighborhoods of each training instance, we in turn utilize the neighborhood to generate effective data augmentations. Leveraging the large training batch size of contrastive learning, we approximate the neighborhood of an instance via its K-nearest in-batch neighbors in the representation space. We then define an instance discrimination task within this neighborhood, and generate the virtual augmentation in an adversarial training manner. We access the performance of VaSCL on a wide range of downstream tasks, and set a new state-of-the-art for unsupervised sentence representation learning.