 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Restoration of Weather-affected Images using Deep Gaussian Process-based CycleGAN
Apr 23, 2022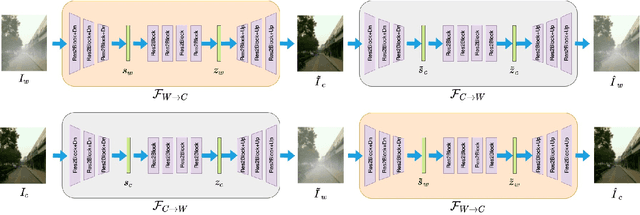



Existing approaches for restoring weather-degraded images follow a fully-supervised paradigm and they require paired data for training. However, collecting paired data for weather degradations is extremely challenging, and existing methods end up training on synthetic data. To overcome this issue, we describe an approach for supervising deep networks that are based on CycleGAN, thereby enabling the use of unlabeled real-world data for training. Specifically, we introduce new losses for training CycleGAN that lead to more effective training, resulting in high-quality reconstructions. These new losses are obtained by jointly modeling the latent space embeddings of predicted clean images and original clean images through Deep Gaussian Processes. This enables the CycleGAN architecture to transfer the knowledge from one domain (weather-degraded) to another (clean) more effectively. We demonstrate that the proposed method can be effectively applied to different restoration tasks like de-raining, de-hazing and de-snowing and it outperforms other unsupervised techniques (that leverage weather-based characteristics) by a considerable margin.
Unsupervised Domain Adaption of Object Detectors: A Survey
May 27, 2021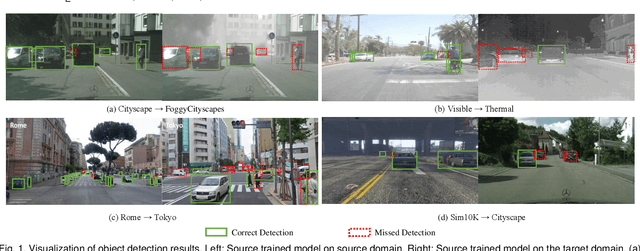
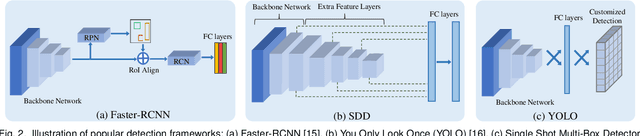
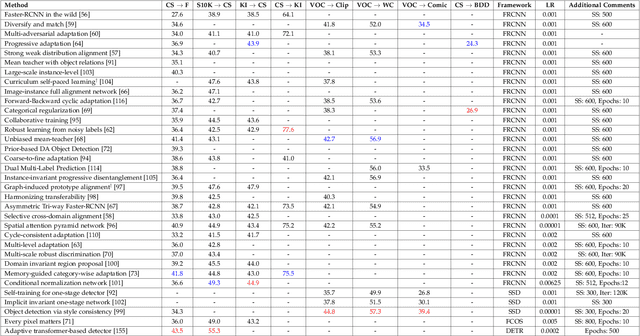
Recent advances in deep learning have led to the development of accurate and efficient models for various computer vision applications such as object classification, semantic segmentation, and object detection. However, learning highly accurate models relies on the availability of datasets with a large number of annotated images. Due to this, model performance drops drastically when evaluated on label-scarce datasets having visually distinct images. This issue is commonly referred to as covariate shift or dataset bias. Domain adaptation attempts to address this problem by leveraging domain shift characteristics from labeled data in a related domain when learning a classifier for label-scarce target dataset. There are a plethora of works to adapt object classification and semantic segmentation models to label-scarce target dataset through unsupervised domain adaptation. Considering that object detection is a fundamental task in computer vision, many recent works have recently focused on addressing the domain adaptation issue for object detection as well. In this paper, we provide a brief introduction to the domain adaptation problem for object detection and present an overview of various methods proposed to date for addressing this problem. Furthermore, we highlight strategies proposed for this problem and the associated shortcomings. Subsequently, we identify multiple aspects of the unsupervised domain adaptive detection problem that are most promising for future research in the area. We believe that this survey shall be valuable to the pattern recognition experts working in the fields of computer vision, biometrics, medical imaging, and autonomous navigation by introducing them to the problem, getting them familiar with the current status of the progress, and providing them with promising direction for future research.
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
Apr 03, 2021
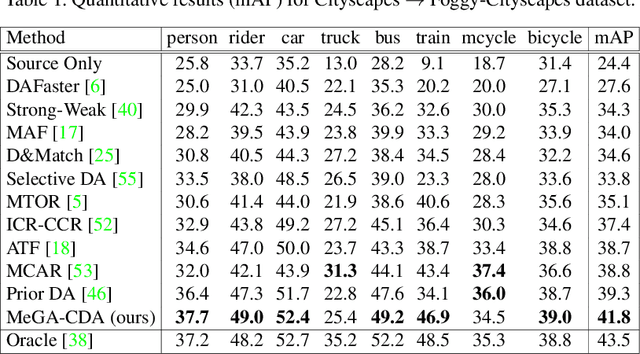
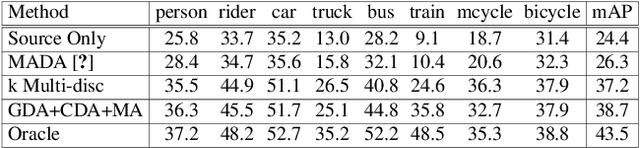
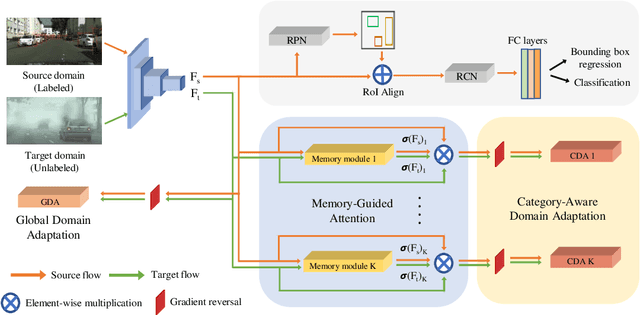
Existing approaches for unsupervised domain adaptive object detection perform feature alignment via adversarial training. While these methods achieve reasonable improvements in performance, they typically perform category-agnostic domain alignment, thereby resulting in negative transfer of features. To overcome this issue, in this work, we attempt to incorporate category information into the domain adaptation process by proposing Memory Guided Attention for Category-Aware Domain Adaptation (MeGA-CDA). The proposed method consists of employing category-wise discriminators to ensure category-aware feature alignment for learning domain-invariant discriminative features. However, since the category information is not available for the target samples, we propose to generate memory-guided category-specific attention maps which are then used to route the features appropriately to the corresponding category discriminator. The proposed method is evaluated on several benchmark datasets and is shown to outperform existing approaches.
KiU-Net: Overcomplete Convolutional Architectures for Biomedical Image and Volumetric Segmentation
Oct 04, 2020
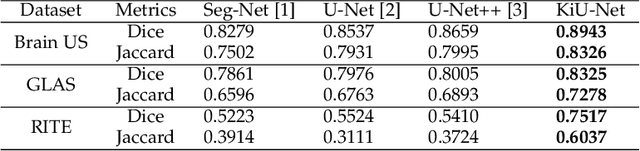


Most methods for medical image segmentation use U-Net or its variants as they have been successful in most of the applications. After a detailed analysis of these "traditional" encoder-decoder based approaches, we observed that they perform poorly in detecting smaller structures and are unable to segment boundary regions precisely. This issue can be attributed to the increase in receptive field size as we go deeper into the encoder. The extra focus on learning high level features causes the U-Net based approaches to learn less information about low-level features which are crucial for detecting small structures. To overcome this issue, we propose using an overcomplete convolutional architecture where we project our input image into a higher dimension such that we constrain the receptive field from increasing in the deep layers of the network. We design a new architecture for image segmentation- KiU-Net which has two branches: (1) an overcomplete convolutional network Kite-Net which learns to capture fine details and accurate edges of the input, and (2) U-Net which learns high level features. Furthermore, we also propose KiU-Net 3D which is a 3D convolutional architecture for volumetric segmentation. We perform a detailed study of KiU-Net by performing experiments on five different datasets covering various image modalities like ultrasound (US), magnetic resonance imaging (MRI), computed tomography (CT), microscopic and fundus images. The proposed method achieves a better performance as compared to all the recent methods with an additional benefit of fewer parameters and faster convergence. Additionally, we also demonstrate that the extensions of KiU-Net based on residual blocks and dense blocks result in further performance improvements. The implementation of KiU-Net can be found here: https://github.com/jeya-maria-jose/KiU-Net-pytorch
Completely Self-Supervised Crowd Counting via Distribution Matching
Sep 14, 2020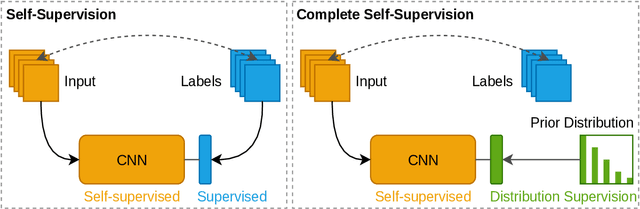
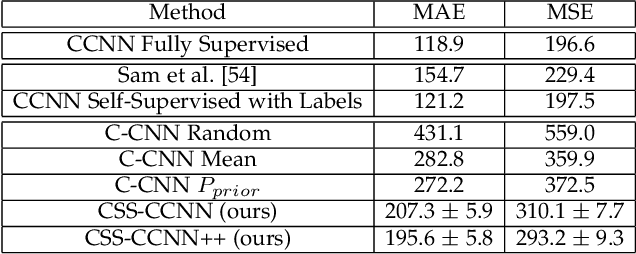
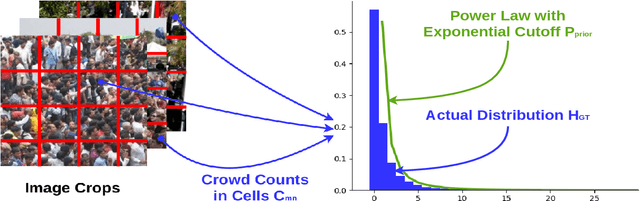
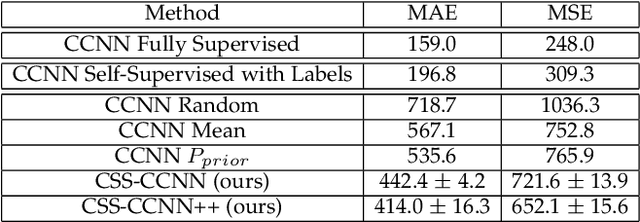
Dense crowd counting is a challenging task that demands millions of head annotations for training models. Though existing self-supervised approaches could learn good representations, they require some labeled data to map these features to the end task of density estimation. We mitigate this issue with the proposed paradigm of complete self-supervision, which does not need even a single labeled image. The only input required to train, apart from a large set of unlabeled crowd images, is the approximate upper limit of the crowd count for the given dataset. Our method dwells on the idea that natural crowds follow a power law distribution, which could be leveraged to yield error signals for backpropagation. A density regressor is first pretrained with self-supervision and then the distribution of predictions is matched to the prior by optimizing Sinkhorn distance between the two. Experiments show that this results in effective learning of crowd features and delivers significant counting performance. Furthermore, we establish the superiority of our method in less data setting as well. The code and models for our approach is available at https://github.com/val-iisc/css-ccnn.
Learning to Count in the Crowd from Limited Labeled Data
Jul 08, 2020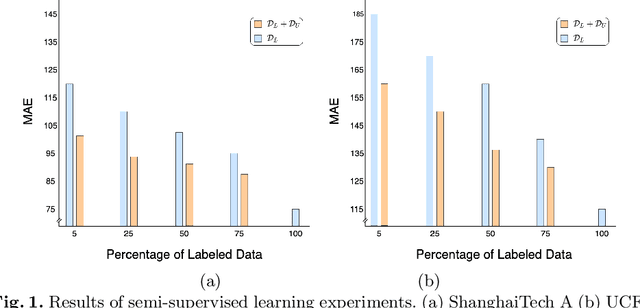

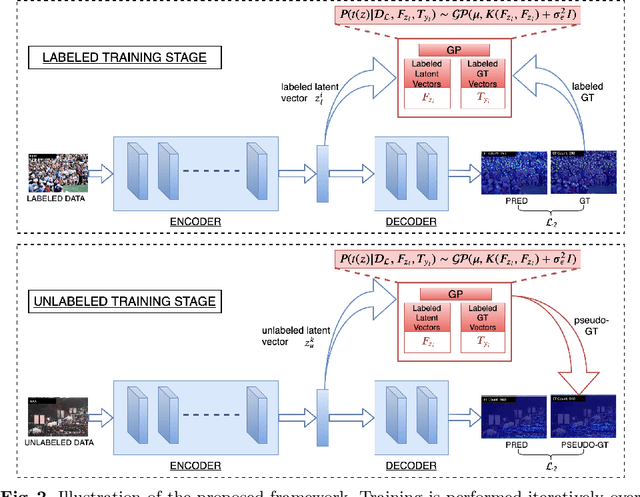
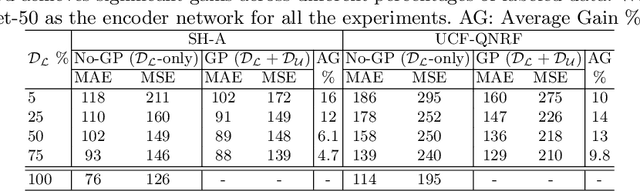
Recent crowd counting approaches have achieved excellent performance. However, they are essentially based on fully supervised paradigm and require large number of annotated samples. Obtaining annotations is an expensive and labour-intensive process. In this work, we focus on reducing the annotation efforts by learning to count in the crowd from limited number of labeled samples while leveraging a large pool of unlabeled data. Specifically, we propose a Gaussian Process-based iterative learning mechanism that involves estimation of pseudo-ground truth for the unlabeled data, which is then used as supervision for training the network. The proposed method is shown to be effective under the reduced data (semi-supervised) settings for several datasets like ShanghaiTech, UCF-QNRF, WorldExpo, UCSD, etc. Furthermore, we demonstrate that the proposed method can be leveraged to enable the network in learning to count from synthetic dataset while being able to generalize better to real-world datasets (synthetic-to-real transfer).
JHU-CROWD++: Large-Scale Crowd Counting Dataset and A Benchmark Method
Apr 07, 2020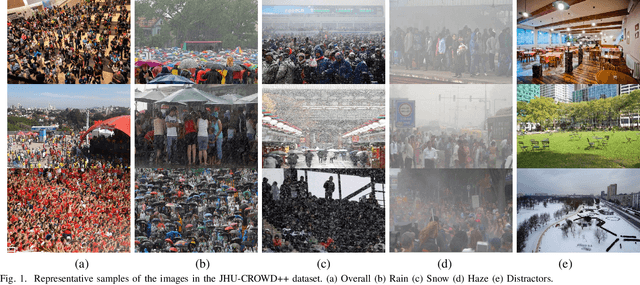
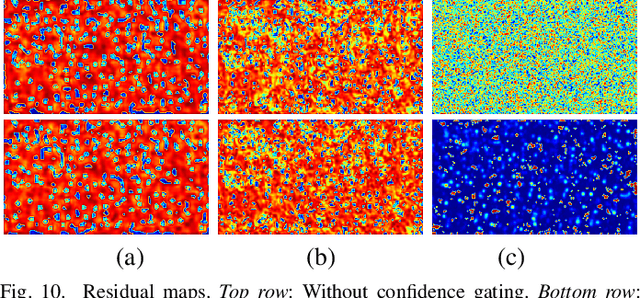
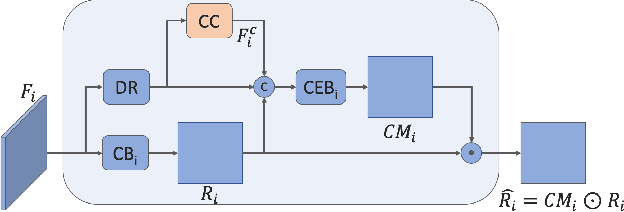

Due to its variety of applications in the real-world, the task of single image-based crowd counting has received a lot of interest in the recent years. Recently, several approaches have been proposed to address various problems encountered in crowd counting. These approaches are essentially based on convolutional neural networks that require large amounts of data to train the network parameters. Considering this, we introduce a new large scale unconstrained crowd counting dataset (JHU-CROWD++) that contains "4,372" images with "1.51 million" annotations. In comparison to existing datasets, the proposed dataset is collected under a variety of diverse scenarios and environmental conditions. Specifically, the dataset includes several images with weather-based degradations and illumination variations, making it a very challenging dataset. Additionally, the dataset consists of a rich set of annotations at both image-level and head-level. Several recent methods are evaluated and compared on this dataset. The dataset can be downloaded from http://www.crowd-counting.com . Furthermore, we propose a novel crowd counting network that progressively generates crowd density maps via residual error estimation. The proposed method uses VGG16 as the backbone network and employs density map generated by the final layer as a coarse prediction to refine and generate finer density maps in a progressive fashion using residual learning. Additionally, the residual learning is guided by an uncertainty-based confidence weighting mechanism that permits the flow of only high-confidence residuals in the refinement path. The proposed Confidence Guided Deep Residual Counting Network (CG-DRCN) is evaluated on recent complex datasets, and it achieves significant improvements in errors.
Prior-based Domain Adaptive Object Detection for Adverse Weather Conditions
Nov 29, 2019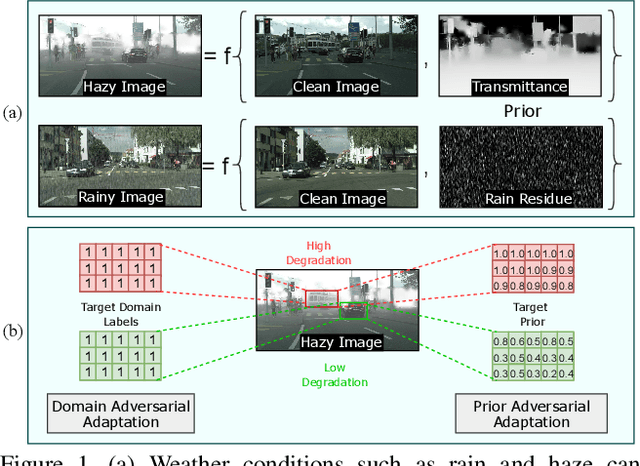
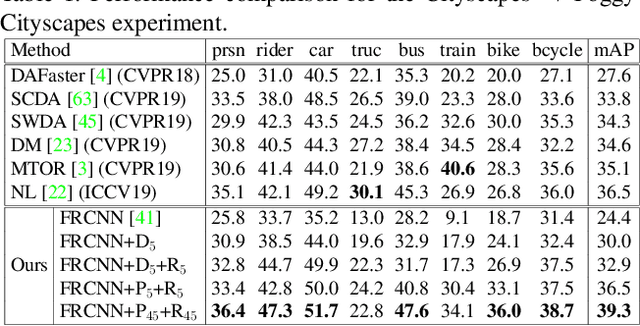
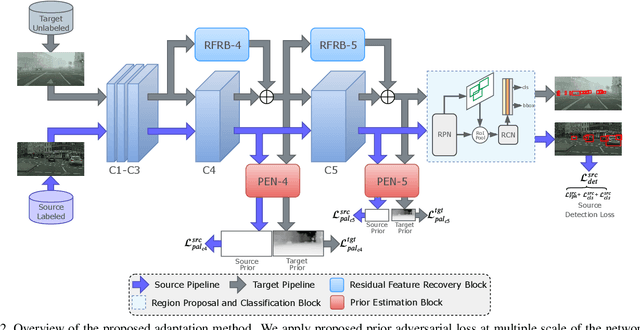
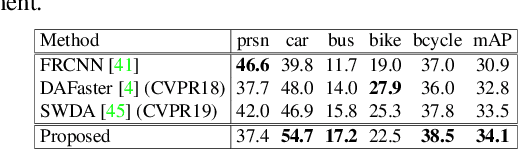
Adverse weather conditions such as rain and haze corrupt the quality of captured images, which cause detection networks trained on clean images to perform poorly on these images. To address this issue, we propose an unsupervised prior-based domain adversarial object detection framework for adapting the detectors to different weather conditions. We make the observations that corruptions due to different weather conditions (i) follow the principles of physics and hence, can be mathematically modeled, and (ii) often cause degradations in the feature space leading to deterioration in the detection performance. Motivated by these, we propose to use weather-specific prior knowledge obtained using the principles of image formation to define a novel prior-adversarial loss. The prior-adversarial loss used to train the adaptation process aims to produce weather-invariant features by reducing the weather-specific information in the features, thereby mitigating the effects of weather on the detection performance. Additionally, we introduce a set of residual feature recovery blocks in the object detection pipeline to de-distort the feature space, resulting in further improvements. The proposed framework outperforms all existing methods by a large margin when evaluated on different datasets such as Foggy-Cityscapes, Rainy-Cityscapes, RTTS and UFDD.
Pushing the Frontiers of Unconstrained Crowd Counting: New Dataset and Benchmark Method
Oct 28, 2019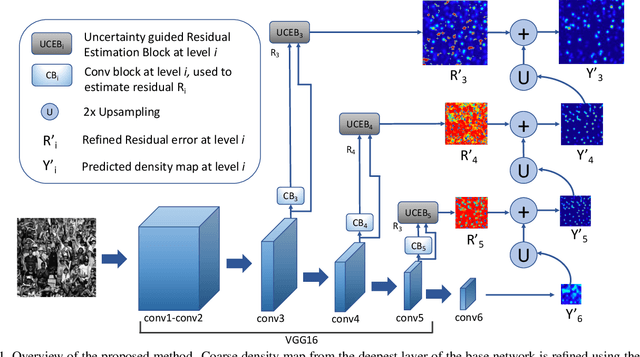



In this work, we propose a novel crowd counting network that progressively generates crowd density maps via residual error estimation. The proposed method uses VGG16 as the backbone network and employs density map generated by the final layer as a coarse prediction to refine and generate finer density maps in a progressive fashion using residual learning. Additionally, the residual learning is guided by an uncertainty-based confidence weighting mechanism that permits the flow of only high-confidence residuals in the refinement path. The proposed Confidence Guided Deep Residual Counting Network (CG-DRCN) is evaluated on recent complex datasets, and it achieves significant improvements in errors. Furthermore, we introduce a new large scale unconstrained crowd counting dataset (JHU-CROWD) that is ~2.8 larger than the most recent crowd counting datasets in terms of the number of images. It contains 4,250 images with 1.11 million annotations. In comparison to existing datasets, the proposed dataset is collected under a variety of diverse scenarios and environmental conditions. Specifically, the dataset includes several images with weather-based degradations and illumination variations in addition to many distractor images, making it a very challenging dataset. Additionally, the dataset consists of rich annotations at both image-level and head-level. Several recent methods are evaluated and compared on this dataset.
HA-CCN: Hierarchical Attention-based Crowd Counting Network
Jul 24, 2019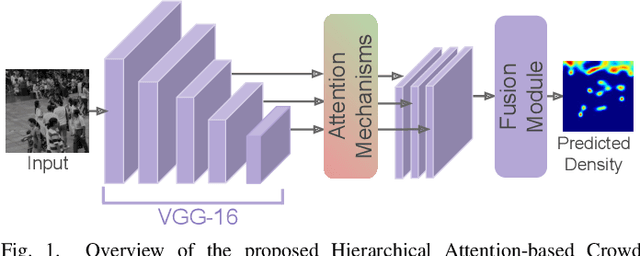

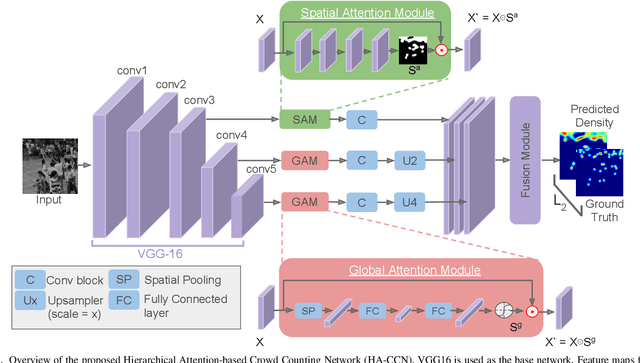
Single image-based crowd counting has recently witnessed increased focus, but many leading methods are far from optimal, especially in highly congested scenes. In this paper, we present Hierarchical Attention-based Crowd Counting Network (HA-CCN) that employs attention mechanisms at various levels to selectively enhance the features of the network. The proposed method, which is based on the VGG16 network, consists of a spatial attention module (SAM) and a set of global attention modules (GAM). SAM enhances low-level features in the network by infusing spatial segmentation information, whereas the GAM focuses on enhancing channel-wise information in the higher level layers. The proposed method is a single-step training framework, simple to implement and achieves state-of-the-art results on different datasets. Furthermore, we extend the proposed counting network by introducing a novel set-up to adapt the network to different scenes and datasets via weak supervision using image-level labels. This new set up reduces the burden of acquiring labour intensive point-wise annotations for new datasets while improving the cross-dataset performance.