 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletely Self-Supervised Crowd Counting via Distribution Matching
Sep 14, 2020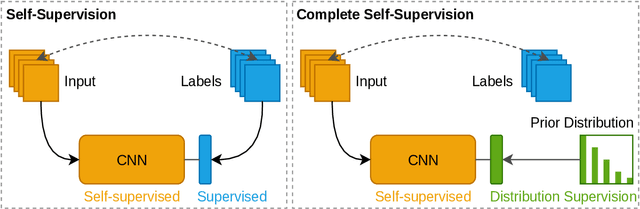
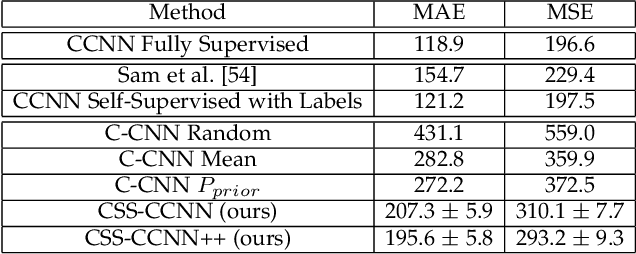
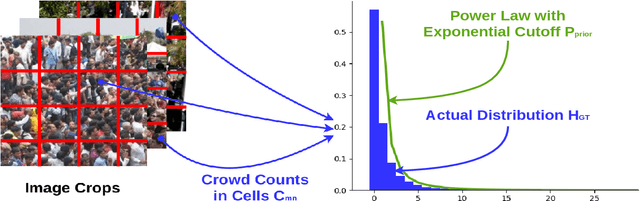
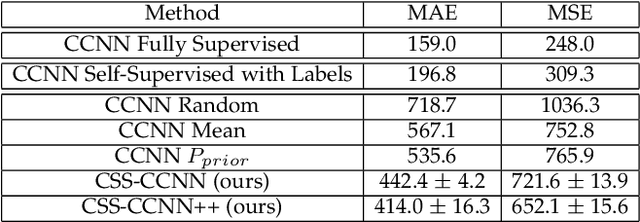
Dense crowd counting is a challenging task that demands millions of head annotations for training models. Though existing self-supervised approaches could learn good representations, they require some labeled data to map these features to the end task of density estimation. We mitigate this issue with the proposed paradigm of complete self-supervision, which does not need even a single labeled image. The only input required to train, apart from a large set of unlabeled crowd images, is the approximate upper limit of the crowd count for the given dataset. Our method dwells on the idea that natural crowds follow a power law distribution, which could be leveraged to yield error signals for backpropagation. A density regressor is first pretrained with self-supervision and then the distribution of predictions is matched to the prior by optimizing Sinkhorn distance between the two. Experiments show that this results in effective learning of crowd features and delivers significant counting performance. Furthermore, we establish the superiority of our method in less data setting as well. The code and models for our approach is available at https://github.com/val-iisc/css-ccnn.
Locate, Size and Count: Accurately Resolving People in Dense Crowds via Detection
Jun 21, 2019

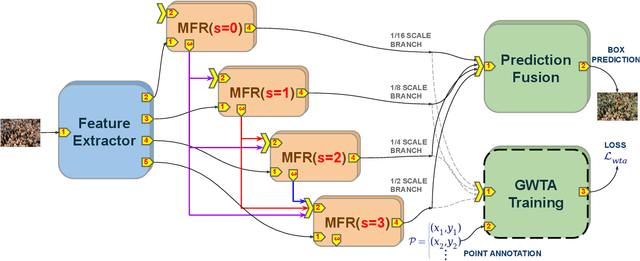
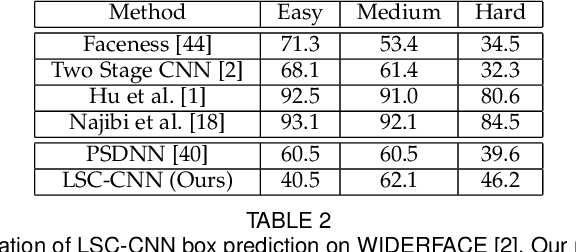
We introduce a detection framework for dense crowd counting and eliminate the need for the prevalent density regression paradigm. Typical counting models predict crowd density for an image as opposed to detecting every person. These regression methods, in general, fail to localize persons accurate enough for most applications other than counting. Hence, we adopt an architecture that locates every person in the crowd, sizes the spotted heads with bounding box and then counts them. Compared to normal object or face detectors, there exist certain unique challenges in designing such a detection system. Some of them are direct consequences of the huge diversity in dense crowds along with the need to predict boxes contiguously. We solve these issues and develop our LSC-CNN model, which can reliably detect heads of people across sparse to dense crowds. LSC-CNN employs a multi-column architecture with top-down feedback processing to better resolve persons and produce refined predictions at multiple resolutions. Interestingly, the proposed training regime requires only point head annotation, but can estimate approximate size information of heads. We show that LSC-CNN not only has superior localization than existing density regressors, but outperforms in counting as well. The code for our approach is available at https://github.com/val-iisc/lsc-cnn.
Top-Down Feedback for Crowd Counting Convolutional Neural Network
Jul 27, 2018
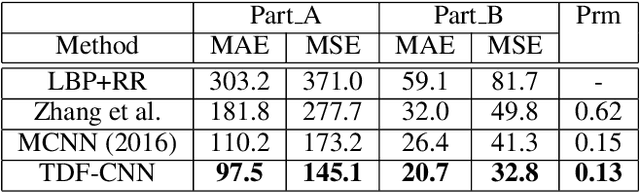
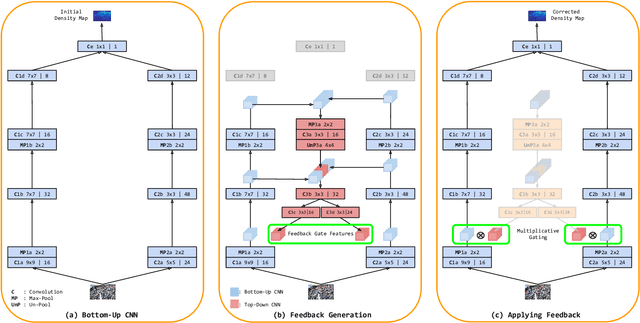
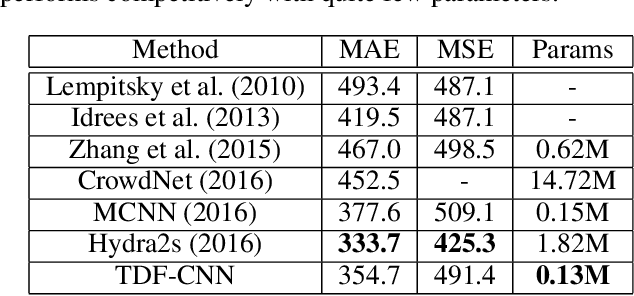
Counting people in dense crowds is a demanding task even for humans. This is primarily due to the large variability in appearance of people. Often people are only seen as a bunch of blobs. Occlusions, pose variations and background clutter further compound the difficulty. In this scenario, identifying a person requires larger spatial context and semantics of the scene. But the current state-of-the-art CNN regressors for crowd counting are feedforward and use only limited spatial context to detect people. They look for local crowd patterns to regress the crowd density map, resulting in false predictions. Hence, we propose top-down feedback to correct the initial prediction of the CNN. Our architecture consists of a bottom-up CNN along with a separate top-down CNN to generate feedback. The bottom-up network, which regresses the crowd density map, has two columns of CNN with different receptive fields. Features from various layers of the bottom-up CNN are fed to the top-down network. The feedback, thus generated, is applied on the lower layers of the bottom-up network in the form of multiplicative gating. This masking weighs activations of the bottom-up network at spatial as well as feature levels to correct the density prediction. We evaluate the performance of our model on all major crowd datasets and show the effectiveness of top-down feedback.
Divide and Grow: Capturing Huge Diversity in Crowd Images with Incrementally Growing CNN
Jul 26, 2018
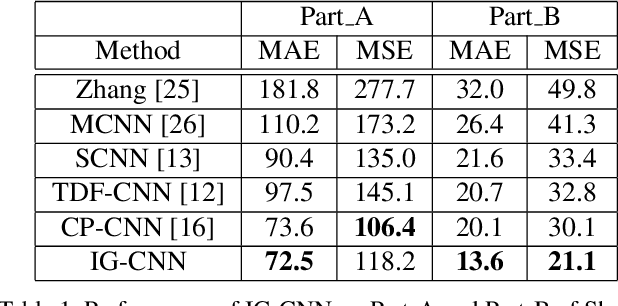
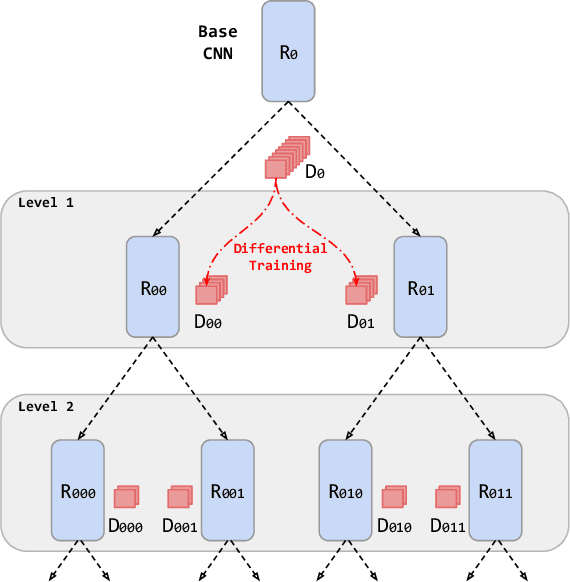

Automated counting of people in crowd images is a challenging task. The major difficulty stems from the large diversity in the way people appear in crowds. In fact, features available for crowd discrimination largely depend on the crowd density to the extent that people are only seen as blobs in a highly dense scene. We tackle this problem with a growing CNN which can progressively increase its capacity to account for the wide variability seen in crowd scenes. Our model starts from a base CNN density regressor, which is trained in equivalence on all types of crowd images. In order to adapt with the huge diversity, we create two child regressors which are exact copies of the base CNN. A differential training procedure divides the dataset into two clusters and fine-tunes the child networks on their respective specialties. Consequently, without any hand-crafted criteria for forming specialties, the child regressors become experts on certain types of crowds. The child networks are again split recursively, creating two experts at every division. This hierarchical training leads to a CNN tree, where the child regressors are more fine experts than any of their parents. The leaf nodes are taken as the final experts and a classifier network is then trained to predict the correct specialty for a given test image patch. The proposed model achieves higher count accuracy on major crowd datasets. Further, we analyse the characteristics of specialties mined automatically by our method.
Switching Convolutional Neural Network for Crowd Counting
Aug 03, 2017
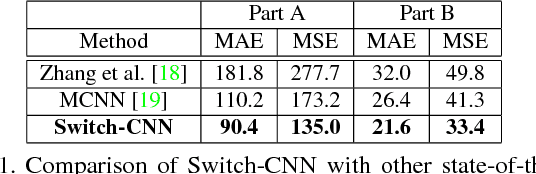

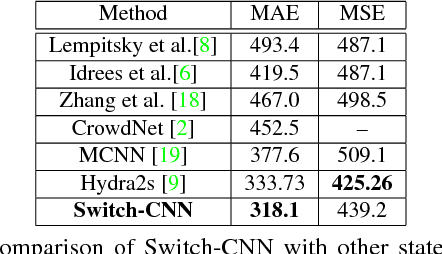
We propose a novel crowd counting model that maps a given crowd scene to its density. Crowd analysis is compounded by myriad of factors like inter-occlusion between people due to extreme crowding, high similarity of appearance between people and background elements, and large variability of camera view-points. Current state-of-the art approaches tackle these factors by using multi-scale CNN architectures, recurrent networks and late fusion of features from multi-column CNN with different receptive fields. We propose switching convolutional neural network that leverages variation of crowd density within an image to improve the accuracy and localization of the predicted crowd count. Patches from a grid within a crowd scene are relayed to independent CNN regressors based on crowd count prediction quality of the CNN established during training. The independent CNN regressors are designed to have different receptive fields and a switch classifier is trained to relay the crowd scene patch to the best CNN regressor. We perform extensive experiments on all major crowd counting datasets and evidence better performance compared to current state-of-the-art methods. We provide interpretable representations of the multichotomy of space of crowd scene patches inferred from the switch. It is observed that the switch relays an image patch to a particular CNN column based on density of crowd.