 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame of Sketches: Deep Recurrent Models of Pictionary-style Word Guessing
Jan 29, 2018
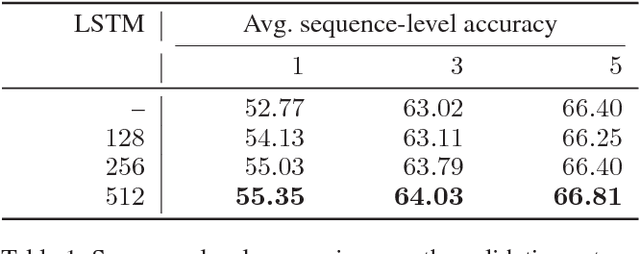
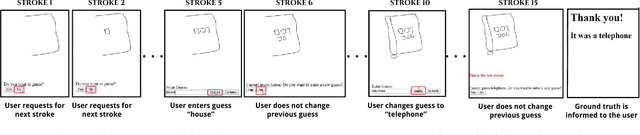
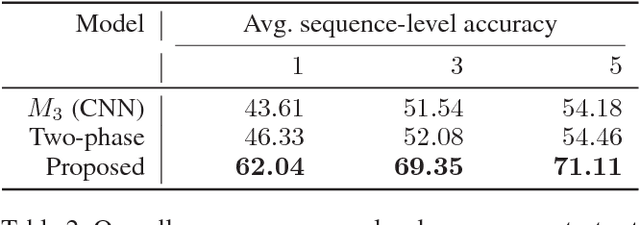
The ability of intelligent agents to play games in human-like fashion is popularly considered a benchmark of progress in Artificial Intelligence. Similarly, performance on multi-disciplinary tasks such as Visual Question Answering (VQA) is considered a marker for gauging progress in Computer Vision. In our work, we bring games and VQA together. Specifically, we introduce the first computational model aimed at Pictionary, the popular word-guessing social game. We first introduce Sketch-QA, an elementary version of Visual Question Answering task. Styled after Pictionary, Sketch-QA uses incrementally accumulated sketch stroke sequences as visual data. Notably, Sketch-QA involves asking a fixed question ("What object is being drawn?") and gathering open-ended guess-words from human guessers. We analyze the resulting dataset and present many interesting findings therein. To mimic Pictionary-style guessing, we subsequently propose a deep neural model which generates guess-words in response to temporally evolving human-drawn sketches. Our model even makes human-like mistakes while guessing, thus amplifying the human mimicry factor. We evaluate our model on the large-scale guess-word dataset generated via Sketch-QA task and compare with various baselines. We also conduct a Visual Turing Test to obtain human impressions of the guess-words generated by humans and our model. Experimental results demonstrate the promise of our approach for Pictionary and similarly themed games.
Switching Convolutional Neural Network for Crowd Counting
Aug 03, 2017
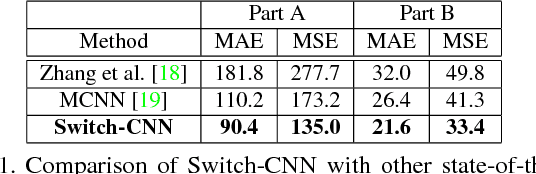

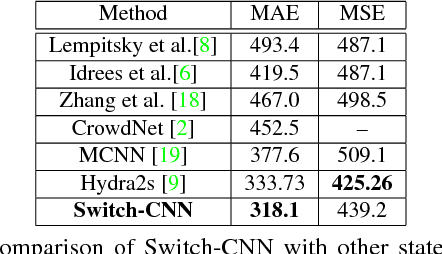
We propose a novel crowd counting model that maps a given crowd scene to its density. Crowd analysis is compounded by myriad of factors like inter-occlusion between people due to extreme crowding, high similarity of appearance between people and background elements, and large variability of camera view-points. Current state-of-the art approaches tackle these factors by using multi-scale CNN architectures, recurrent networks and late fusion of features from multi-column CNN with different receptive fields. We propose switching convolutional neural network that leverages variation of crowd density within an image to improve the accuracy and localization of the predicted crowd count. Patches from a grid within a crowd scene are relayed to independent CNN regressors based on crowd count prediction quality of the CNN established during training. The independent CNN regressors are designed to have different receptive fields and a switch classifier is trained to relay the crowd scene patch to the best CNN regressor. We perform extensive experiments on all major crowd counting datasets and evidence better performance compared to current state-of-the-art methods. We provide interpretable representations of the multichotomy of space of crowd scene patches inferred from the switch. It is observed that the switch relays an image patch to a particular CNN column based on density of crowd.
SwiDeN : Convolutional Neural Networks For Depiction Invariant Object Recognition
Jul 29, 2016

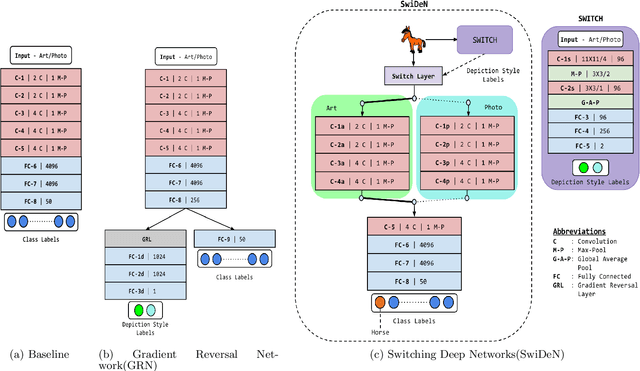
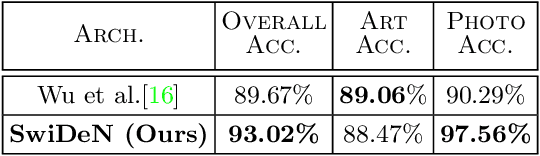
Current state of the art object recognition architectures achieve impressive performance but are typically specialized for a single depictive style (e.g. photos only, sketches only). In this paper, we present SwiDeN : our Convolutional Neural Network (CNN) architecture which recognizes objects regardless of how they are visually depicted (line drawing, realistic shaded drawing, photograph etc.). In SwiDeN, we utilize a novel `deep' depictive style-based switching mechanism which appropriately addresses the depiction-specific and depiction-invariant aspects of the problem. We compare SwiDeN with alternative architectures and prior work on a 50-category Photo-Art dataset containing objects depicted in multiple styles. Experimental results show that SwiDeN outperforms other approaches for the depiction-invariant object recognition problem.