 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdNet: A Deep Convolutional Network for Dense Crowd Counting
Aug 22, 2016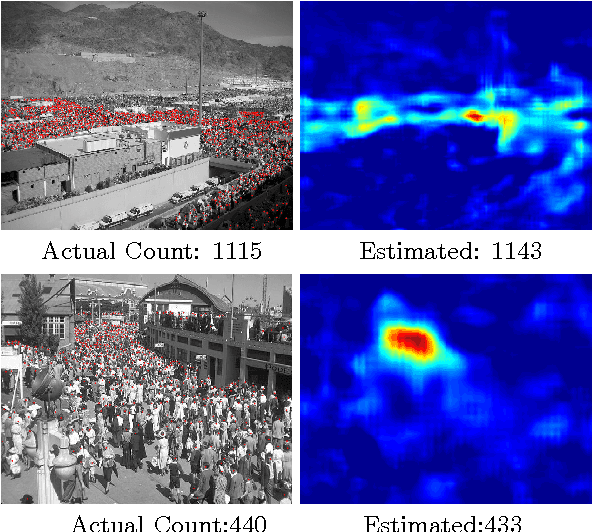

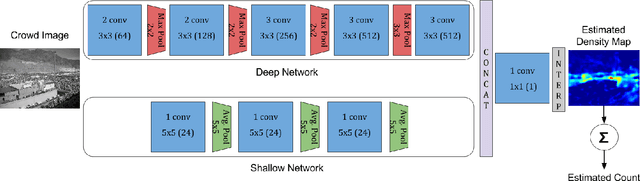
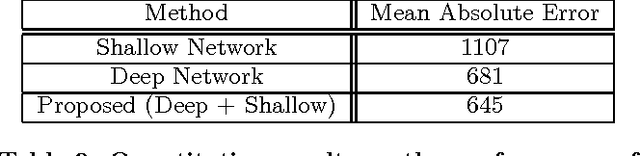
Our work proposes a novel deep learning framework for estimating crowd density from static images of highly dense crowds. We use a combination of deep and shallow, fully convolutional networks to predict the density map for a given crowd image. Such a combination is used for effectively capturing both the high-level semantic information (face/body detectors) and the low-level features (blob detectors), that are necessary for crowd counting under large scale variations. As most crowd datasets have limited training samples (<100 images) and deep learning based approaches require large amounts of training data, we perform multi-scale data augmentation. Augmenting the training samples in such a manner helps in guiding the CNN to learn scale invariant representations. Our method is tested on the challenging UCF_CC_50 dataset, and shown to outperform the state of the art methods.
SwiDeN : Convolutional Neural Networks For Depiction Invariant Object Recognition
Jul 29, 2016

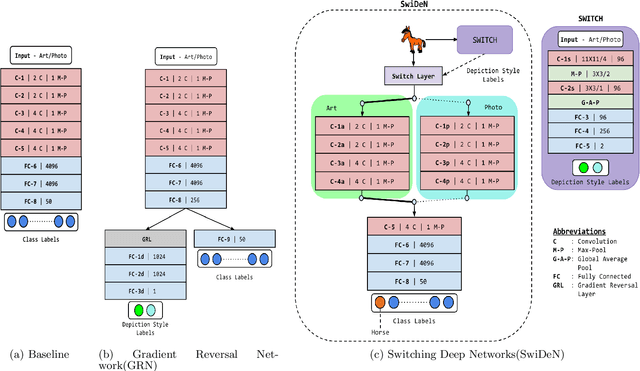
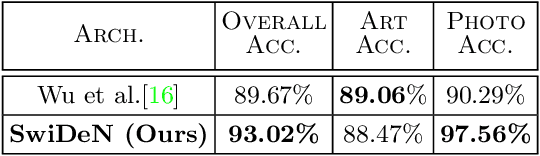
Current state of the art object recognition architectures achieve impressive performance but are typically specialized for a single depictive style (e.g. photos only, sketches only). In this paper, we present SwiDeN : our Convolutional Neural Network (CNN) architecture which recognizes objects regardless of how they are visually depicted (line drawing, realistic shaded drawing, photograph etc.). In SwiDeN, we utilize a novel `deep' depictive style-based switching mechanism which appropriately addresses the depiction-specific and depiction-invariant aspects of the problem. We compare SwiDeN with alternative architectures and prior work on a 50-category Photo-Art dataset containing objects depicted in multiple styles. Experimental results show that SwiDeN outperforms other approaches for the depiction-invariant object recognition problem.
A Taxonomy of Deep Convolutional Neural Nets for Computer Vision
Jan 25, 2016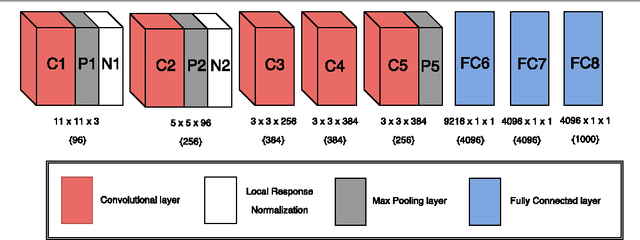
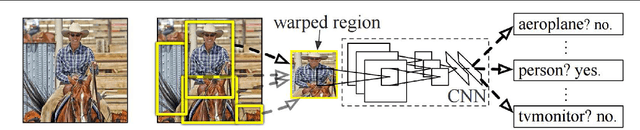
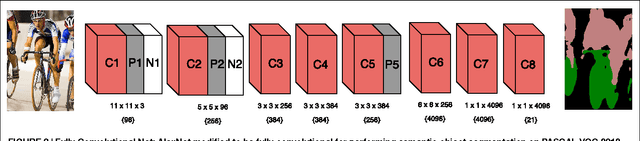
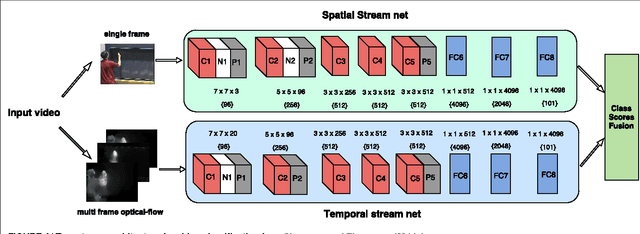
Traditional architectures for solving computer vision problems and the degree of success they enjoyed have been heavily reliant on hand-crafted features. However, of late, deep learning techniques have offered a compelling alternative -- that of automatically learning problem-specific features. With this new paradigm, every problem in computer vision is now being re-examined from a deep learning perspective. Therefore, it has become important to understand what kind of deep networks are suitable for a given problem. Although general surveys of this fast-moving paradigm (i.e. deep-networks) exist, a survey specific to computer vision is missing. We specifically consider one form of deep networks widely used in computer vision - convolutional neural networks (CNNs). We start with "AlexNet" as our base CNN and then examine the broad variations proposed over time to suit different applications. We hope that our recipe-style survey will serve as a guide, particularly for novice practitioners intending to use deep-learning techniques for computer vision.
* Published in Frontiers in Robotics and AI (http://goo.gl/6691Bm)