 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention when you need
Jan 13, 2025Being attentive to task-relevant features can improve task performance, but paying attention comes with its own metabolic cost. Therefore, strategic allocation of attention is crucial in performing the task efficiently. This work aims to understand this strategy. Recently, de Gee et al. conducted experiments involving mice performing an auditory sustained attention-value task. This task required the mice to exert attention to identify whether a high-order acoustic feature was present amid the noise. By varying the trial duration and reward magnitude, the task allows us to investigate how an agent should strategically deploy their attention to maximize their benefits and minimize their costs. In our work, we develop a reinforcement learning-based normative model of the mice to understand how it balances attention cost against its benefits. The model is such that at each moment the mice can choose between two levels of attention and decide when to take costly actions that could obtain rewards. Our model suggests that efficient use of attentional resources involves alternating blocks of high attention with blocks of low attention. In the extreme case where the agent disregards sensory input during low attention states, we see that high attention is used rhythmically. Our model provides evidence about how one should deploy attention as a function of task utility, signal statistics, and how attention affects sensory evidence.
Phase retrieval for Fourier Ptychography under varying amount of measurements
May 09, 2018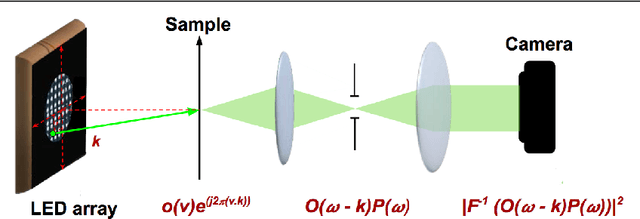



Fourier Ptychography is a recently proposed imaging technique that yields high-resolution images by computationally transcending the diffraction blur of an optical system. At the crux of this method is the phase retrieval algorithm, which is used for computationally stitching together low-resolution images taken under varying illumination angles of a coherent light source. However, the traditional iterative phase retrieval technique relies heavily on the initialization and also need a good amount of overlap in the Fourier domain for the successively captured low-resolution images, thus increasing the acquisition time and data. We show that an auto-encoder based architecture can be adaptively trained for phase retrieval under both low overlap, where traditional techniques completely fail, and at higher levels of overlap. For the low overlap case we show that a supervised deep learning technique using an autoencoder generator is a good choice for solving the Fourier ptychography problem. And for the high overlap case, we show that optimizing the generator for reducing the forward model error is an appropriate choice. Using simulations for the challenging case of uncorrelated phase and amplitude, we show that our method outperforms many of the previously proposed Fourier ptychography phase retrieval techniques.
Compensating for Large In-Plane Rotations in Natural Images
Nov 17, 2016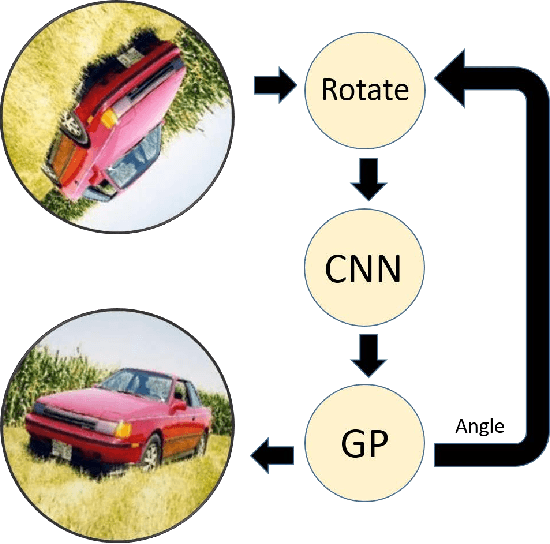
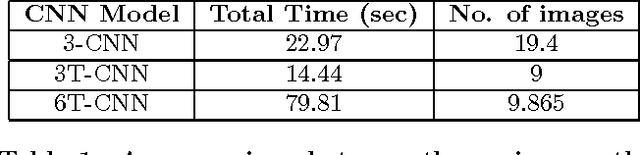

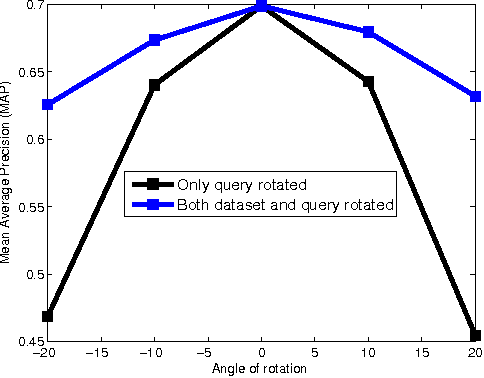
Rotation invariance has been studied in the computer vision community primarily in the context of small in-plane rotations. This is usually achieved by building invariant image features. However, the problem of achieving invariance for large rotation angles remains largely unexplored. In this work, we tackle this problem by directly compensating for large rotations, as opposed to building invariant features. This is inspired by the neuro-scientific concept of mental rotation, which humans use to compare pairs of rotated objects. Our contributions here are three-fold. First, we train a Convolutional Neural Network (CNN) to detect image rotations. We find that generic CNN architectures are not suitable for this purpose. To this end, we introduce a convolutional template layer, which learns representations for canonical 'unrotated' images. Second, we use Bayesian Optimization to quickly sift through a large number of candidate images to find the canonical 'unrotated' image. Third, we use this method to achieve robustness to large angles in an image retrieval scenario. Our method is task-agnostic, and can be used as a pre-processing step in any computer vision system.
CrowdNet: A Deep Convolutional Network for Dense Crowd Counting
Aug 22, 2016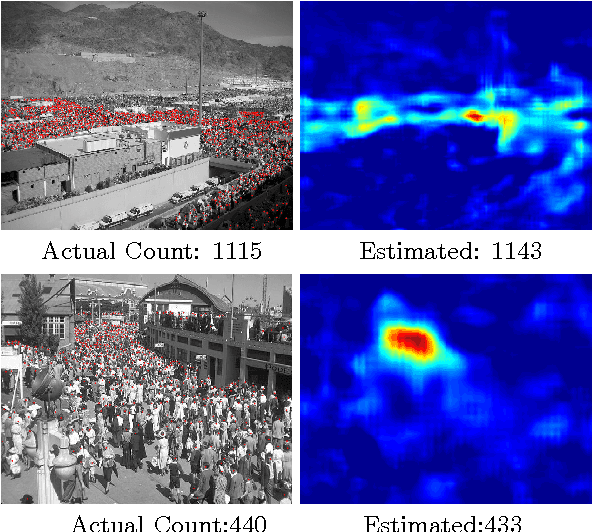

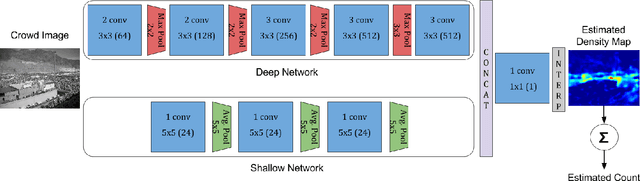
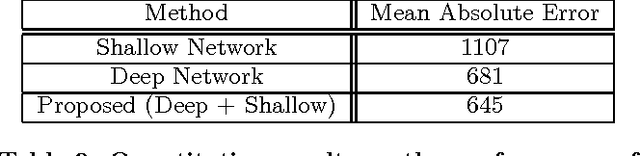
Our work proposes a novel deep learning framework for estimating crowd density from static images of highly dense crowds. We use a combination of deep and shallow, fully convolutional networks to predict the density map for a given crowd image. Such a combination is used for effectively capturing both the high-level semantic information (face/body detectors) and the low-level features (blob detectors), that are necessary for crowd counting under large scale variations. As most crowd datasets have limited training samples (<100 images) and deep learning based approaches require large amounts of training data, we perform multi-scale data augmentation. Augmenting the training samples in such a manner helps in guiding the CNN to learn scale invariant representations. Our method is tested on the challenging UCF_CC_50 dataset, and shown to outperform the state of the art methods.