 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniC-Lift: Unified 3D Instance Segmentation via Contrastive Learning
Dec 31, 20253D Gaussian Splatting (3DGS) and Neural Radiance Fields (NeRF) have advanced novel-view synthesis. Recent methods extend multi-view 2D segmentation to 3D, enabling instance/semantic segmentation for better scene understanding. A key challenge is the inconsistency of 2D instance labels across views, leading to poor 3D predictions. Existing methods use a two-stage approach in which some rely on contrastive learning with hyperparameter-sensitive clustering, while others preprocess labels for consistency. We propose a unified framework that merges these steps, reducing training time and improving performance by introducing a learnable feature embedding for segmentation in Gaussian primitives. This embedding is then efficiently decoded into instance labels through a novel "Embedding-to-Label" process, effectively integrating the optimization. While this unified framework offers substantial benefits, we observed artifacts at the object boundaries. To address the object boundary issues, we propose hard-mining samples along these boundaries. However, directly applying hard mining to the feature embeddings proved unstable. Therefore, we apply a linear layer to the rasterized feature embeddings before calculating the triplet loss, which stabilizes training and significantly improves performance. Our method outperforms baselines qualitatively and quantitatively on the ScanNet, Replica3D, and Messy-Rooms datasets.
Selective Mixup Fine-Tuning for Optimizing Non-Decomposable Objectives
Mar 27, 2024The rise in internet usage has led to the generation of massive amounts of data, resulting in the adoption of various supervised and semi-supervised machine learning algorithms, which can effectively utilize the colossal amount of data to train models. However, before deploying these models in the real world, these must be strictly evaluated on performance measures like worst-case recall and satisfy constraints such as fairness. We find that current state-of-the-art empirical techniques offer sub-optimal performance on these practical, non-decomposable performance objectives. On the other hand, the theoretical techniques necessitate training a new model from scratch for each performance objective. To bridge the gap, we propose SelMix, a selective mixup-based inexpensive fine-tuning technique for pre-trained models, to optimize for the desired objective. The core idea of our framework is to determine a sampling distribution to perform a mixup of features between samples from particular classes such that it optimizes the given objective. We comprehensively evaluate our technique against the existing empirical and theoretically principled methods on standard benchmark datasets for imbalanced classification. We find that proposed SelMix fine-tuning significantly improves the performance for various practical non-decomposable objectives across benchmarks.
Cost-Sensitive Self-Training for Optimizing Non-Decomposable Metrics
Apr 28, 2023Self-training based semi-supervised learning algorithms have enabled the learning of highly accurate deep neural networks, using only a fraction of labeled data. However, the majority of work on self-training has focused on the objective of improving accuracy, whereas practical machine learning systems can have complex goals (e.g. maximizing the minimum of recall across classes, etc.) that are non-decomposable in nature. In this work, we introduce the Cost-Sensitive Self-Training (CSST) framework which generalizes the self-training-based methods for optimizing non-decomposable metrics. We prove that our framework can better optimize the desired non-decomposable metric utilizing unlabeled data, under similar data distribution assumptions made for the analysis of self-training. Using the proposed CSST framework, we obtain practical self-training methods (for both vision and NLP tasks) for optimizing different non-decomposable metrics using deep neural networks. Our results demonstrate that CSST achieves an improvement over the state-of-the-art in majority of the cases across datasets and objectives.
Game of Sketches: Deep Recurrent Models of Pictionary-style Word Guessing
Jan 29, 2018
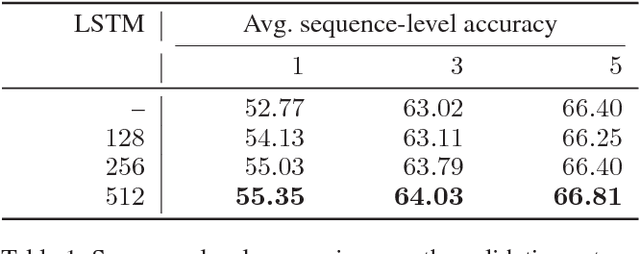
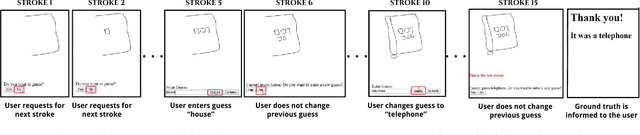
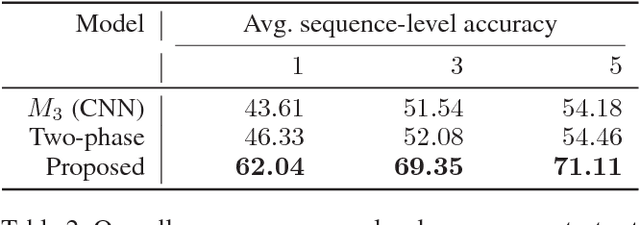
The ability of intelligent agents to play games in human-like fashion is popularly considered a benchmark of progress in Artificial Intelligence. Similarly, performance on multi-disciplinary tasks such as Visual Question Answering (VQA) is considered a marker for gauging progress in Computer Vision. In our work, we bring games and VQA together. Specifically, we introduce the first computational model aimed at Pictionary, the popular word-guessing social game. We first introduce Sketch-QA, an elementary version of Visual Question Answering task. Styled after Pictionary, Sketch-QA uses incrementally accumulated sketch stroke sequences as visual data. Notably, Sketch-QA involves asking a fixed question ("What object is being drawn?") and gathering open-ended guess-words from human guessers. We analyze the resulting dataset and present many interesting findings therein. To mimic Pictionary-style guessing, we subsequently propose a deep neural model which generates guess-words in response to temporally evolving human-drawn sketches. Our model even makes human-like mistakes while guessing, thus amplifying the human mimicry factor. We evaluate our model on the large-scale guess-word dataset generated via Sketch-QA task and compare with various baselines. We also conduct a Visual Turing Test to obtain human impressions of the guess-words generated by humans and our model. Experimental results demonstrate the promise of our approach for Pictionary and similarly themed games.
DeLiGAN : Generative Adversarial Networks for Diverse and Limited Data
Jun 07, 2017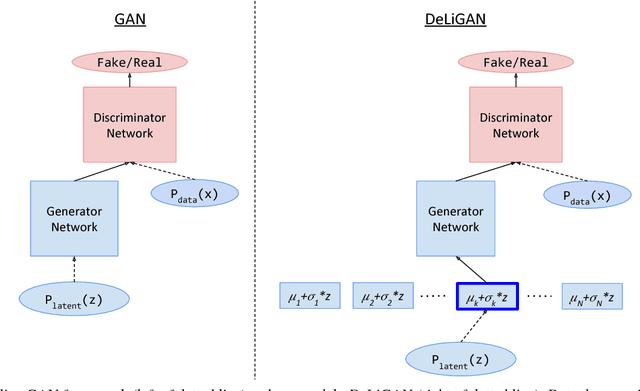



A class of recent approaches for generating images, called Generative Adversarial Networks (GAN), have been used to generate impressively realistic images of objects, bedrooms, handwritten digits and a variety of other image modalities. However, typical GAN-based approaches require large amounts of training data to capture the diversity across the image modality. In this paper, we propose DeLiGAN -- a novel GAN-based architecture for diverse and limited training data scenarios. In our approach, we reparameterize the latent generative space as a mixture model and learn the mixture model's parameters along with those of GAN. This seemingly simple modification to the GAN framework is surprisingly effective and results in models which enable diversity in generated samples although trained with limited data. In our work, we show that DeLiGAN can generate images of handwritten digits, objects and hand-drawn sketches, all using limited amounts of data. To quantitatively characterize intra-class diversity of generated samples, we also introduce a modified version of "inception-score", a measure which has been found to correlate well with human assessment of generated samples.