 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tail Temporal Action Segmentation with Group-wise Temporal Logit Adjustment
Aug 19, 2024
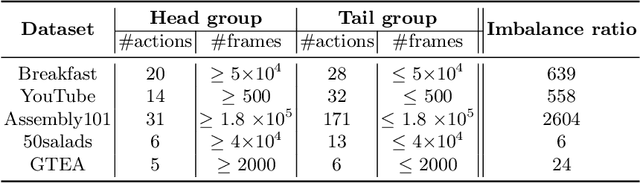
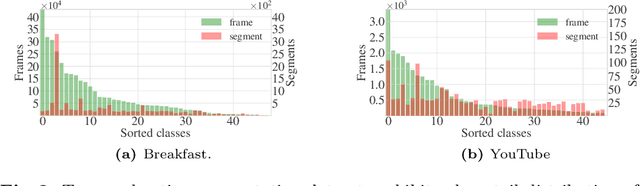
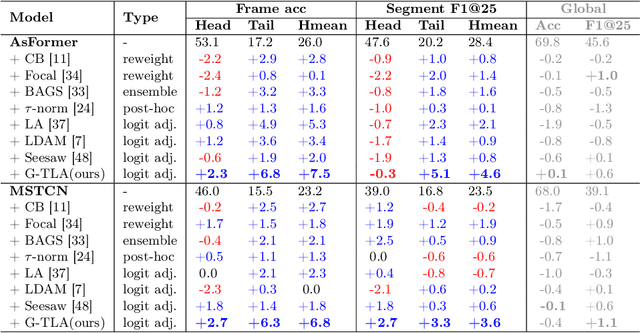
Procedural activity videos often exhibit a long-tailed action distribution due to varying action frequencies and durations. However, state-of-the-art temporal action segmentation methods overlook the long tail and fail to recognize tail actions. Existing long-tail methods make class-independent assumptions and struggle to identify tail classes when applied to temporal segmentation frameworks. This work proposes a novel group-wise temporal logit adjustment~(G-TLA) framework that combines a group-wise softmax formulation while leveraging activity information and action ordering for logit adjustment. The proposed framework significantly improves in segmenting tail actions without any performance loss on head actions.
Semantic Graph Consistency: Going Beyond Patches for Regularizing Self-Supervised Vision Transformers
Jun 18, 2024
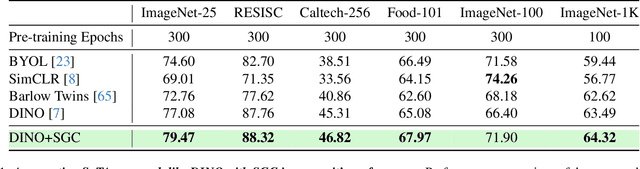

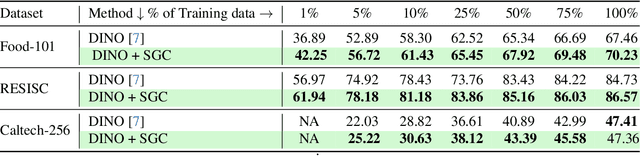
Self-supervised learning (SSL) with vision transformers (ViTs) has proven effective for representation learning as demonstrated by the impressive performance on various downstream tasks. Despite these successes, existing ViT-based SSL architectures do not fully exploit the ViT backbone, particularly the patch tokens of the ViT. In this paper, we introduce a novel Semantic Graph Consistency (SGC) module to regularize ViT-based SSL methods and leverage patch tokens effectively. We reconceptualize images as graphs, with image patches as nodes and infuse relational inductive biases by explicit message passing using Graph Neural Networks into the SSL framework. Our SGC loss acts as a regularizer, leveraging the underexploited patch tokens of ViTs to construct a graph and enforcing consistency between graph features across multiple views of an image. Extensive experiments on various datasets including ImageNet, RESISC and Food-101 show that our approach significantly improves the quality of learned representations, resulting in a 5-10\% increase in performance when limited labeled data is used for linear evaluation. These experiments coupled with a comprehensive set of ablations demonstrate the promise of our approach in various settings.
Selective Mixup Fine-Tuning for Optimizing Non-Decomposable Objectives
Mar 27, 2024The rise in internet usage has led to the generation of massive amounts of data, resulting in the adoption of various supervised and semi-supervised machine learning algorithms, which can effectively utilize the colossal amount of data to train models. However, before deploying these models in the real world, these must be strictly evaluated on performance measures like worst-case recall and satisfy constraints such as fairness. We find that current state-of-the-art empirical techniques offer sub-optimal performance on these practical, non-decomposable performance objectives. On the other hand, the theoretical techniques necessitate training a new model from scratch for each performance objective. To bridge the gap, we propose SelMix, a selective mixup-based inexpensive fine-tuning technique for pre-trained models, to optimize for the desired objective. The core idea of our framework is to determine a sampling distribution to perform a mixup of features between samples from particular classes such that it optimizes the given objective. We comprehensively evaluate our technique against the existing empirical and theoretically principled methods on standard benchmark datasets for imbalanced classification. We find that proposed SelMix fine-tuning significantly improves the performance for various practical non-decomposable objectives across benchmarks.
Cost-Sensitive Self-Training for Optimizing Non-Decomposable Metrics
Apr 28, 2023Self-training based semi-supervised learning algorithms have enabled the learning of highly accurate deep neural networks, using only a fraction of labeled data. However, the majority of work on self-training has focused on the objective of improving accuracy, whereas practical machine learning systems can have complex goals (e.g. maximizing the minimum of recall across classes, etc.) that are non-decomposable in nature. In this work, we introduce the Cost-Sensitive Self-Training (CSST) framework which generalizes the self-training-based methods for optimizing non-decomposable metrics. We prove that our framework can better optimize the desired non-decomposable metric utilizing unlabeled data, under similar data distribution assumptions made for the analysis of self-training. Using the proposed CSST framework, we obtain practical self-training methods (for both vision and NLP tasks) for optimizing different non-decomposable metrics using deep neural networks. Our results demonstrate that CSST achieves an improvement over the state-of-the-art in majority of the cases across datasets and objectives.