 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Semantic Graph Consistency: Going Beyond Patches for Regularizing Self-Supervised Vision Transformers
Jun 18, 2024
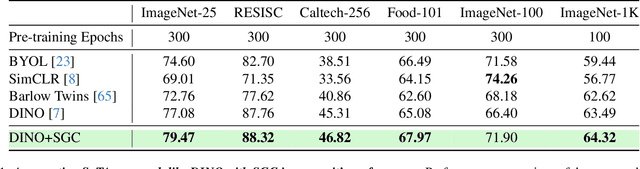

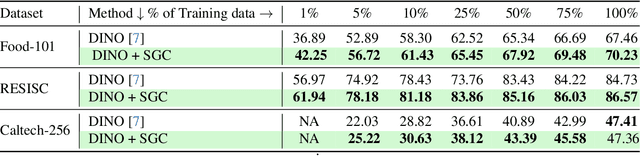
Self-supervised learning (SSL) with vision transformers (ViTs) has proven effective for representation learning as demonstrated by the impressive performance on various downstream tasks. Despite these successes, existing ViT-based SSL architectures do not fully exploit the ViT backbone, particularly the patch tokens of the ViT. In this paper, we introduce a novel Semantic Graph Consistency (SGC) module to regularize ViT-based SSL methods and leverage patch tokens effectively. We reconceptualize images as graphs, with image patches as nodes and infuse relational inductive biases by explicit message passing using Graph Neural Networks into the SSL framework. Our SGC loss acts as a regularizer, leveraging the underexploited patch tokens of ViTs to construct a graph and enforcing consistency between graph features across multiple views of an image. Extensive experiments on various datasets including ImageNet, RESISC and Food-101 show that our approach significantly improves the quality of learned representations, resulting in a 5-10\% increase in performance when limited labeled data is used for linear evaluation. These experiments coupled with a comprehensive set of ablations demonstrate the promise of our approach in various settings.
Leveraging the Third Dimension in Contrastive Learning
Jan 27, 2023
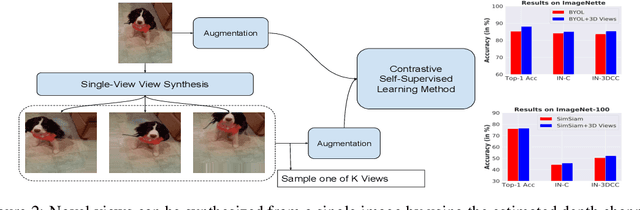


Self-Supervised Learning (SSL) methods operate on unlabeled data to learn robust representations useful for downstream tasks. Most SSL methods rely on augmentations obtained by transforming the 2D image pixel map. These augmentations ignore the fact that biological vision takes place in an immersive three-dimensional, temporally contiguous environment, and that low-level biological vision relies heavily on depth cues. Using a signal provided by a pretrained state-of-the-art monocular RGB-to-depth model (the \emph{Depth Prediction Transformer}, Ranftl et al., 2021), we explore two distinct approaches to incorporating depth signals into the SSL framework. First, we evaluate contrastive learning using an RGB+depth input representation. Second, we use the depth signal to generate novel views from slightly different camera positions, thereby producing a 3D augmentation for contrastive learning. We evaluate these two approaches on three different SSL methods -- BYOL, SimSiam, and SwAV -- using ImageNette (10 class subset of ImageNet), ImageNet-100 and ImageNet-1k datasets. We find that both approaches to incorporating depth signals improve the robustness and generalization of the baseline SSL methods, though the first approach (with depth-channel concatenation) is superior. For instance, BYOL with the additional depth channel leads to an increase in downstream classification accuracy from 85.3\% to 88.0\% on ImageNette and 84.1\% to 87.0\% on ImageNet-C.