 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-Down Feedback for Crowd Counting Convolutional Neural Network
Paper and Code
Jul 27, 2018
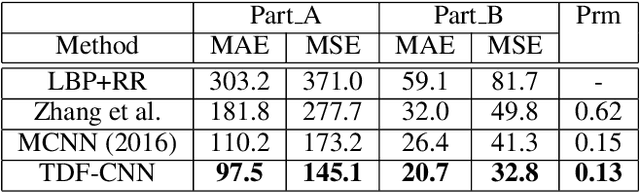
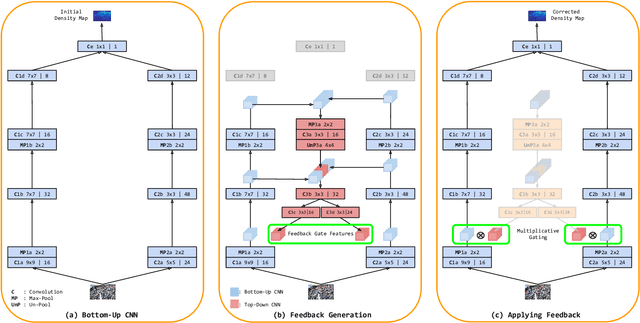
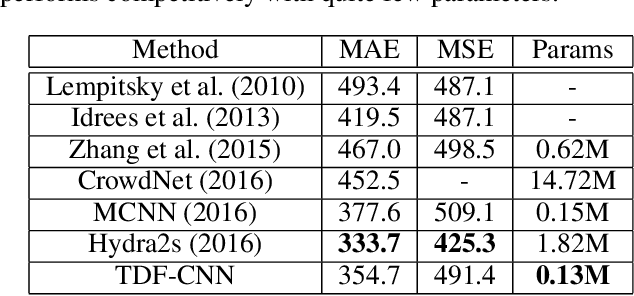
Counting people in dense crowds is a demanding task even for humans. This is primarily due to the large variability in appearance of people. Often people are only seen as a bunch of blobs. Occlusions, pose variations and background clutter further compound the difficulty. In this scenario, identifying a person requires larger spatial context and semantics of the scene. But the current state-of-the-art CNN regressors for crowd counting are feedforward and use only limited spatial context to detect people. They look for local crowd patterns to regress the crowd density map, resulting in false predictions. Hence, we propose top-down feedback to correct the initial prediction of the CNN. Our architecture consists of a bottom-up CNN along with a separate top-down CNN to generate feedback. The bottom-up network, which regresses the crowd density map, has two columns of CNN with different receptive fields. Features from various layers of the bottom-up CNN are fed to the top-down network. The feedback, thus generated, is applied on the lower layers of the bottom-up network in the form of multiplicative gating. This masking weighs activations of the bottom-up network at spatial as well as feature levels to correct the density prediction. We evaluate the performance of our model on all major crowd datasets and show the effectiveness of top-down feedback.