 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition
Feb 18, 2020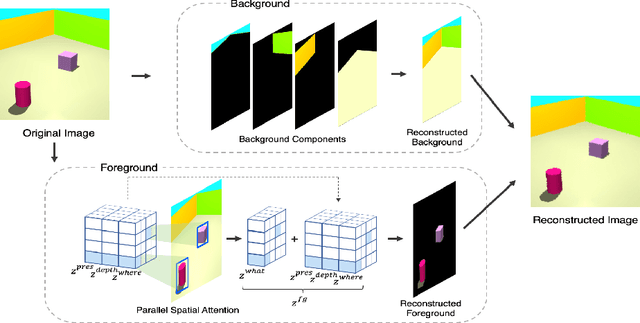
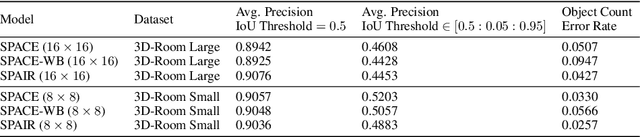
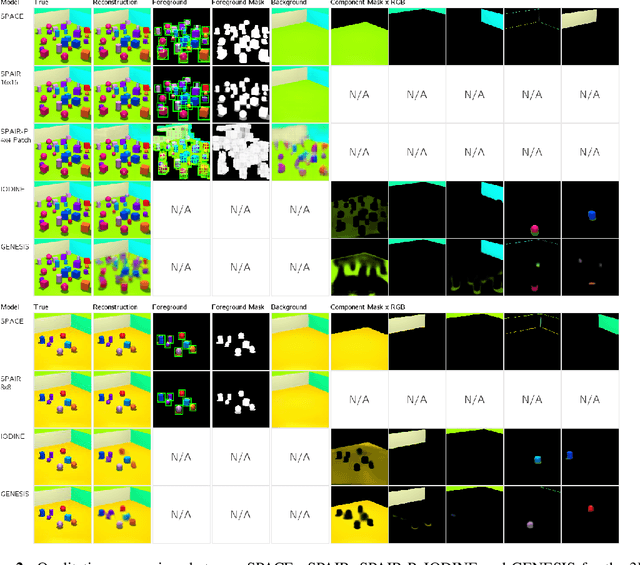
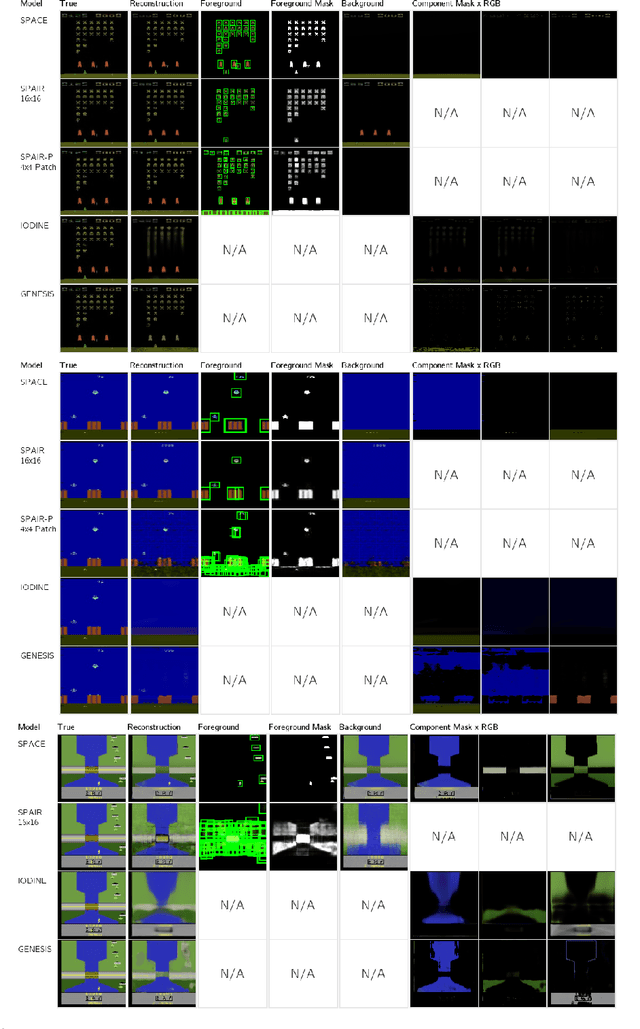
The ability to decompose complex multi-object scenes into meaningful abstractions like objects is fundamental to achieve higher-level cognition. Previous approaches for unsupervised object-oriented scene representation learning are either based on spatial-attention or scene-mixture approaches and limited in scalability which is a main obstacle towards modeling real-world scenes. In this paper, we propose a generative latent variable model, called SPACE, that provides a unified probabilistic modeling framework that combines the best of spatial-attention and scene-mixture approaches. SPACE can explicitly provide factorized object representations for foreground objects while also decomposing background segments of complex morphology. Previous models are good at either of these, but not both. SPACE also resolves the scalability problems of previous methods by incorporating parallel spatial-attention and thus is applicable to scenes with a large number of objects without performance degradations. We show through experiments on Atari and 3D-Rooms that SPACE achieves the above properties consistently in comparison to SPAIR, IODINE, and GENESIS. Results of our experiments can be found on our project website: https://sites.google.com/view/space-project-page
Locate, Size and Count: Accurately Resolving People in Dense Crowds via Detection
Jun 21, 2019

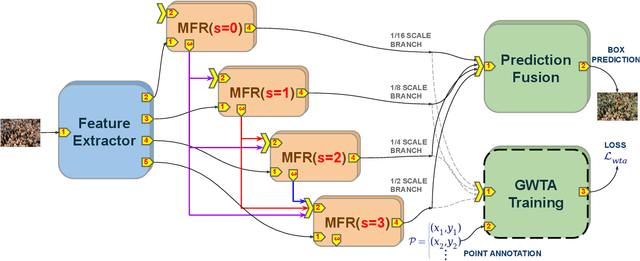
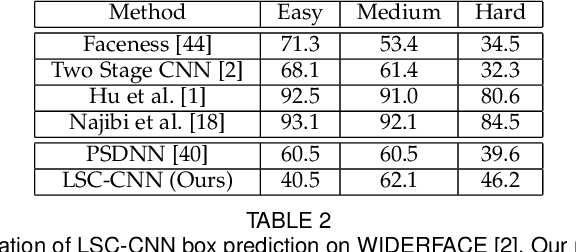
We introduce a detection framework for dense crowd counting and eliminate the need for the prevalent density regression paradigm. Typical counting models predict crowd density for an image as opposed to detecting every person. These regression methods, in general, fail to localize persons accurate enough for most applications other than counting. Hence, we adopt an architecture that locates every person in the crowd, sizes the spotted heads with bounding box and then counts them. Compared to normal object or face detectors, there exist certain unique challenges in designing such a detection system. Some of them are direct consequences of the huge diversity in dense crowds along with the need to predict boxes contiguously. We solve these issues and develop our LSC-CNN model, which can reliably detect heads of people across sparse to dense crowds. LSC-CNN employs a multi-column architecture with top-down feedback processing to better resolve persons and produce refined predictions at multiple resolutions. Interestingly, the proposed training regime requires only point head annotation, but can estimate approximate size information of heads. We show that LSC-CNN not only has superior localization than existing density regressors, but outperforms in counting as well. The code for our approach is available at https://github.com/val-iisc/lsc-cnn.
Deep Cross Modal Learning for Caricature Verification and Identification(CaVINet)
Jul 31, 2018
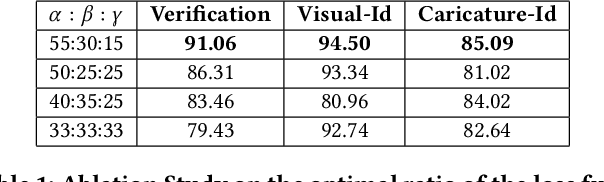
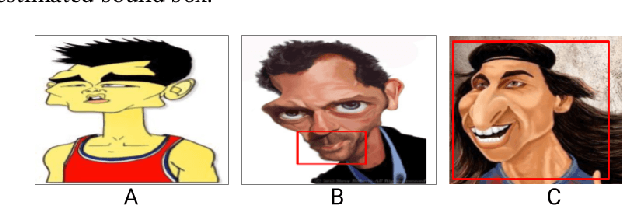
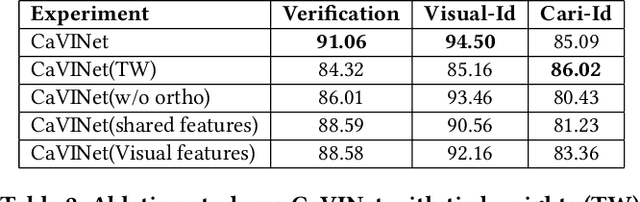
Learning from different modalities is a challenging task. In this paper, we look at the challenging problem of cross modal face verification and recognition between caricature and visual image modalities. Caricature have exaggerations of facial features of a person. Due to the significant variations in the caricatures, building vision models for recognizing and verifying data from this modality is an extremely challenging task. Visual images with significantly lesser amount of distortions can act as a bridge for the analysis of caricature modality. We introduce a publicly available large Caricature-VIsual dataset [CaVI] with images from both the modalities that captures the rich variations in the caricature of an identity. This paper presents the first cross modal architecture that handles extreme distortions of caricatures using a deep learning network that learns similar representations across the modalities. We use two convolutional networks along with transformations that are subjected to orthogonality constraints to capture the shared and modality specific representations. In contrast to prior research, our approach neither depends on manually extracted facial landmarks for learning the representations, nor on the identities of the person for performing verification. The learned shared representation achieves 91% accuracy for verifying unseen images and 75% accuracy on unseen identities. Further, recognizing the identity in the image by knowledge transfer using a combination of shared and modality specific representations, resulted in an unprecedented performance of 85% rank-1 accuracy for caricatures and 95% rank-1 accuracy for visual images.
MRI to FDG-PET: Cross-Modal Synthesis Using 3D U-Net For Multi-Modal Alzheimer's Classification
Jul 30, 2018
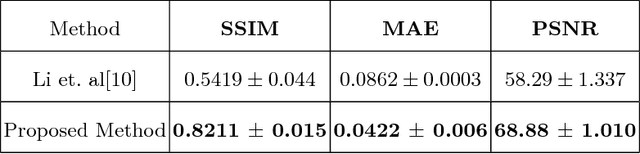


Recent studies suggest that combined analysis of Magnetic resonance imaging~(MRI) that measures brain atrophy and positron emission tomography~(PET) that quantifies hypo-metabolism provides improved accuracy in diagnosing Alzheimer's disease. However, such techniques are limited by the availability of corresponding scans of each modality. Current work focuses on a cross-modal approach to estimate FDG-PET scans for the given MR scans using a 3D U-Net architecture. The use of the complete MR image instead of a local patch based approach helps in capturing non-local and non-linear correlations between MRI and PET modalities. The quality of the estimated PET scans is measured using quantitative metrics such as MAE, PSNR and SSIM. The efficacy of the proposed method is evaluated in the context of Alzheimer's disease classification. The accuracy using only MRI is 70.18% while joint classification using synthesized PET and MRI is 74.43% with a p-value of $0.06$. The significant improvement in diagnosis demonstrates the utility of the synthesized PET scans for multi-modal analysis.
DisguiseNet : A Contrastive Approach for Disguised Face Verification in the Wild
Apr 26, 2018
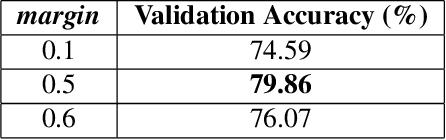
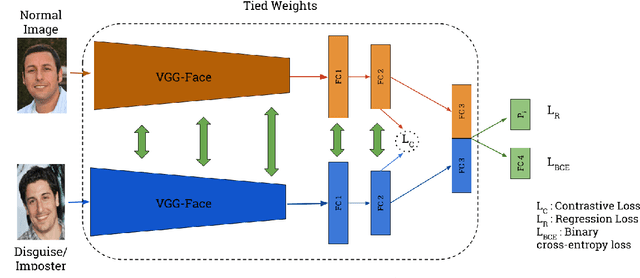

This paper describes our approach for the Disguised Faces in the Wild (DFW) 2018 challenge. The task here is to verify the identity of a person among disguised and impostors images. Given the importance of the task of face verification it is essential to compare methods across a common platform. Our approach is based on VGG-face architecture paired with Contrastive loss based on cosine distance metric. For augmenting the data set, we source more data from the internet. The experiments show the effectiveness of the approach on the DFW data. We show that adding extra data to the DFW dataset with noisy labels also helps in increasing the generalization performance of the network. The proposed network achieves 27.13% absolute increase in accuracy over the DFW baseline.