 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAI-BPR: Personalized Outfit Recommendation Scheme with Attribute-wise Interpretability
Aug 04, 2020

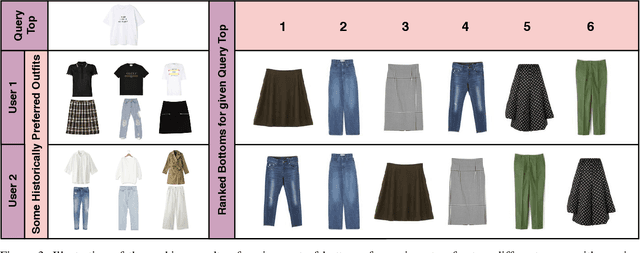
Fashion is an important part of human experience. Events such as interviews, meetings, marriages, etc. are often based on clothing styles. The rise in the fashion industry and its effect on social influencing have made outfit compatibility a need. Thus, it necessitates an outfit compatibility model to aid people in clothing recommendation. However, due to the highly subjective nature of compatibility, it is necessary to account for personalization. Our paper devises an attribute-wise interpretable compatibility scheme with personal preference modelling which captures user-item interaction along with general item-item interaction. Our work solves the problem of interpretability in clothing matching by locating the discordant and harmonious attributes between fashion items. Extensive experiment results on IQON3000, a publicly available real-world dataset, verify the effectiveness of the proposed model.
Deep Cross Modal Learning for Caricature Verification and Identification(CaVINet)
Jul 31, 2018
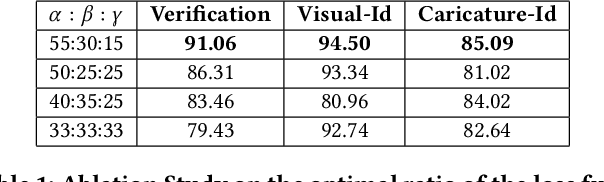
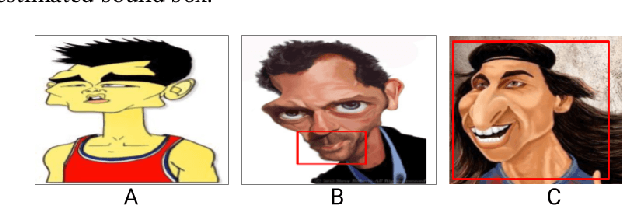
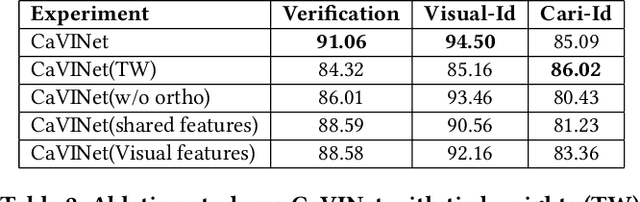
Learning from different modalities is a challenging task. In this paper, we look at the challenging problem of cross modal face verification and recognition between caricature and visual image modalities. Caricature have exaggerations of facial features of a person. Due to the significant variations in the caricatures, building vision models for recognizing and verifying data from this modality is an extremely challenging task. Visual images with significantly lesser amount of distortions can act as a bridge for the analysis of caricature modality. We introduce a publicly available large Caricature-VIsual dataset [CaVI] with images from both the modalities that captures the rich variations in the caricature of an identity. This paper presents the first cross modal architecture that handles extreme distortions of caricatures using a deep learning network that learns similar representations across the modalities. We use two convolutional networks along with transformations that are subjected to orthogonality constraints to capture the shared and modality specific representations. In contrast to prior research, our approach neither depends on manually extracted facial landmarks for learning the representations, nor on the identities of the person for performing verification. The learned shared representation achieves 91% accuracy for verifying unseen images and 75% accuracy on unseen identities. Further, recognizing the identity in the image by knowledge transfer using a combination of shared and modality specific representations, resulted in an unprecedented performance of 85% rank-1 accuracy for caricatures and 95% rank-1 accuracy for visual images.