 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAR: Plausibility-aware Amortized Recourse Generation
Jan 24, 2026Algorithmic recourse aims to recommend actionable changes to a factual's attributes that flip an unfavorable model decision while remaining realistic and feasible. We formulate recourse as a Constrained Maximum A-Posteriori (MAP) inference problem under the accepted-class data distribution seeking counterfactuals with high likelihood while respecting other recourse constraints. We present PAR, an amortized approximate inference procedure that generates highly likely recourses efficiently. Recourse likelihood is estimated directly using tractable probabilistic models that admit exact likelihood evaluation and efficient gradient propagation that is useful during training. The recourse generator is trained with the objective of maximizing the likelihood under the accepted-class distribution while minimizing the likelihood under the denied-class distribution and other losses that encode recourse constraints. Furthermore, PAR includes a neighborhood-based conditioning mechanism to promote recourse generation that is customized to a factual. We validate PAR on widely used algorithmic recourse datasets and demonstrate its efficiency in generating recourses that are valid, similar to the factual, sparse, and highly plausible, yielding superior performance over existing state-of-the-art approaches.
Explainable Supervised Domain Adaptation
May 24, 2022



Domain adaptation techniques have contributed to the success of deep learning. Leveraging knowledge from an auxiliary source domain for learning in labeled data-scarce target domain is fundamental to domain adaptation. While these techniques result in increasing accuracy, the adaptation process, particularly the knowledge leveraged from the source domain, remains unclear. This paper proposes an explainable by design supervised domain adaptation framework - XSDA-Net. We integrate a case-based reasoning mechanism into the XSDA-Net to explain the prediction of a test instance in terms of similar-looking regions in the source and target train images. We empirically demonstrate the utility of the proposed framework by curating the domain adaptation settings on datasets popularly known to exhibit part-based explainability.
PACE: Posthoc Architecture-Agnostic Concept Extractor for Explaining CNNs
Aug 31, 2021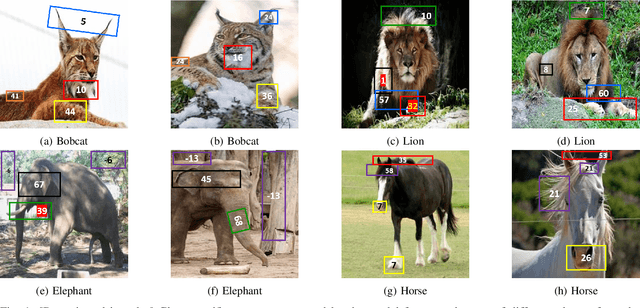
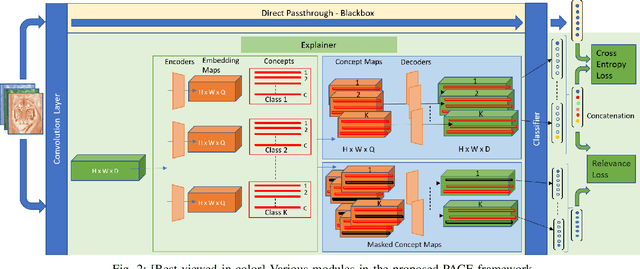


Deep CNNs, though have achieved the state of the art performance in image classification tasks, remain a black-box to a human using them. There is a growing interest in explaining the working of these deep models to improve their trustworthiness. In this paper, we introduce a Posthoc Architecture-agnostic Concept Extractor (PACE) that automatically extracts smaller sub-regions of the image called concepts relevant to the black-box prediction. PACE tightly integrates the faithfulness of the explanatory framework to the black-box model. To the best of our knowledge, this is the first work that extracts class-specific discriminative concepts in a posthoc manner automatically. The PACE framework is used to generate explanations for two different CNN architectures trained for classifying the AWA2 and Imagenet-Birds datasets. Extensive human subject experiments are conducted to validate the human interpretability and consistency of the explanations extracted by PACE. The results from these experiments suggest that over 72% of the concepts extracted by PACE are human interpretable.
Evaluation of Saliency-based Explainability Method
Jun 24, 2021

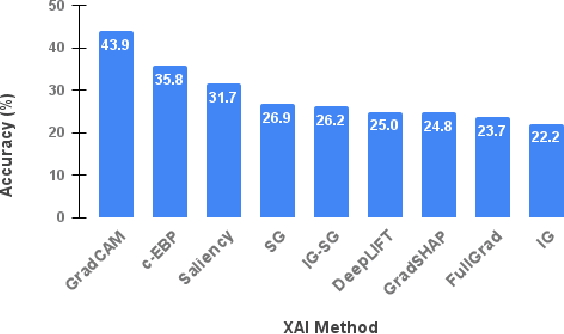

A particular class of Explainable AI (XAI) methods provide saliency maps to highlight part of the image a Convolutional Neural Network (CNN) model looks at to classify the image as a way to explain its working. These methods provide an intuitive way for users to understand predictions made by CNNs. Other than quantitative computational tests, the vast majority of evidence to highlight that the methods are valuable is anecdotal. Given that humans would be the end-users of such methods, we devise three human subject experiments through which we gauge the effectiveness of these saliency-based explainability methods.
MAIRE -- A Model-Agnostic Interpretable Rule Extraction Procedure for Explaining Classifiers
Nov 03, 2020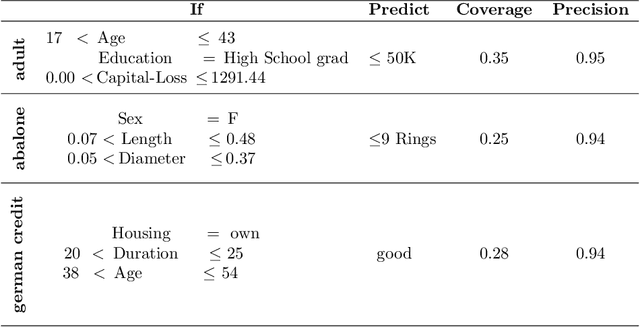
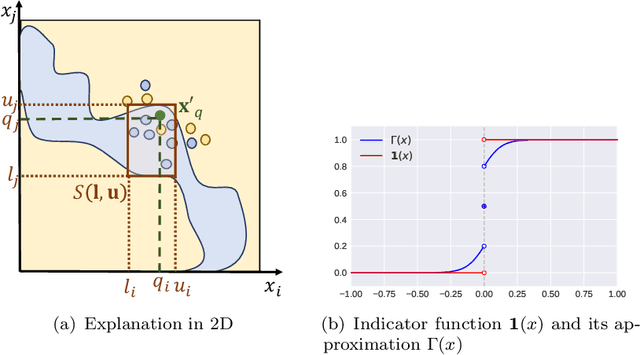

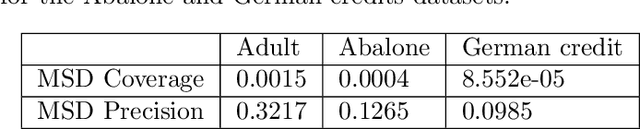
The paper introduces a novel framework for extracting model-agnostic human interpretable rules to explain a classifier's output. The human interpretable rule is defined as an axis-aligned hyper-cuboid containing the instance for which the classification decision has to be explained. The proposed procedure finds the largest (high \textit{coverage}) axis-aligned hyper-cuboid such that a high percentage of the instances in the hyper-cuboid have the same class label as the instance being explained (high \textit{precision}). Novel approximations to the coverage and precision measures in terms of the parameters of the hyper-cuboid are defined. They are maximized using gradient-based optimizers. The quality of the approximations is rigorously analyzed theoretically and experimentally. Heuristics for simplifying the generated explanations for achieving better interpretability and a greedy selection algorithm that combines the local explanations for creating global explanations for the model covering a large part of the instance space are also proposed. The framework is model agnostic, can be applied to any arbitrary classifier, and all types of attributes (including continuous, ordered, and unordered discrete). The wide-scale applicability of the framework is validated on a variety of synthetic and real-world datasets from different domains (tabular, text, and image).
MACE: Model Agnostic Concept Extractor for Explaining Image Classification Networks
Nov 03, 2020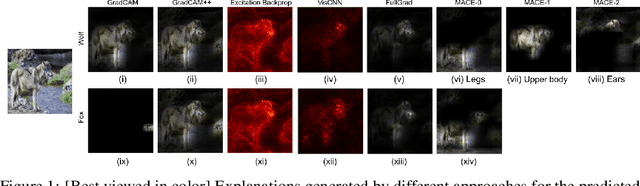


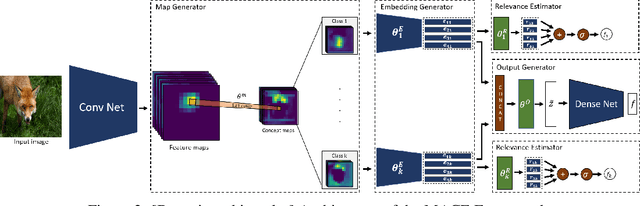
Deep convolutional networks have been quite successful at various image classification tasks. The current methods to explain the predictions of a pre-trained model rely on gradient information, often resulting in saliency maps that focus on the foreground object as a whole. However, humans typically reason by dissecting an image and pointing out the presence of smaller concepts. The final output is often an aggregation of the presence or absence of these smaller concepts. In this work, we propose MACE: a Model Agnostic Concept Extractor, which can explain the working of a convolutional network through smaller concepts. The MACE framework dissects the feature maps generated by a convolution network for an image to extract concept based prototypical explanations. Further, it estimates the relevance of the extracted concepts to the pre-trained model's predictions, a critical aspect required for explaining the individual class predictions, missing in existing approaches. We validate our framework using VGG16 and ResNet50 CNN architectures, and on datasets like Animals With Attributes 2 (AWA2) and Places365. Our experiments demonstrate that the concepts extracted by the MACE framework increase the human interpretability of the explanations, and are faithful to the underlying pre-trained black-box model.
Deep Cross Modal Learning for Caricature Verification and Identification(CaVINet)
Jul 31, 2018
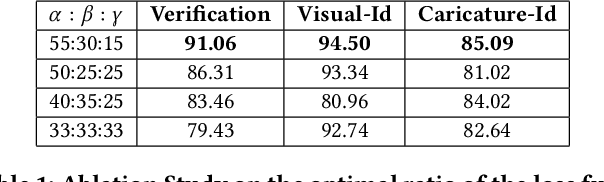
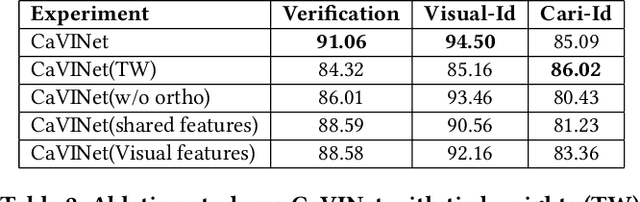
Learning from different modalities is a challenging task. In this paper, we look at the challenging problem of cross modal face verification and recognition between caricature and visual image modalities. Caricature have exaggerations of facial features of a person. Due to the significant variations in the caricatures, building vision models for recognizing and verifying data from this modality is an extremely challenging task. Visual images with significantly lesser amount of distortions can act as a bridge for the analysis of caricature modality. We introduce a publicly available large Caricature-VIsual dataset [CaVI] with images from both the modalities that captures the rich variations in the caricature of an identity. This paper presents the first cross modal architecture that handles extreme distortions of caricatures using a deep learning network that learns similar representations across the modalities. We use two convolutional networks along with transformations that are subjected to orthogonality constraints to capture the shared and modality specific representations. In contrast to prior research, our approach neither depends on manually extracted facial landmarks for learning the representations, nor on the identities of the person for performing verification. The learned shared representation achieves 91% accuracy for verifying unseen images and 75% accuracy on unseen identities. Further, recognizing the identity in the image by knowledge transfer using a combination of shared and modality specific representations, resulted in an unprecedented performance of 85% rank-1 accuracy for caricatures and 95% rank-1 accuracy for visual images.