Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Saliency-based Explainability Method
Paper and Code
Jun 24, 2021

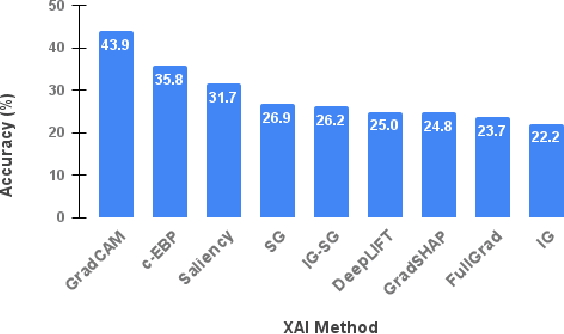

A particular class of Explainable AI (XAI) methods provide saliency maps to highlight part of the image a Convolutional Neural Network (CNN) model looks at to classify the image as a way to explain its working. These methods provide an intuitive way for users to understand predictions made by CNNs. Other than quantitative computational tests, the vast majority of evidence to highlight that the methods are valuable is anecdotal. Given that humans would be the end-users of such methods, we devise three human subject experiments through which we gauge the effectiveness of these saliency-based explainability methods.
* Accepted at the ICML Workshop on Theoretic Foundation, Criticism, and
Application Trend of Explainable AI, 2021
View paper on