 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-RADS Synthetic Radiology Report Dataset and Head-to-Head Benchmarking of 41 Open-Weight and Proprietary Language Models
Jan 06, 2026Background: Reporting and Data Systems (RADS) standardize radiology risk communication but automated RADS assignment from narrative reports is challenging because of guideline complexity, output-format constraints, and limited benchmarking across RADS frameworks and model sizes. Purpose: To create RXL-RADSet, a radiologist-verified synthetic multi-RADS benchmark, and compare validity and accuracy of open-weight small language models (SLMs) with a proprietary model for RADS assignment. Materials and Methods: RXL-RADSet contains 1,600 synthetic radiology reports across 10 RADS (BI-RADS, CAD-RADS, GB-RADS, LI-RADS, Lung-RADS, NI-RADS, O-RADS, PI-RADS, TI-RADS, VI-RADS) and multiple modalities. Reports were generated by LLMs using scenario plans and simulated radiologist styles and underwent two-stage radiologist verification. We evaluated 41 quantized SLMs (12 families, 0.135-32B parameters) and GPT-5.2 under a fixed guided prompt. Primary endpoints were validity and accuracy; a secondary analysis compared guided versus zero-shot prompting. Results: Under guided prompting GPT-5.2 achieved 99.8% validity and 81.1% accuracy (1,600 predictions). Pooled SLMs (65,600 predictions) achieved 96.8% validity and 61.1% accuracy; top SLMs in the 20-32B range reached ~99% validity and mid-to-high 70% accuracy. Performance scaled with model size (inflection between <1B and >=10B) and declined with RADS complexity primarily due to classification difficulty rather than invalid outputs. Guided prompting improved validity (99.2% vs 96.7%) and accuracy (78.5% vs 69.6%) compared with zero-shot. Conclusion: RXL-RADSet provides a radiologist-verified multi-RADS benchmark; large SLMs (20-32B) can approach proprietary-model performance under guided prompting, but gaps remain for higher-complexity schemes.
MACE: Model Agnostic Concept Extractor for Explaining Image Classification Networks
Nov 03, 2020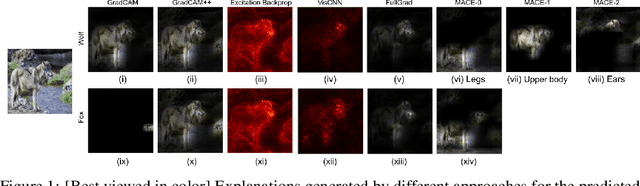


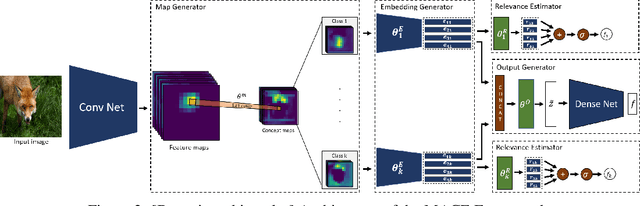
Deep convolutional networks have been quite successful at various image classification tasks. The current methods to explain the predictions of a pre-trained model rely on gradient information, often resulting in saliency maps that focus on the foreground object as a whole. However, humans typically reason by dissecting an image and pointing out the presence of smaller concepts. The final output is often an aggregation of the presence or absence of these smaller concepts. In this work, we propose MACE: a Model Agnostic Concept Extractor, which can explain the working of a convolutional network through smaller concepts. The MACE framework dissects the feature maps generated by a convolution network for an image to extract concept based prototypical explanations. Further, it estimates the relevance of the extracted concepts to the pre-trained model's predictions, a critical aspect required for explaining the individual class predictions, missing in existing approaches. We validate our framework using VGG16 and ResNet50 CNN architectures, and on datasets like Animals With Attributes 2 (AWA2) and Places365. Our experiments demonstrate that the concepts extracted by the MACE framework increase the human interpretability of the explanations, and are faithful to the underlying pre-trained black-box model.