 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIRE -- A Model-Agnostic Interpretable Rule Extraction Procedure for Explaining Classifiers
Paper and Code
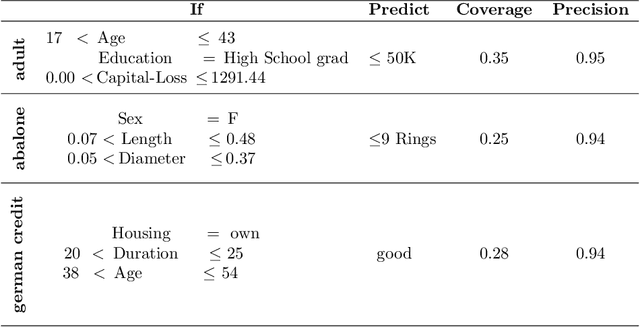
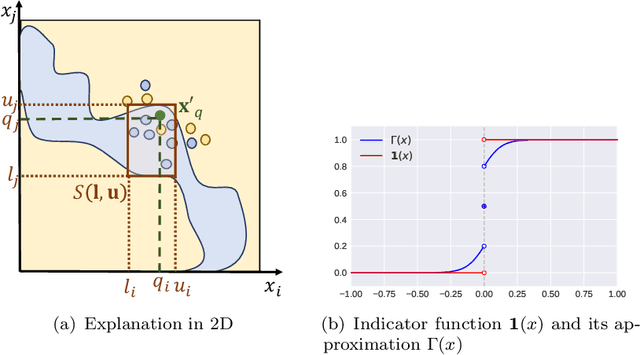

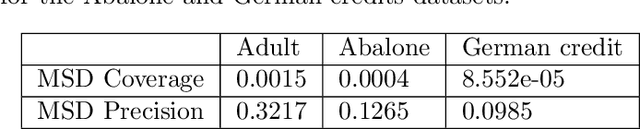
The paper introduces a novel framework for extracting model-agnostic human interpretable rules to explain a classifier's output. The human interpretable rule is defined as an axis-aligned hyper-cuboid containing the instance for which the classification decision has to be explained. The proposed procedure finds the largest (high \textit{coverage}) axis-aligned hyper-cuboid such that a high percentage of the instances in the hyper-cuboid have the same class label as the instance being explained (high \textit{precision}). Novel approximations to the coverage and precision measures in terms of the parameters of the hyper-cuboid are defined. They are maximized using gradient-based optimizers. The quality of the approximations is rigorously analyzed theoretically and experimentally. Heuristics for simplifying the generated explanations for achieving better interpretability and a greedy selection algorithm that combines the local explanations for creating global explanations for the model covering a large part of the instance space are also proposed. The framework is model agnostic, can be applied to any arbitrary classifier, and all types of attributes (including continuous, ordered, and unordered discrete). The wide-scale applicability of the framework is validated on a variety of synthetic and real-world datasets from different domains (tabular, text, and image).