 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRI to PET Cross-Modality Translation using Globally and Locally Aware GAN for Multi-Modal Diagnosis of Alzheimer's Disease
Aug 04, 2021



Medical imaging datasets are inherently high dimensional with large variability and low sample sizes that limit the effectiveness of deep learning algorithms. Recently, generative adversarial networks (GANs) with the ability to synthesize realist images have shown great potential as an alternative to standard data augmentation techniques. Our work focuses on cross-modality synthesis of fluorodeoxyglucose~(FDG) Positron Emission Tomography~(PET) scans from structural Magnetic Resonance~(MR) images using generative models to facilitate multi-modal diagnosis of Alzheimer's disease (AD). Specifically, we propose a novel end-to-end, globally and locally aware image-to-image translation GAN (GLA-GAN) with a multi-path architecture that enforces both global structural integrity and fidelity to local details. We further supplement the standard adversarial loss with voxel-level intensity, multi-scale structural similarity (MS-SSIM) and region-of-interest (ROI) based loss components that reduce reconstruction error, enforce structural consistency at different scales and perceive variation in regional sensitivity to AD respectively. Experimental results demonstrate that our GLA-GAN not only generates synthesized FDG-PET scans with enhanced image quality but also superior clinical utility in improving AD diagnosis compared to state-of-the-art models. Finally, we attempt to interpret some of the internal units of the GAN that are closely related to this specific cross-modality generation task.
REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
Oct 08, 2019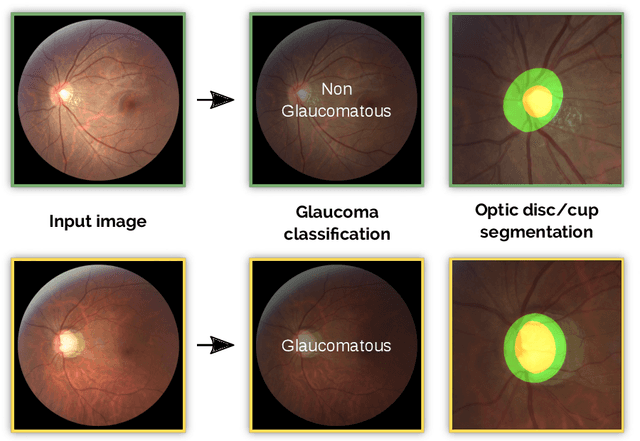
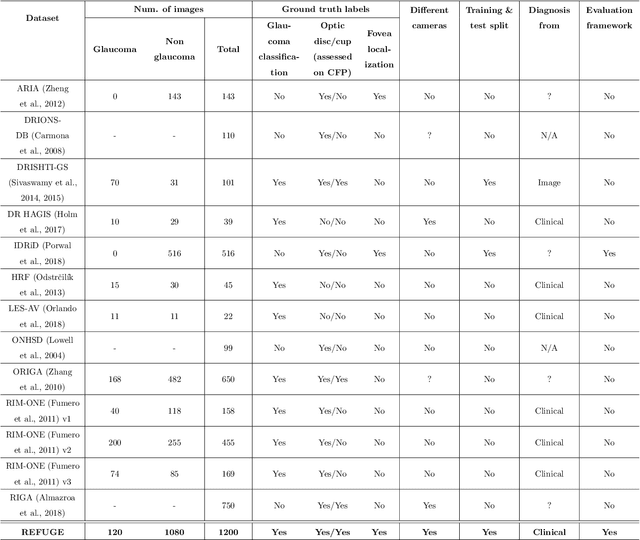

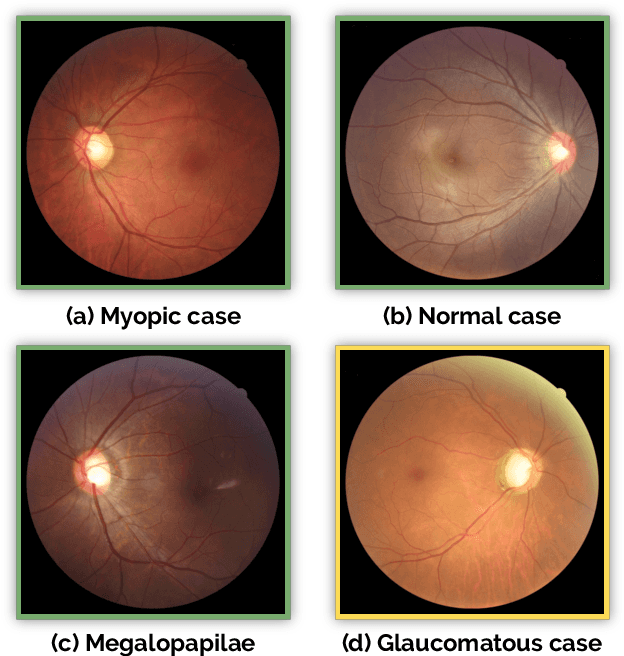
Glaucoma is one of the leading causes of irreversible but preventable blindness in working age populations. Color fundus photography (CFP) is the most cost-effective imaging modality to screen for retinal disorders. However, its application to glaucoma has been limited to the computation of a few related biomarkers such as the vertical cup-to-disc ratio. Deep learning approaches, although widely applied for medical image analysis, have not been extensively used for glaucoma assessment due to the limited size of the available data sets. Furthermore, the lack of a standardize benchmark strategy makes difficult to compare existing methods in a uniform way. In order to overcome these issues we set up the Retinal Fundus Glaucoma Challenge, REFUGE (\url{https://refuge.grand-challenge.org}), held in conjunction with MICCAI 2018. The challenge consisted of two primary tasks, namely optic disc/cup segmentation and glaucoma classification. As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one. We have also built an evaluation framework to ease and ensure fairness in the comparison of different models, encouraging the development of novel techniques in the field. 12 teams qualified and participated in the online challenge. This paper summarizes their methods and analyzes their corresponding results. In particular, we observed that two of the top-ranked teams outperformed two human experts in the glaucoma classification task. Furthermore, the segmentation results were in general consistent with the ground truth annotations, with complementary outcomes that can be further exploited by ensembling the results.
MRI to FDG-PET: Cross-Modal Synthesis Using 3D U-Net For Multi-Modal Alzheimer's Classification
Jul 30, 2018
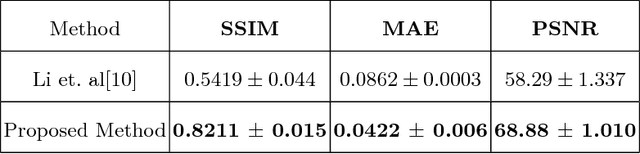


Recent studies suggest that combined analysis of Magnetic resonance imaging~(MRI) that measures brain atrophy and positron emission tomography~(PET) that quantifies hypo-metabolism provides improved accuracy in diagnosing Alzheimer's disease. However, such techniques are limited by the availability of corresponding scans of each modality. Current work focuses on a cross-modal approach to estimate FDG-PET scans for the given MR scans using a 3D U-Net architecture. The use of the complete MR image instead of a local patch based approach helps in capturing non-local and non-linear correlations between MRI and PET modalities. The quality of the estimated PET scans is measured using quantitative metrics such as MAE, PSNR and SSIM. The efficacy of the proposed method is evaluated in the context of Alzheimer's disease classification. The accuracy using only MRI is 70.18% while joint classification using synthesized PET and MRI is 74.43% with a p-value of $0.06$. The significant improvement in diagnosis demonstrates the utility of the synthesized PET scans for multi-modal analysis.
Dense and Diverse Capsule Networks: Making the Capsules Learn Better
May 10, 2018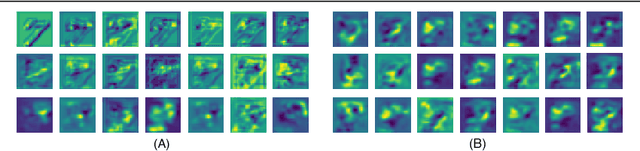
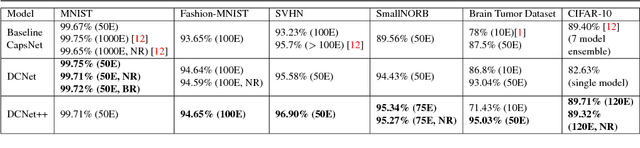
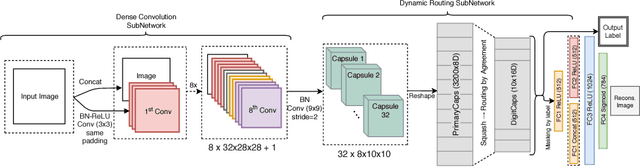

Past few years have witnessed exponential growth of interest in deep learning methodologies with rapidly improving accuracies and reduced computational complexity. In particular, architectures using Convolutional Neural Networks (CNNs) have produced state-of-the-art performances for image classification and object recognition tasks. Recently, Capsule Networks (CapsNet) achieved significant increase in performance by addressing an inherent limitation of CNNs in encoding pose and deformation. Inspired by such advancement, we asked ourselves, can we do better? We propose Dense Capsule Networks (DCNet) and Diverse Capsule Networks (DCNet++). The two proposed frameworks customize the CapsNet by replacing the standard convolutional layers with densely connected convolutions. This helps in incorporating feature maps learned by different layers in forming the primary capsules. DCNet, essentially adds a deeper convolution network, which leads to learning of discriminative feature maps. Additionally, DCNet++ uses a hierarchical architecture to learn capsules that represent spatial information in a fine-to-coarser manner, which makes it more efficient for learning complex data. Experiments on image classification task using benchmark datasets demonstrate the efficacy of the proposed architectures. DCNet achieves state-of-the-art performance (99.75%) on MNIST dataset with twenty fold decrease in total training iterations, over the conventional CapsNet. Furthermore, DCNet++ performs better than CapsNet on SVHN dataset (96.90%), and outperforms the ensemble of seven CapsNet models on CIFAR-10 by 0.31% with seven fold decrease in number of parameters.