 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense and Diverse Capsule Networks: Making the Capsules Learn Better
Paper and Code
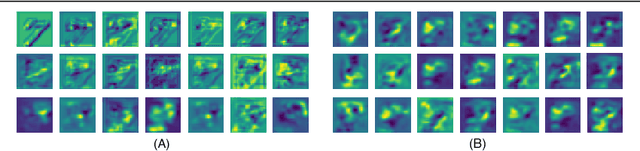
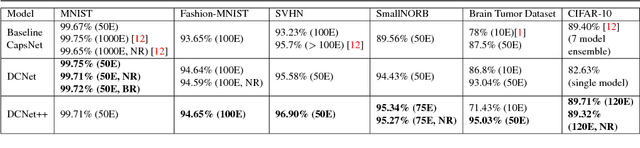
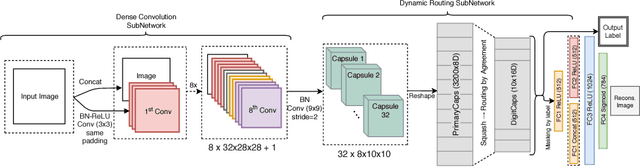

Past few years have witnessed exponential growth of interest in deep learning methodologies with rapidly improving accuracies and reduced computational complexity. In particular, architectures using Convolutional Neural Networks (CNNs) have produced state-of-the-art performances for image classification and object recognition tasks. Recently, Capsule Networks (CapsNet) achieved significant increase in performance by addressing an inherent limitation of CNNs in encoding pose and deformation. Inspired by such advancement, we asked ourselves, can we do better? We propose Dense Capsule Networks (DCNet) and Diverse Capsule Networks (DCNet++). The two proposed frameworks customize the CapsNet by replacing the standard convolutional layers with densely connected convolutions. This helps in incorporating feature maps learned by different layers in forming the primary capsules. DCNet, essentially adds a deeper convolution network, which leads to learning of discriminative feature maps. Additionally, DCNet++ uses a hierarchical architecture to learn capsules that represent spatial information in a fine-to-coarser manner, which makes it more efficient for learning complex data. Experiments on image classification task using benchmark datasets demonstrate the efficacy of the proposed architectures. DCNet achieves state-of-the-art performance (99.75%) on MNIST dataset with twenty fold decrease in total training iterations, over the conventional CapsNet. Furthermore, DCNet++ performs better than CapsNet on SVHN dataset (96.90%), and outperforms the ensemble of seven CapsNet models on CIFAR-10 by 0.31% with seven fold decrease in number of parameters.