 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Domain Question Answering with Pre-Constructed Question Spaces
Paper and Code
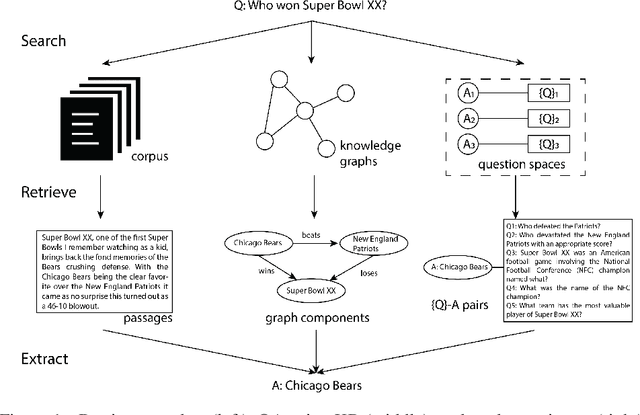

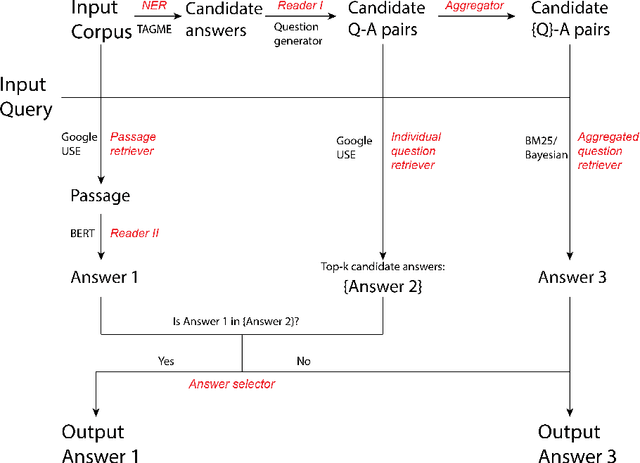
Open-domain question answering aims at solving the task of locating the answers to user-generated questions in large collections of documents. There are two families of solutions to this challenge. One family of algorithms, namely retriever-readers, first retrieves some pieces of text that are probably relevant to the question, and then feeds the retrieved text to a neural network to get the answer. Another line of work first constructs some knowledge graphs from the corpus, and queries the graph for the answer. We propose a novel algorithm with a reader-retriever structure that differs from both families. Our algorithm first reads off-line the corpus to generate collections of all answerable questions associated with their answers, and then queries the pre-constructed question spaces online to find answers that are most likely to be asked in the given way. The final answer returned to the user is decided with an accept-or-reject mechanism that combines multiple candidate answers by comparing the level of agreement between the retriever-reader and reader-retriever results. We claim that our algorithm solves some bottlenecks in existing work, and demonstrate that it achieves superior accuracy on a public dataset.