 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA MISMATCHED Benchmark for Scientific Natural Language Inference
Jun 05, 2025Scientific Natural Language Inference (NLI) is the task of predicting the semantic relation between a pair of sentences extracted from research articles. Existing datasets for this task are derived from various computer science (CS) domains, whereas non-CS domains are completely ignored. In this paper, we introduce a novel evaluation benchmark for scientific NLI, called MISMATCHED. The new MISMATCHED benchmark covers three non-CS domains-PSYCHOLOGY, ENGINEERING, and PUBLIC HEALTH, and contains 2,700 human annotated sentence pairs. We establish strong baselines on MISMATCHED using both Pre-trained Small Language Models (SLMs) and Large Language Models (LLMs). Our best performing baseline shows a Macro F1 of only 78.17% illustrating the substantial headroom for future improvements. In addition to introducing the MISMATCHED benchmark, we show that incorporating sentence pairs having an implicit scientific NLI relation between them in model training improves their performance on scientific NLI. We make our dataset and code publicly available on GitHub.
Co-training for Low Resource Scientific Natural Language Inference
Jun 20, 2024



Scientific Natural Language Inference (NLI) is the task of predicting the semantic relation between a pair of sentences extracted from research articles. The automatic annotation method based on distant supervision for the training set of SciNLI (Sadat and Caragea, 2022b), the first and most popular dataset for this task, results in label noise which inevitably degenerates the performance of classifiers. In this paper, we propose a novel co-training method that assigns weights based on the training dynamics of the classifiers to the distantly supervised labels, reflective of the manner they are used in the subsequent training epochs. That is, unlike the existing semi-supervised learning (SSL) approaches, we consider the historical behavior of the classifiers to evaluate the quality of the automatically annotated labels. Furthermore, by assigning importance weights instead of filtering out examples based on an arbitrary threshold on the predicted confidence, we maximize the usage of automatically labeled data, while ensuring that the noisy labels have a minimal impact on model training. The proposed method obtains an improvement of 1.5% in Macro F1 over the distant supervision baseline, and substantial improvements over several other strong SSL baselines. We make our code and data available on Github.
MSciNLI: A Diverse Benchmark for Scientific Natural Language Inference
Apr 11, 2024The task of scientific Natural Language Inference (NLI) involves predicting the semantic relation between two sentences extracted from research articles. This task was recently proposed along with a new dataset called SciNLI derived from papers published in the computational linguistics domain. In this paper, we aim to introduce diversity in the scientific NLI task and present MSciNLI, a dataset containing 132,320 sentence pairs extracted from five new scientific domains. The availability of multiple domains makes it possible to study domain shift for scientific NLI. We establish strong baselines on MSciNLI by fine-tuning Pre-trained Language Models (PLMs) and prompting Large Language Models (LLMs). The highest Macro F1 scores of PLM and LLM baselines are 77.21% and 51.77%, respectively, illustrating that MSciNLI is challenging for both types of models. Furthermore, we show that domain shift degrades the performance of scientific NLI models which demonstrates the diverse characteristics of different domains in our dataset. Finally, we use both scientific NLI datasets in an intermediate task transfer learning setting and show that they can improve the performance of downstream tasks in the scientific domain. We make our dataset and code available on Github.
DelucionQA: Detecting Hallucinations in Domain-specific Question Answering
Dec 08, 2023



Hallucination is a well-known phenomenon in text generated by large language models (LLMs). The existence of hallucinatory responses is found in almost all application scenarios e.g., summarization, question-answering (QA) etc. For applications requiring high reliability (e.g., customer-facing assistants), the potential existence of hallucination in LLM-generated text is a critical problem. The amount of hallucination can be reduced by leveraging information retrieval to provide relevant background information to the LLM. However, LLMs can still generate hallucinatory content for various reasons (e.g., prioritizing its parametric knowledge over the context, failure to capture the relevant information from the context, etc.). Detecting hallucinations through automated methods is thus paramount. To facilitate research in this direction, we introduce a sophisticated dataset, DelucionQA, that captures hallucinations made by retrieval-augmented LLMs for a domain-specific QA task. Furthermore, we propose a set of hallucination detection methods to serve as baselines for future works from the research community. Analysis and case study are also provided to share valuable insights on hallucination phenomena in the target scenario.
Learning to Infer from Unlabeled Data: A Semi-supervised Learning Approach for Robust Natural Language Inference
Nov 05, 2022Natural Language Inference (NLI) or Recognizing Textual Entailment (RTE) aims at predicting the relation between a pair of sentences (premise and hypothesis) as entailment, contradiction or semantic independence. Although deep learning models have shown promising performance for NLI in recent years, they rely on large scale expensive human-annotated datasets. Semi-supervised learning (SSL) is a popular technique for reducing the reliance on human annotation by leveraging unlabeled data for training. However, despite its substantial success on single sentence classification tasks where the challenge in making use of unlabeled data is to assign "good enough" pseudo-labels, for NLI tasks, the nature of unlabeled data is more complex: one of the sentences in the pair (usually the hypothesis) along with the class label are missing from the data and require human annotations, which makes SSL for NLI more challenging. In this paper, we propose a novel way to incorporate unlabeled data in SSL for NLI where we use a conditional language model, BART to generate the hypotheses for the unlabeled sentences (used as premises). Our experiments show that our SSL framework successfully exploits unlabeled data and substantially improves the performance of four NLI datasets in low-resource settings. We release our code at: https://github.com/msadat3/SSL_for_NLI.
Hierarchical Multi-Label Classification of Scientific Documents
Nov 05, 2022Automatic topic classification has been studied extensively to assist managing and indexing scientific documents in a digital collection. With the large number of topics being available in recent years, it has become necessary to arrange them in a hierarchy. Therefore, the automatic classification systems need to be able to classify the documents hierarchically. In addition, each paper is often assigned to more than one relevant topic. For example, a paper can be assigned to several topics in a hierarchy tree. In this paper, we introduce a new dataset for hierarchical multi-label text classification (HMLTC) of scientific papers called SciHTC, which contains 186,160 papers and 1,233 categories from the ACM CCS tree. We establish strong baselines for HMLTC and propose a multi-task learning approach for topic classification with keyword labeling as an auxiliary task. Our best model achieves a Macro-F1 score of 34.57% which shows that this dataset provides significant research opportunities on hierarchical scientific topic classification. We make our dataset and code available on Github.
SciNLI: A Corpus for Natural Language Inference on Scientific Text
Mar 15, 2022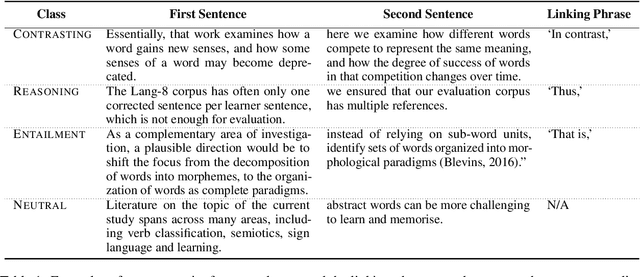
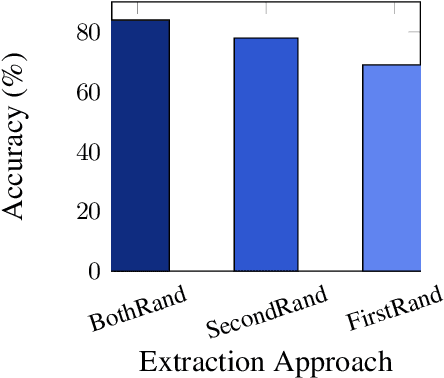


Existing Natural Language Inference (NLI) datasets, while being instrumental in the advancement of Natural Language Understanding (NLU) research, are not related to scientific text. In this paper, we introduce SciNLI, a large dataset for NLI that captures the formality in scientific text and contains 107,412 sentence pairs extracted from scholarly papers on NLP and computational linguistics. Given that the text used in scientific literature differs vastly from the text used in everyday language both in terms of vocabulary and sentence structure, our dataset is well suited to serve as a benchmark for the evaluation of scientific NLU models. Our experiments show that SciNLI is harder to classify than the existing NLI datasets. Our best performing model with XLNet achieves a Macro F1 score of only 78.18% and an accuracy of 78.23% showing that there is substantial room for improvement.