 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelucionQA: Detecting Hallucinations in Domain-specific Question Answering
Dec 08, 2023



Hallucination is a well-known phenomenon in text generated by large language models (LLMs). The existence of hallucinatory responses is found in almost all application scenarios e.g., summarization, question-answering (QA) etc. For applications requiring high reliability (e.g., customer-facing assistants), the potential existence of hallucination in LLM-generated text is a critical problem. The amount of hallucination can be reduced by leveraging information retrieval to provide relevant background information to the LLM. However, LLMs can still generate hallucinatory content for various reasons (e.g., prioritizing its parametric knowledge over the context, failure to capture the relevant information from the context, etc.). Detecting hallucinations through automated methods is thus paramount. To facilitate research in this direction, we introduce a sophisticated dataset, DelucionQA, that captures hallucinations made by retrieval-augmented LLMs for a domain-specific QA task. Furthermore, we propose a set of hallucination detection methods to serve as baselines for future works from the research community. Analysis and case study are also provided to share valuable insights on hallucination phenomena in the target scenario.
LaSQuE: Improved Zero-Shot Classification from Explanations Through Quantifier Modeling and Curriculum Learning
Dec 18, 2022A hallmark of human intelligence is the ability to learn new concepts purely from language. Several recent approaches have explored training machine learning models via natural language supervision. However, these approaches fall short in leveraging linguistic quantifiers (such as 'always' or 'rarely') and mimicking humans in compositionally learning complex tasks. Here, we present LaSQuE, a method that can learn zero-shot classifiers from language explanations by using three new strategies - (1) modeling the semantics of linguistic quantifiers in explanations (including exploiting ordinal strength relationships, such as 'always' > 'likely'), (2) aggregating information from multiple explanations using an attention-based mechanism, and (3) model training via curriculum learning. With these strategies, LaSQuE outperforms prior work, showing an absolute gain of up to 7% in generalizing to unseen real-world classification tasks.
CLUES: A Benchmark for Learning Classifiers using Natural Language Explanations
Apr 14, 2022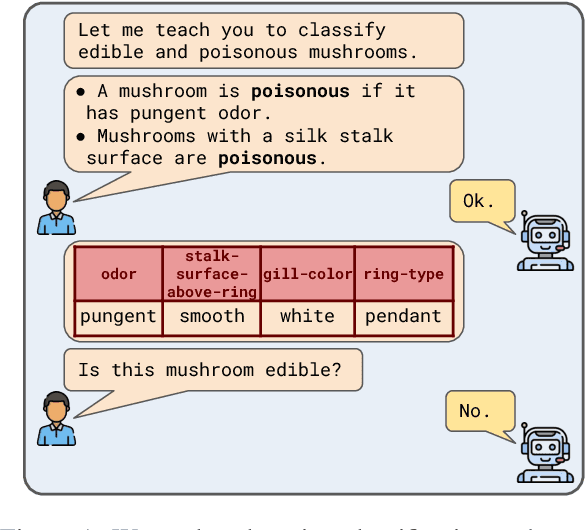
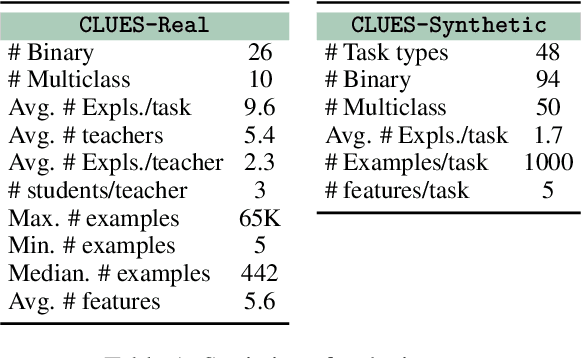

Supervised learning has traditionally focused on inductive learning by observing labeled examples of a task. In contrast, humans have the ability to learn new concepts from language. Here, we explore training zero-shot classifiers for structured data purely from language. For this, we introduce CLUES, a benchmark for Classifier Learning Using natural language ExplanationS, consisting of a range of classification tasks over structured data along with natural language supervision in the form of explanations. CLUES consists of 36 real-world and 144 synthetic classification tasks. It contains crowdsourced explanations describing real-world tasks from multiple teachers and programmatically generated explanations for the synthetic tasks. To model the influence of explanations in classifying an example, we develop ExEnt, an entailment-based model that learns classifiers using explanations. ExEnt generalizes up to 18% better (relative) on novel tasks than a baseline that does not use explanations. We delineate key challenges for automated learning from explanations, addressing which can lead to progress on CLUES in the future. Code and datasets are available at: https://clues-benchmark.github.io.
Improving and Simplifying Pattern Exploiting Training
Mar 22, 2021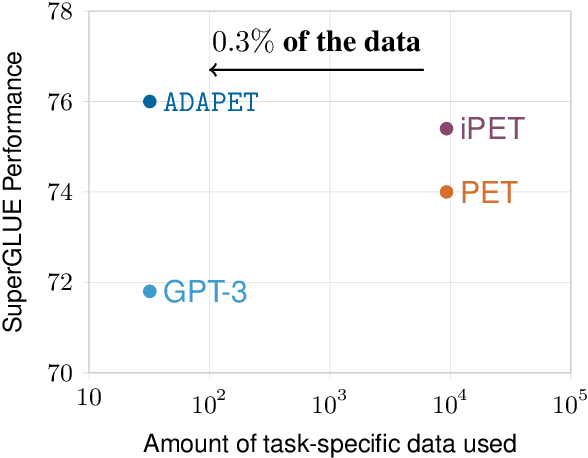



Recently, pre-trained language models (LMs) have achieved strong performance when fine-tuned on difficult benchmarks like SuperGLUE. However, performance can suffer when there are very few labeled examples available for fine-tuning. Pattern Exploiting Training (PET) is a recent approach that leverages patterns for few-shot learning. However, PET uses task-specific unlabeled data. In this paper, we focus on few shot learning without any unlabeled data and introduce ADAPET, which modifies PET's objective to provide denser supervision during fine-tuning. As a result, ADAPET outperforms PET on SuperGLUE without any task-specific unlabeled data. Our code can be found at https://github.com/rrmenon10/ADAPET.
Shared Learning : Enhancing Reinforcement in $Q$-Ensembles
Sep 14, 2017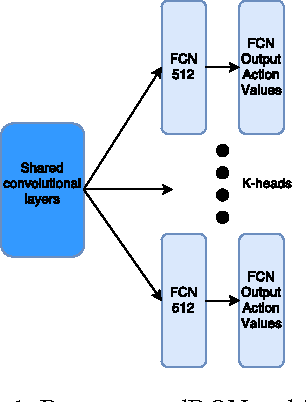

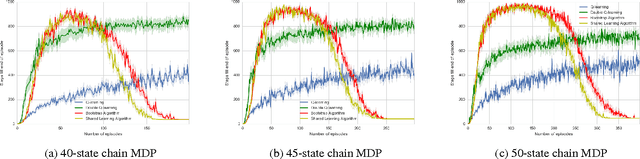

Deep Reinforcement Learning has been able to achieve amazing successes in a variety of domains from video games to continuous control by trying to maximize the cumulative reward. However, most of these successes rely on algorithms that require a large amount of data to train in order to obtain results on par with human-level performance. This is not feasible if we are to deploy these systems on real world tasks and hence there has been an increased thrust in exploring data efficient algorithms. To this end, we propose the Shared Learning framework aimed at making $Q$-ensemble algorithms data-efficient. For achieving this, we look into some principles of transfer learning which aim to study the benefits of information exchange across tasks in reinforcement learning and adapt transfer to learning our value function estimates in a novel manner. In this paper, we consider the special case of transfer between the value function estimates in the $Q$-ensemble architecture of BootstrappedDQN. We further empirically demonstrate how our proposed framework can help in speeding up the learning process in $Q$-ensembles with minimum computational overhead on a suite of Atari 2600 Games.