Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving and Simplifying Pattern Exploiting Training
Paper and Code
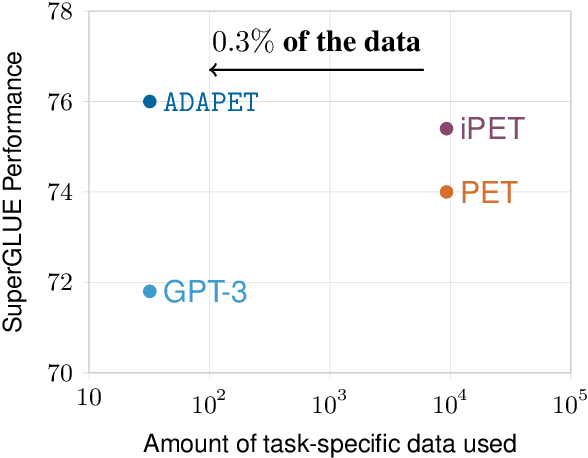



Recently, pre-trained language models (LMs) have achieved strong performance when fine-tuned on difficult benchmarks like SuperGLUE. However, performance can suffer when there are very few labeled examples available for fine-tuning. Pattern Exploiting Training (PET) is a recent approach that leverages patterns for few-shot learning. However, PET uses task-specific unlabeled data. In this paper, we focus on few shot learning without any unlabeled data and introduce ADAPET, which modifies PET's objective to provide denser supervision during fine-tuning. As a result, ADAPET outperforms PET on SuperGLUE without any task-specific unlabeled data. Our code can be found at https://github.com/rrmenon10/ADAPET.
* 11 pages, 2 figures
View paper on