 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling the Amount of Verbatim Copying in Abstractive Summarization
Paper and Code

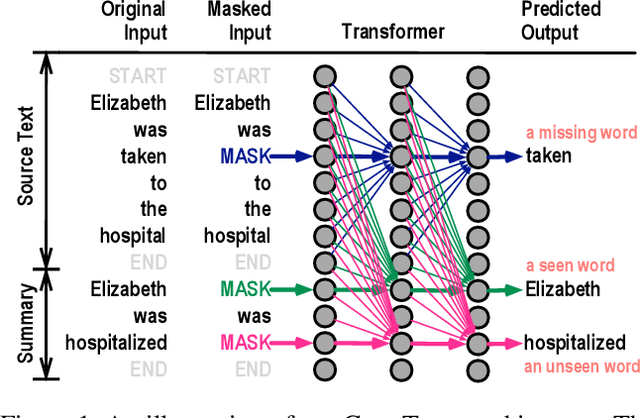

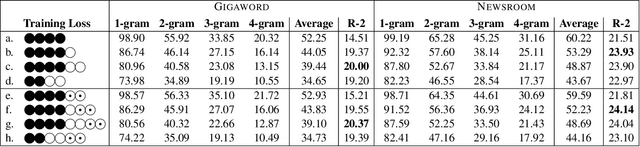
An abstract must not change the meaning of the original text. A single most effective way to achieve that is to increase the amount of copying while still allowing for text abstraction. Human editors can usually exercise control over copying, resulting in summaries that are more extractive than abstractive, or vice versa. However, it remains poorly understood whether modern neural abstractive summarizers can provide the same flexibility, i.e., learning from single reference summaries to generate multiple summary hypotheses with varying degrees of copying. In this paper, we present a neural summarization model that, by learning from single human abstracts, can produce a broad spectrum of summaries ranging from purely extractive to highly generative ones. We frame the task of summarization as language modeling and exploit alternative mechanisms to generate summary hypotheses. Our method allows for control over copying during both training and decoding stages of a neural summarization model. Through extensive experiments we illustrate the significance of our proposed method on controlling the amount of verbatim copying and achieve competitive results over strong baselines. Our analysis further reveals interesting and unobvious facts.