 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Fine-Tuning Methods for Portuguese Question Answering: A Comparative Study of PEFT on BERTimbau and Exploratory Evaluation of Generative LLMs
Mar 22, 2026Although large language models have transformed natural language processing, their computational costs create accessibility barriers for low-resource languages such as Brazilian Portuguese. This work presents a systematic evaluation of Parameter-Efficient Fine-Tuning (PEFT) and quantization techniques applied to BERTimbau for Question Answering on SQuAD-BR, the Brazilian Portuguese translation of SQuAD v1. We evaluate 40 configurations combining four PEFT methods (LoRA, DoRA, QLoRA, QDoRA) across two model sizes (Base: 110M, Large: 335M parameters). Our findings reveal three critical insights: (1) LoRA achieves 95.8\% of baseline performance on BERTimbau-Large while reducing training time by 73.5\% (F1=81.32 vs 84.86); (2) higher learning rates (2e-4) substantially improve PEFT performance, with F1 gains of up to +19.71 points over standard rates; and (3) larger models show twice the quantization resilience (loss of 4.83 vs 9.56 F1 points). These results demonstrate that encoder-based models can be efficiently fine-tuned for extractive Brazilian Portuguese QA with substantially lower computational cost than large generative LLMs, promoting more sustainable approaches aligned with \textit{Green AI} principles. An exploratory evaluation of Tucano and Sabiá on the same extractive QA benchmark shows that while generative models can reach competitive F1 scores with LoRA fine-tuning, they require up to 4.2$\times$ more GPU memory and 3$\times$ more training time than BERTimbau-Base, reinforcing the efficiency advantage of smaller encoder-based architectures for this task.
A Multi-Objective Evaluation Framework for Analyzing Utility-Fairness Trade-Offs in Machine Learning Systems
Mar 14, 2025



The evaluation of fairness models in Machine Learning involves complex challenges, such as defining appropriate metrics, balancing trade-offs between utility and fairness, and there are still gaps in this stage. This work presents a novel multi-objective evaluation framework that enables the analysis of utility-fairness trade-offs in Machine Learning systems. The framework was developed using criteria from Multi-Objective Optimization that collect comprehensive information regarding this complex evaluation task. The assessment of multiple Machine Learning systems is summarized, both quantitatively and qualitatively, in a straightforward manner through a radar chart and a measurement table encompassing various aspects such as convergence, system capacity, and diversity. The framework's compact representation of performance facilitates the comparative analysis of different Machine Learning strategies for decision-makers, in real-world applications, with single or multiple fairness requirements. The framework is model-agnostic and flexible to be adapted to any kind of Machine Learning systems, that is, black- or white-box, any kind and quantity of evaluation metrics, including multidimensional fairness criteria. The functionality and effectiveness of the proposed framework is shown with different simulations, and an empirical study conducted on a real-world dataset with various Machine Learning systems.
Fair Foundation Models for Medical Image Analysis: Challenges and Perspectives
Feb 24, 2025
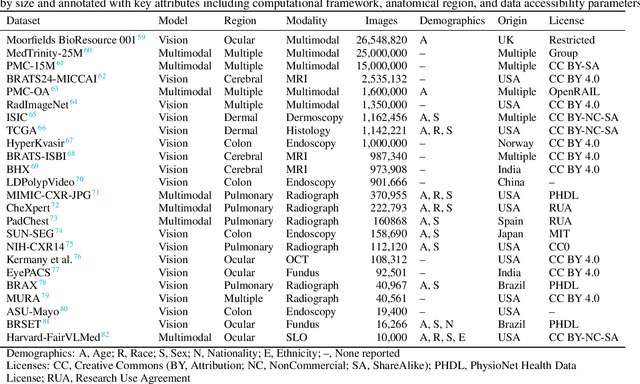

Ensuring equitable Artificial Intelligence (AI) in healthcare demands systems that make unbiased decisions across all demographic groups, bridging technical innovation with ethical principles. Foundation Models (FMs), trained on vast datasets through self-supervised learning, enable efficient adaptation across medical imaging tasks while reducing dependency on labeled data. These models demonstrate potential for enhancing fairness, though significant challenges remain in achieving consistent performance across demographic groups. Our review indicates that effective bias mitigation in FMs requires systematic interventions throughout all stages of development. While previous approaches focused primarily on model-level bias mitigation, our analysis reveals that fairness in FMs requires integrated interventions throughout the development pipeline, from data documentation to deployment protocols. This comprehensive framework advances current knowledge by demonstrating how systematic bias mitigation, combined with policy engagement, can effectively address both technical and institutional barriers to equitable AI in healthcare. The development of equitable FMs represents a critical step toward democratizing advanced healthcare technologies, particularly for underserved populations and regions with limited medical infrastructure and computational resources.
Does Data-Efficient Generalization Exacerbate Bias in Foundation Models?
Sep 02, 2024


Foundation models have emerged as robust models with label efficiency in diverse domains. In medical imaging, these models contribute to the advancement of medical diagnoses due to the difficulty in obtaining labeled data. However, it is unclear whether using a large amount of unlabeled data, biased by the presence of sensitive attributes during pre-training, influences the fairness of the model. This research examines the bias in the Foundation model (RetFound) when it is applied to fine-tune the Brazilian Multilabel Ophthalmological Dataset (BRSET), which has a different population than the pre-training dataset. The model evaluation, in comparison with supervised learning, shows that the Foundation Model has the potential to reduce the gap between the maximum AUC and minimum AUC evaluations across gender and age groups. However, in a data-efficient generalization, the model increases the bias when the data amount decreases. These findings suggest that when deploying a Foundation Model in real-life scenarios with limited data, the possibility of fairness issues should be considered.
Using Backbone Foundation Model for Evaluating Fairness in Chest Radiography Without Demographic Data
Aug 28, 2024Ensuring consistent performance across diverse populations and incorporating fairness into machine learning models are crucial for advancing medical image diagnostics and promoting equitable healthcare. However, many databases do not provide protected attributes or contain unbalanced representations of demographic groups, complicating the evaluation of model performance across different demographics and the application of bias mitigation techniques that rely on these attributes. This study aims to investigate the effectiveness of using the backbone of Foundation Models as an embedding extractor for creating groups that represent protected attributes, such as gender and age. We propose utilizing these groups in different stages of bias mitigation, including pre-processing, in-processing, and evaluation. Using databases in and out-of-distribution scenarios, it is possible to identify that the method can create groups that represent gender in both databases and reduce in 4.44% the difference between the gender attribute in-distribution and 6.16% in out-of-distribution. However, the model lacks robustness in handling age attributes, underscoring the need for more fundamentally fair and robust Foundation models. These findings suggest a role in promoting fairness assessment in scenarios where we lack knowledge of attributes, contributing to the development of more equitable medical diagnostics.
QT-Routenet: Improved GNN generalization to larger 5G networks by fine-tuning predictions from queueing theory
Jul 13, 2022
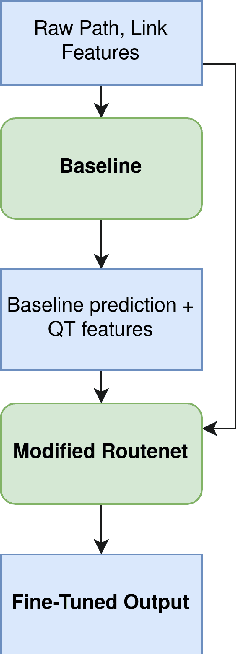


In order to promote the use of machine learning in 5G, the International Telecommunication Union (ITU) proposed in 2021 the second edition of the ITU AI/ML in 5G challenge, with over 1600 participants from 82 countries. This work details the second place solution overall, which is also the winning solution of the Graph Neural Networking Challenge 2021. We tackle the problem of generalization when applying a model to a 5G network that may have longer paths and larger link capacities than the ones observed in training. To achieve this, we propose to first extract robust features related to Queueing Theory (QT), and then fine-tune the analytical baseline prediction using a modification of the Routenet Graph Neural Network (GNN) model. The proposed solution generalizes much better than simply using Routenet, and manages to reduce the analytical baseline's 10.42 mean absolute percent error to 1.45 (1.27 with an ensemble). This suggests that making small changes to an approximate model that is known to be robust can be an effective way to improve accuracy without compromising generalization.
Optimizing Diffusion Rate and Label Reliability in a Graph-Based Semi-supervised Classifier
Jan 10, 2022
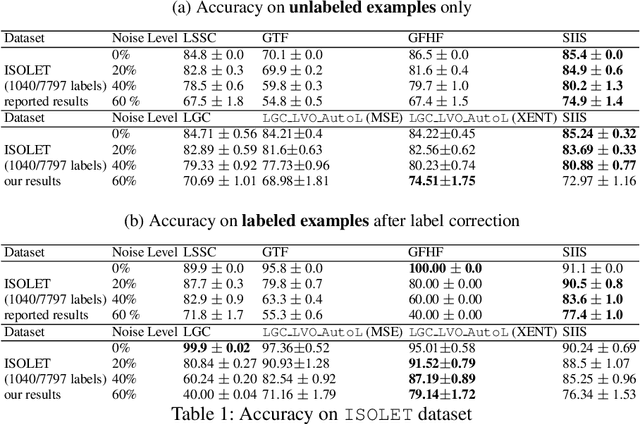
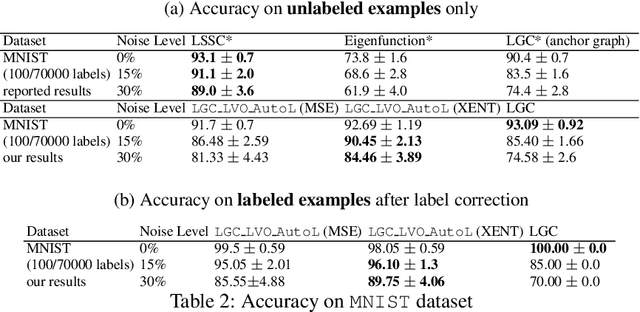
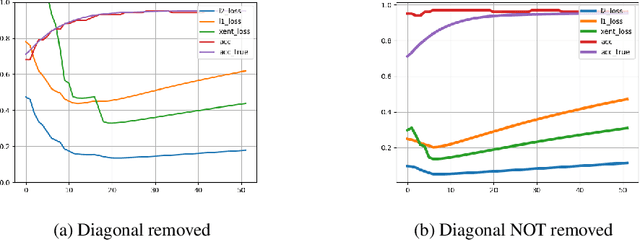
Semi-supervised learning has received attention from researchers, as it allows one to exploit the structure of unlabeled data to achieve competitive classification results with much fewer labels than supervised approaches. The Local and Global Consistency (LGC) algorithm is one of the most well-known graph-based semi-supervised (GSSL) classifiers. Notably, its solution can be written as a linear combination of the known labels. The coefficients of this linear combination depend on a parameter $\alpha$, determining the decay of the reward over time when reaching labeled vertices in a random walk. In this work, we discuss how removing the self-influence of a labeled instance may be beneficial, and how it relates to leave-one-out error. Moreover, we propose to minimize this leave-one-out loss with automatic differentiation. Within this framework, we propose methods to estimate label reliability and diffusion rate. Optimizing the diffusion rate is more efficiently accomplished with a spectral representation. Results show that the label reliability approach competes with robust L1-norm methods and that removing diagonal entries reduces the risk of overfitting and leads to suitable criteria for parameter selection.
Analysis of label noise in graph-based semi-supervised learning
Sep 27, 2020
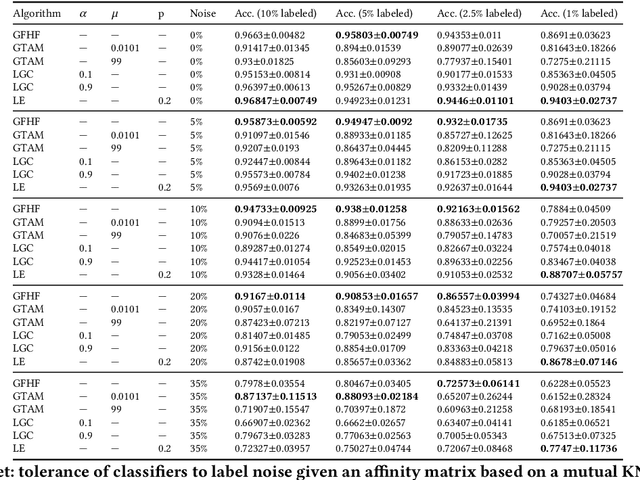
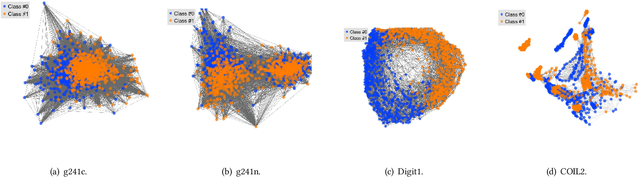
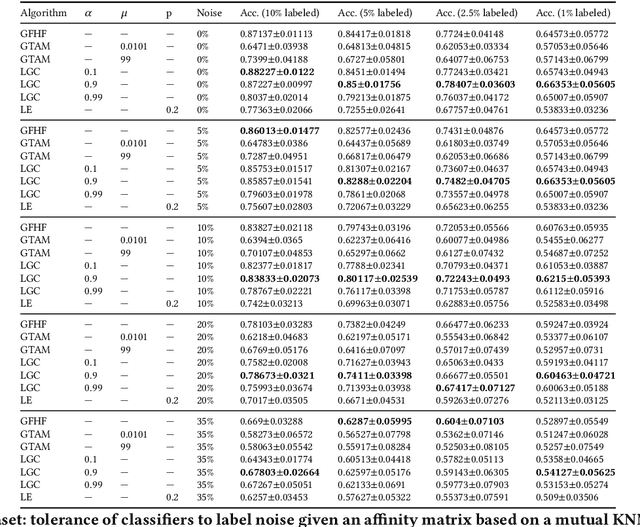
In machine learning, one must acquire labels to help supervise a model that will be able to generalize to unseen data. However, the labeling process can be tedious, long, costly, and error-prone. It is often the case that most of our data is unlabeled. Semi-supervised learning (SSL) alleviates that by making strong assumptions about the relation between the labels and the input data distribution. This paradigm has been successful in practice, but most SSL algorithms end up fully trusting the few available labels. In real life, both humans and automated systems are prone to mistakes; it is essential that our algorithms are able to work with labels that are both few and also unreliable. Our work aims to perform an extensive empirical evaluation of existing graph-based semi-supervised algorithms, like Gaussian Fields and Harmonic Functions, Local and Global Consistency, Laplacian Eigenmaps, Graph Transduction Through Alternating Minimization. To do that, we compare the accuracy of classifiers while varying the amount of labeled data and label noise for many different samples. Our results show that, if the dataset is consistent with SSL assumptions, we are able to detect the noisiest instances, although this gets harder when the number of available labels decreases. Also, the Laplacian Eigenmaps algorithm performed better than label propagation when the data came from high-dimensional clusters.
Identifying noisy labels with a transductive semi-supervised leave-one-out filter
Sep 24, 2020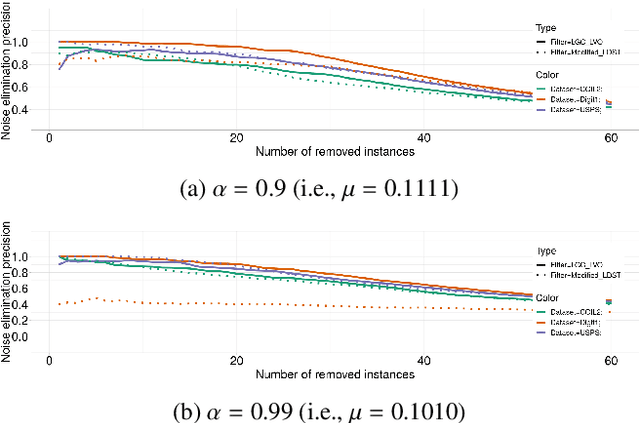
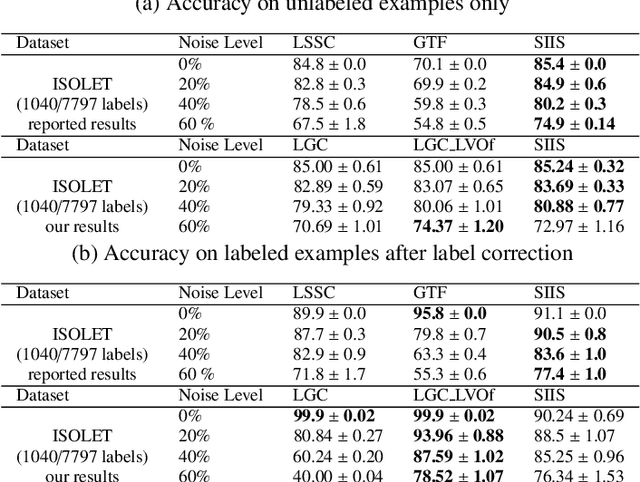
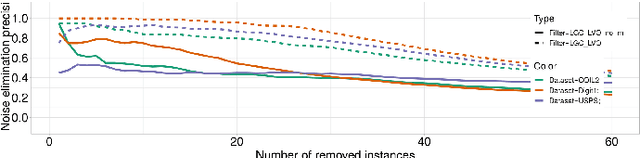
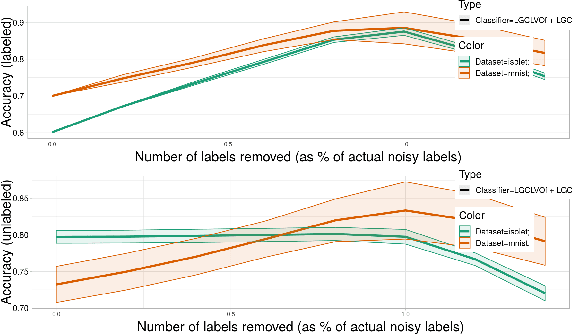
Obtaining data with meaningful labels is often costly and error-prone. In this situation, semi-supervised learning (SSL) approaches are interesting, as they leverage assumptions about the unlabeled data to make up for the limited amount of labels. However, in real-world situations, we cannot assume that the labeling process is infallible, and the accuracy of many SSL classifiers decreases significantly in the presence of label noise. In this work, we introduce the LGC_LVOF, a leave-one-out filtering approach based on the Local and Global Consistency (LGC) algorithm. Our method aims to detect and remove wrong labels, and thus can be used as a preprocessing step to any SSL classifier. Given the propagation matrix, detecting noisy labels takes O(cl) per step, with c the number of classes and l the number of labels. Moreover, one does not need to compute the whole propagation matrix, but only an $l$ by $l$ submatrix corresponding to interactions between labeled instances. As a result, our approach is best suited to datasets with a large amount of unlabeled data but not many labels. Results are provided for a number of datasets, including MNIST and ISOLET. LGCLVOF appears to be equally or more precise than the adapted gradient-based filter. We show that the best-case accuracy of the embedding of LGCLVOF into LGC yields performance comparable to the best-case of $\ell_1$-based classifiers designed to be robust to label noise. We provide a heuristic to choose the number of removed instances.
Cluster analysis of homicide rates in the Brazilian state of Goias from 2002 to 2014
Nov 11, 2018
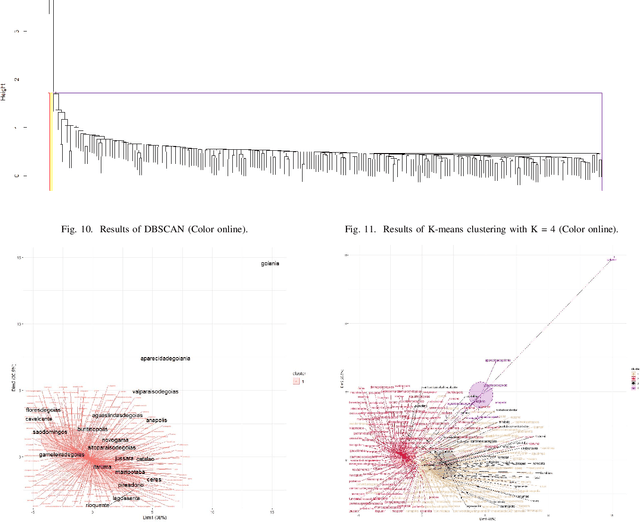
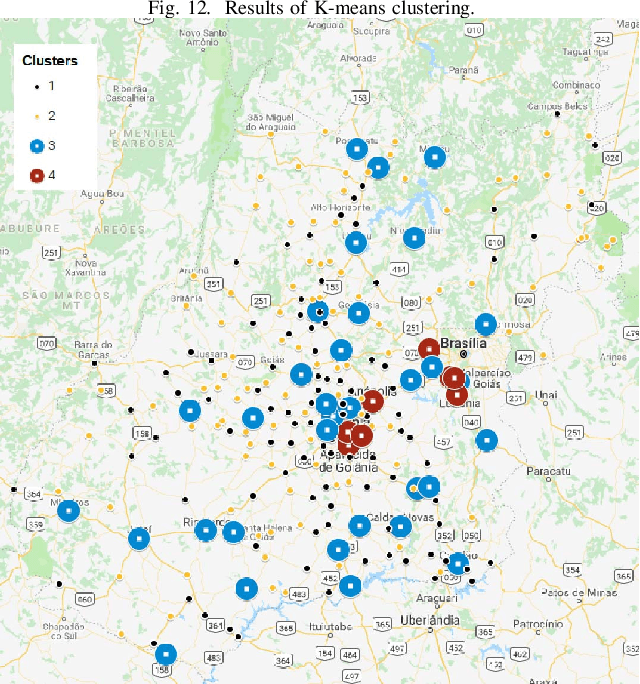
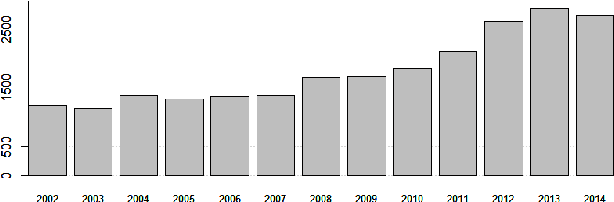
Homicide mortality is a worldwide concern and has occupied the agenda of researchers and public managers. In Brazil, homicide is the third leading cause of death in the general population and the first in the 15-39 age group. In South America, Brazil has the third highest homicide mortality, behind Venezuela and Colombia. To measure the impacts of violence it is important to assess health systems and criminal justice, as well as other areas. In this paper, we analyze the spatial distribution of homicide mortality in the state of Goias, Center-West of Brazil, since the homicide rate increased from 24.5 per 100,000 in 2002 to 42.6 per 100,000 in 2014 in this location. Moreover, this state had the fifth position of homicides in Brazil in 2014. We considered socio-demographic variables for the state, performed analysis about correlation and employed three clustering algorithms: K-means, Density-based and Hierarchical. The results indicate the homicide rates are higher in cities neighbors of large urban centers, although these cities have the best socioeconomic indicators.