 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQT-Routenet: Improved GNN generalization to larger 5G networks by fine-tuning predictions from queueing theory
Jul 13, 2022
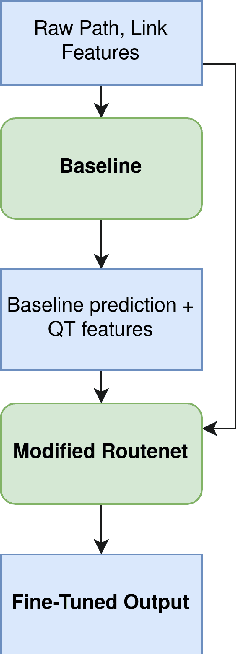


In order to promote the use of machine learning in 5G, the International Telecommunication Union (ITU) proposed in 2021 the second edition of the ITU AI/ML in 5G challenge, with over 1600 participants from 82 countries. This work details the second place solution overall, which is also the winning solution of the Graph Neural Networking Challenge 2021. We tackle the problem of generalization when applying a model to a 5G network that may have longer paths and larger link capacities than the ones observed in training. To achieve this, we propose to first extract robust features related to Queueing Theory (QT), and then fine-tune the analytical baseline prediction using a modification of the Routenet Graph Neural Network (GNN) model. The proposed solution generalizes much better than simply using Routenet, and manages to reduce the analytical baseline's 10.42 mean absolute percent error to 1.45 (1.27 with an ensemble). This suggests that making small changes to an approximate model that is known to be robust can be an effective way to improve accuracy without compromising generalization.
Optimizing Diffusion Rate and Label Reliability in a Graph-Based Semi-supervised Classifier
Jan 10, 2022
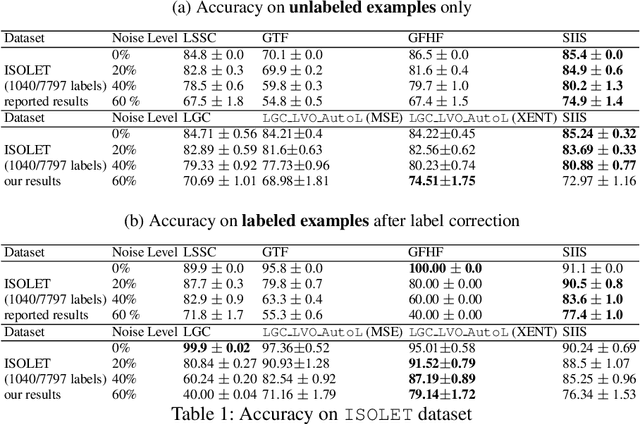
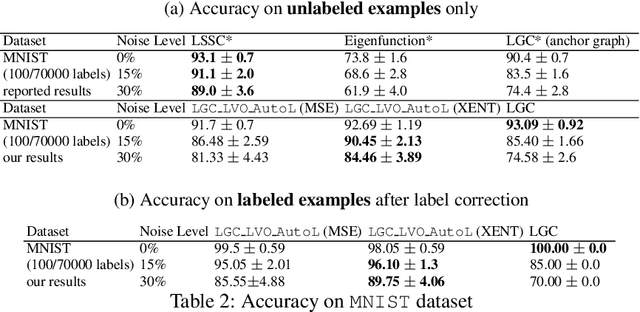
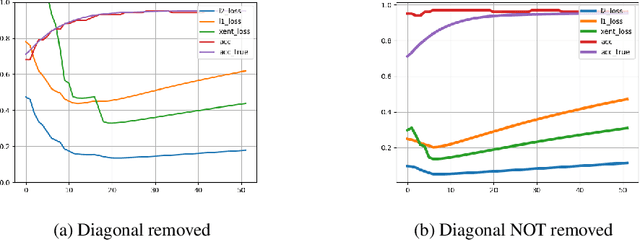
Semi-supervised learning has received attention from researchers, as it allows one to exploit the structure of unlabeled data to achieve competitive classification results with much fewer labels than supervised approaches. The Local and Global Consistency (LGC) algorithm is one of the most well-known graph-based semi-supervised (GSSL) classifiers. Notably, its solution can be written as a linear combination of the known labels. The coefficients of this linear combination depend on a parameter $\alpha$, determining the decay of the reward over time when reaching labeled vertices in a random walk. In this work, we discuss how removing the self-influence of a labeled instance may be beneficial, and how it relates to leave-one-out error. Moreover, we propose to minimize this leave-one-out loss with automatic differentiation. Within this framework, we propose methods to estimate label reliability and diffusion rate. Optimizing the diffusion rate is more efficiently accomplished with a spectral representation. Results show that the label reliability approach competes with robust L1-norm methods and that removing diagonal entries reduces the risk of overfitting and leads to suitable criteria for parameter selection.
Analysis of label noise in graph-based semi-supervised learning
Sep 27, 2020
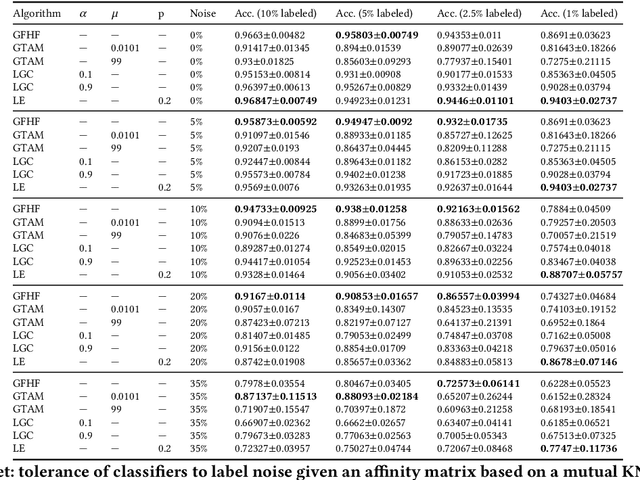
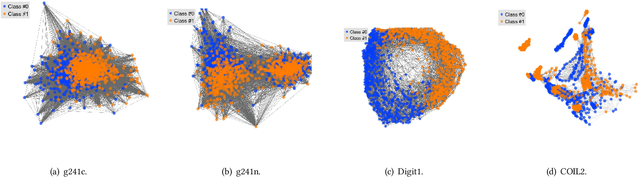
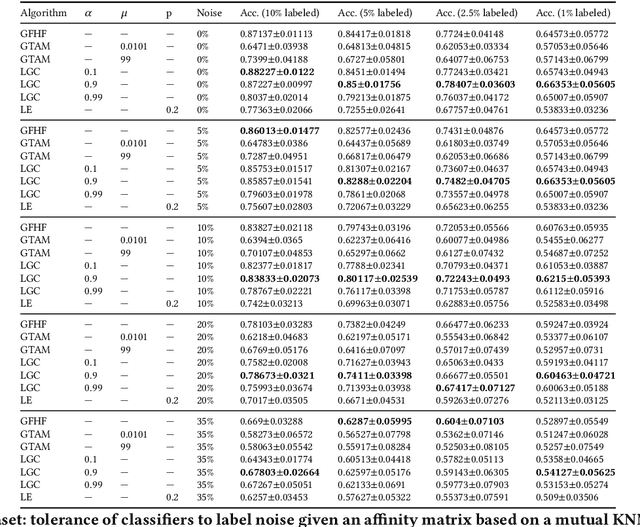
In machine learning, one must acquire labels to help supervise a model that will be able to generalize to unseen data. However, the labeling process can be tedious, long, costly, and error-prone. It is often the case that most of our data is unlabeled. Semi-supervised learning (SSL) alleviates that by making strong assumptions about the relation between the labels and the input data distribution. This paradigm has been successful in practice, but most SSL algorithms end up fully trusting the few available labels. In real life, both humans and automated systems are prone to mistakes; it is essential that our algorithms are able to work with labels that are both few and also unreliable. Our work aims to perform an extensive empirical evaluation of existing graph-based semi-supervised algorithms, like Gaussian Fields and Harmonic Functions, Local and Global Consistency, Laplacian Eigenmaps, Graph Transduction Through Alternating Minimization. To do that, we compare the accuracy of classifiers while varying the amount of labeled data and label noise for many different samples. Our results show that, if the dataset is consistent with SSL assumptions, we are able to detect the noisiest instances, although this gets harder when the number of available labels decreases. Also, the Laplacian Eigenmaps algorithm performed better than label propagation when the data came from high-dimensional clusters.
Identifying noisy labels with a transductive semi-supervised leave-one-out filter
Sep 24, 2020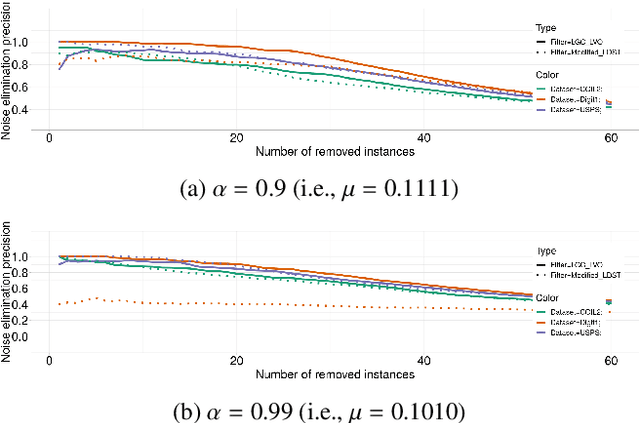
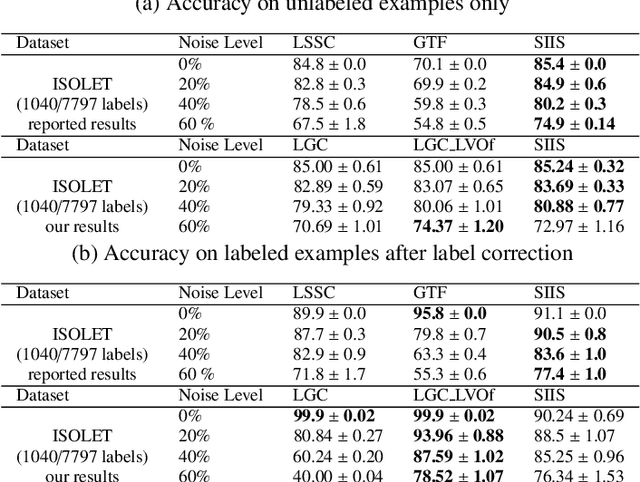
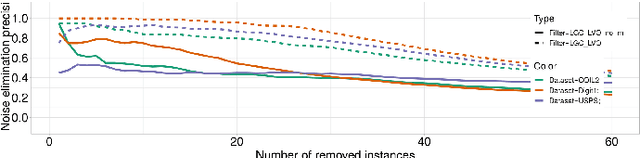
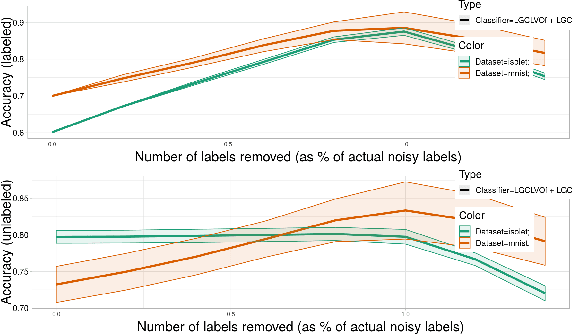
Obtaining data with meaningful labels is often costly and error-prone. In this situation, semi-supervised learning (SSL) approaches are interesting, as they leverage assumptions about the unlabeled data to make up for the limited amount of labels. However, in real-world situations, we cannot assume that the labeling process is infallible, and the accuracy of many SSL classifiers decreases significantly in the presence of label noise. In this work, we introduce the LGC_LVOF, a leave-one-out filtering approach based on the Local and Global Consistency (LGC) algorithm. Our method aims to detect and remove wrong labels, and thus can be used as a preprocessing step to any SSL classifier. Given the propagation matrix, detecting noisy labels takes O(cl) per step, with c the number of classes and l the number of labels. Moreover, one does not need to compute the whole propagation matrix, but only an $l$ by $l$ submatrix corresponding to interactions between labeled instances. As a result, our approach is best suited to datasets with a large amount of unlabeled data but not many labels. Results are provided for a number of datasets, including MNIST and ISOLET. LGCLVOF appears to be equally or more precise than the adapted gradient-based filter. We show that the best-case accuracy of the embedding of LGCLVOF into LGC yields performance comparable to the best-case of $\ell_1$-based classifiers designed to be robust to label noise. We provide a heuristic to choose the number of removed instances.