 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Evaluation of Open-Set Image Classification Techniques
Paper and Code
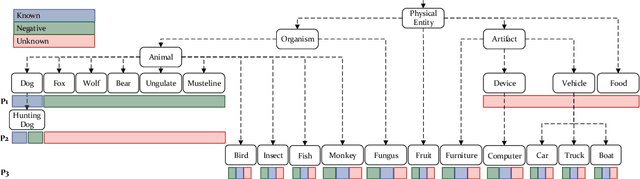
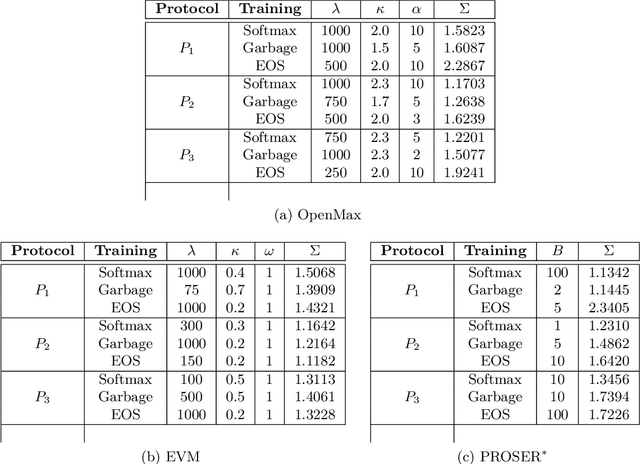

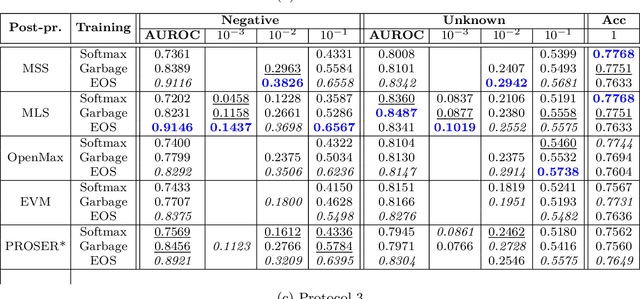
The goal for classification is to correctly assign labels to unseen samples. However, most methods misclassify samples with unseen labels and assign them to one of the known classes. Open-Set Classification (OSC) algorithms aim to maximize both closed and open-set recognition capabilities. Recent studies showed the utility of such algorithms on small-scale data sets, but limited experimentation makes it difficult to assess their performances in real-world problems. Here, we provide a comprehensive comparison of various OSC algorithms, including training-based (SoftMax, Garbage, EOS) and post-processing methods (Maximum SoftMax Scores, Maximum Logit Scores, OpenMax, EVM, PROSER), the latter are applied on features from the former. We perform our evaluation on three large-scale protocols that mimic real-world challenges, where we train on known and negative open-set samples, and test on known and unknown instances. Our results show that EOS helps to improve performance of almost all post-processing algorithms. Particularly, OpenMax and PROSER are able to exploit better-trained networks, demonstrating the utility of hybrid models. However, while most algorithms work well on negative test samples -- samples of open-set classes seen during training -- they tend to perform poorly when tested on samples of previously unseen unknown classes, especially in challenging conditions.