 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepBinaryMask: Learning a Binary Mask for Video Compressive Sensing
Paper and Code
Jul 18, 2016
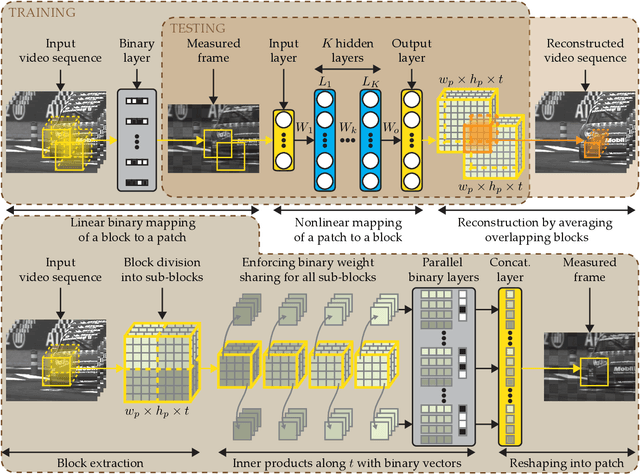
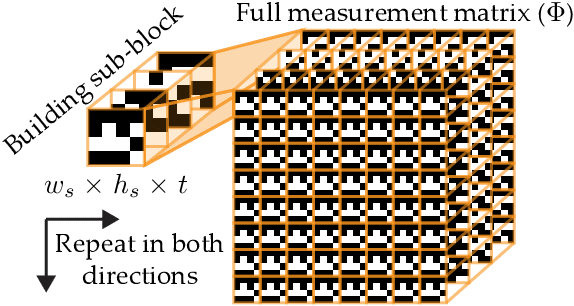
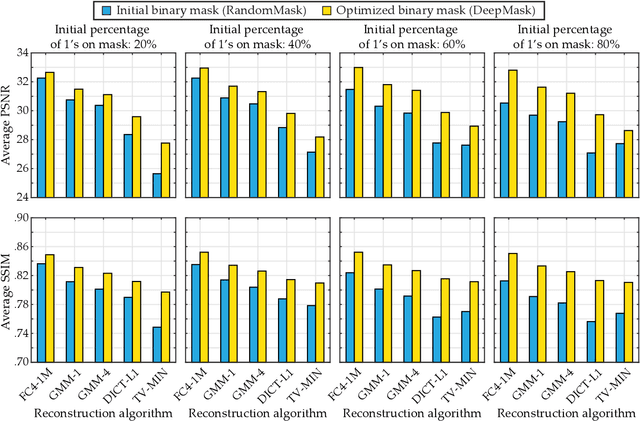
In this paper, we propose a novel encoder-decoder neural network model referred to as DeepBinaryMask for video compressive sensing. In video compressive sensing one frame is acquired using a set of coded masks (sensing matrix) from which a number of video frames is reconstructed, equal to the number of coded masks. The proposed framework is an end-to-end model where the sensing matrix is trained along with the video reconstruction. The encoder learns the binary elements of the sensing matrix and the decoder is trained to recover the unknown video sequence. The reconstruction performance is found to improve when using the trained sensing mask from the network as compared to other mask designs such as random, across a wide variety of compressive sensing reconstruction algorithms. Finally, our analysis and discussion offers insights into understanding the characteristics of the trained mask designs that lead to the improved reconstruction quality.