 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMAC: A Semantic-Driven Integrated Multimodal Sensing And Communication Framework
Mar 11, 2025Traditional single-modality sensing faces limitations in accuracy and capability, and its decoupled implementation with communication systems increases latency in bandwidth-constrained environments. Additionally, single-task-oriented sensing systems fail to address users' diverse demands. To overcome these challenges, we propose a semantic-driven integrated multimodal sensing and communication (SIMAC) framework. This framework leverages a joint source-channel coding architecture to achieve simultaneous sensing decoding and transmission of sensing results. Specifically, SIMAC first introduces a multimodal semantic fusion (MSF) network, which employs two extractors to extract semantic information from radar signals and images, respectively. MSF then applies cross-attention mechanisms to fuse these unimodal features and generate multimodal semantic representations. Secondly, we present a large language model (LLM)-based semantic encoder (LSE), where relevant communication parameters and multimodal semantics are mapped into a unified latent space and input to the LLM, enabling channel-adaptive semantic encoding. Thirdly, a task-oriented sensing semantic decoder (SSD) is proposed, in which different decoded heads are designed according to the specific needs of tasks. Simultaneously, a multi-task learning strategy is introduced to train the SIMAC framework, achieving diverse sensing services. Finally, experimental simulations demonstrate that the proposed framework achieves diverse sensing services and higher accuracy.
Semantic Communications with Computer Vision Sensing for Edge Video Transmission
Mar 10, 2025



Despite the widespread adoption of vision sensors in edge applications, such as surveillance, the transmission of video data consumes substantial spectrum resources. Semantic communication (SC) offers a solution by extracting and compressing information at the semantic level, preserving the accuracy and relevance of transmitted data while significantly reducing the volume of transmitted information. However, traditional SC methods face inefficiencies due to the repeated transmission of static frames in edge videos, exacerbated by the absence of sensing capabilities, which results in spectrum inefficiency. To address this challenge, we propose a SC with computer vision sensing (SCCVS) framework for edge video transmission. The framework first introduces a compression ratio (CR) adaptive SC (CRSC) model, capable of adjusting CR based on whether the frames are static or dynamic, effectively conserving spectrum resources. Additionally, we implement an object detection and semantic segmentation models-enabled sensing (OSMS) scheme, which intelligently senses the changes in the scene and assesses the significance of each frame through in-context analysis. Hence, The OSMS scheme provides CR prompts to the CRSC model based on real-time sensing results. Moreover, both CRSC and OSMS are designed as lightweight models, ensuring compatibility with resource-constrained sensors commonly used in practical edge applications. Experimental simulations validate the effectiveness of the proposed SCCVS framework, demonstrating its ability to enhance transmission efficiency without sacrificing critical semantic information.
Attention-based UAV Trajectory Optimization for Wireless Power Transfer-assisted IoT Systems
Feb 23, 2025Unmanned Aerial Vehicles (UAVs) in Wireless Power Transfer (WPT)-assisted Internet of Things (IoT) systems face the following challenges: limited resources and suboptimal trajectory planning. Reinforcement learning-based trajectory planning schemes face issues of low search efficiency and learning instability when optimizing large-scale systems. To address these issues, we present an Attention-based UAV Trajectory Optimization (AUTO) framework based on the graph transformer, which consists of an Attention Trajectory Optimization Model (ATOM) and a Trajectory lEarNing Method based on Actor-critic (TENMA). In ATOM, a graph encoder is used to calculate the self-attention characteristics of all IoTDs, and a trajectory decoder is developed to optimize the number and trajectories of UAVs. TENMA then trains the ATOM using an improved Actor-Critic method, in which the real reward of the system is applied as the baseline to reduce variances in the critic network. This method is suitable for high-quality and large-scale multi-UAV trajectory planning. Finally, we develop numerous experiments, including a hardware experiment in the field case, to verify the feasibility and efficiency of the AUTO framework.
Explainable Semantic Federated Learning Enabled Industrial Edge Network for Fire Surveillance
Dec 28, 2024In fire surveillance, Industrial Internet of Things (IIoT) devices require transmitting large monitoring data frequently, which leads to huge consumption of spectrum resources. Hence, we propose an Industrial Edge Semantic Network (IESN) to allow IIoT devices to send warnings through Semantic communication (SC). Thus, we should consider (1) Data privacy and security. (2) SC model adaptation for heterogeneous devices. (3) Explainability of semantics. Therefore, first, we present an eXplainable Semantic Federated Learning (XSFL) to train the SC model, thus ensuring data privacy and security. Then, we present an Adaptive Client Training (ACT) strategy to provide a specific SC model for each device according to its Fisher information matrix, thus overcoming the heterogeneity. Next, an Explainable SC (ESC) mechanism is designed, which introduces a leakyReLU-based activation mapping to explain the relationship between the extracted semantics and monitoring data. Finally, simulation results demonstrate the effectiveness of XSFL.
* 9 pages
GAI-Enabled Explainable Personalized Federated Semi-Supervised Learning
Oct 11, 2024

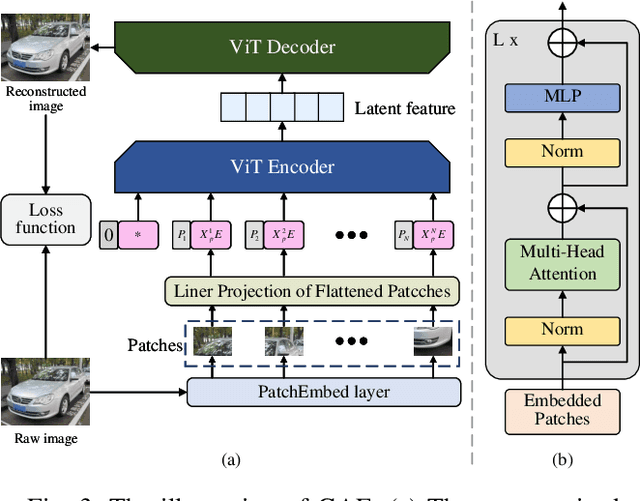
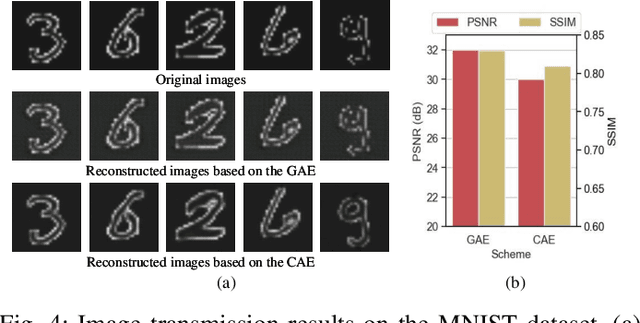
Federated learning (FL) is a commonly distributed algorithm for mobile users (MUs) training artificial intelligence (AI) models, however, several challenges arise when applying FL to real-world scenarios, such as label scarcity, non-IID data, and unexplainability. As a result, we propose an explainable personalized FL framework, called XPFL. First, we introduce a generative AI (GAI) assisted personalized federated semi-supervised learning, called GFed. Particularly, in local training, we utilize a GAI model to learn from large unlabeled data and apply knowledge distillation-based semi-supervised learning to train the local FL model using the knowledge acquired from the GAI model. In global aggregation, we obtain the new local FL model by fusing the local and global FL models in specific proportions, allowing each local model to incorporate knowledge from others while preserving its personalized characteristics. Second, we propose an explainable AI mechanism for FL, named XFed. Specifically, in local training, we apply a decision tree to match the input and output of the local FL model. In global aggregation, we utilize t-distributed stochastic neighbor embedding (t-SNE) to visualize the local models before and after aggregation. Finally, simulation results validate the effectiveness of the proposed XPFL framework.
Deep progressive reinforcement learning-based flexible resource scheduling framework for IRS and UAV-assisted MEC system
Aug 02, 2024



The intelligent reflection surface (IRS) and unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) system is widely used in temporary and emergency scenarios. Our goal is to minimize the energy consumption of the MEC system by jointly optimizing UAV locations, IRS phase shift, task offloading, and resource allocation with a variable number of UAVs. To this end, we propose a Flexible REsource Scheduling (FRES) framework by employing a novel deep progressive reinforcement learning which includes the following innovations: Firstly, a novel multi-task agent is presented to deal with the mixed integer nonlinear programming (MINLP) problem. The multi-task agent has two output heads designed for different tasks, in which a classified head is employed to make offloading decisions with integer variables while a fitting head is applied to solve resource allocation with continuous variables. Secondly, a progressive scheduler is introduced to adapt the agent to the varying number of UAVs by progressively adjusting a part of neurons in the agent. This structure can naturally accumulate experiences and be immune to catastrophic forgetting. Finally, a light taboo search (LTS) is introduced to enhance the global search of the FRES. The numerical results demonstrate the superiority of the FRES framework which can make real-time and optimal resource scheduling even in dynamic MEC systems.
* 13 pages, 10 figures
Personalized Wireless Federated Learning for Large Language Models
Apr 20, 2024

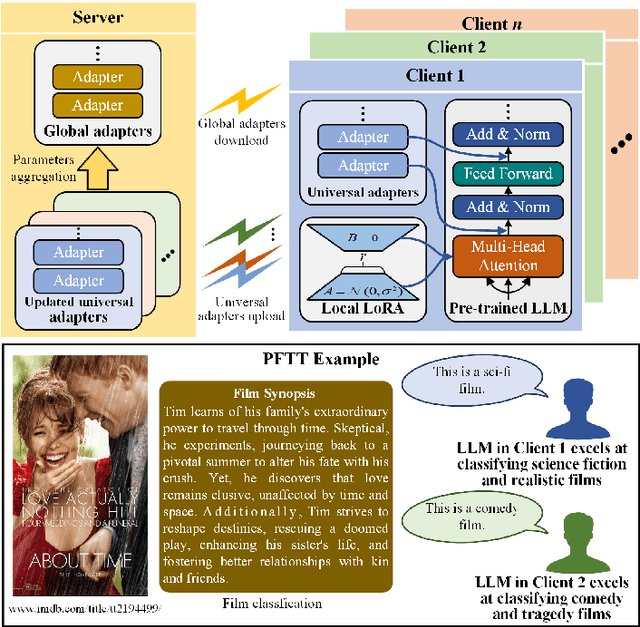

Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
Large Generative Model Assisted 3D Semantic Communication
Mar 09, 2024



Semantic Communication (SC) is a novel paradigm for data transmission in 6G. However, there are several challenges posed when performing SC in 3D scenarios: 1) 3D semantic extraction; 2) Latent semantic redundancy; and 3) Uncertain channel estimation. To address these issues, we propose a Generative AI Model assisted 3D SC (GAM-3DSC) system. Firstly, we introduce a 3D Semantic Extractor (3DSE), which employs generative AI models, including Segment Anything Model (SAM) and Neural Radiance Field (NeRF), to extract key semantics from a 3D scenario based on user requirements. The extracted 3D semantics are represented as multi-perspective images of the goal-oriented 3D object. Then, we present an Adaptive Semantic Compression Model (ASCM) for encoding these multi-perspective images, in which we use a semantic encoder with two output heads to perform semantic encoding and mask redundant semantics in the latent semantic space, respectively. Next, we design a conditional Generative adversarial network and Diffusion model aided-Channel Estimation (GDCE) to estimate and refine the Channel State Information (CSI) of physical channels. Finally, simulation results demonstrate the advantages of the proposed GAM-3DSC system in effectively transmitting the goal-oriented 3D scenario.
Large Language Model Enhanced Multi-Agent Systems for 6G Communications
Dec 13, 2023

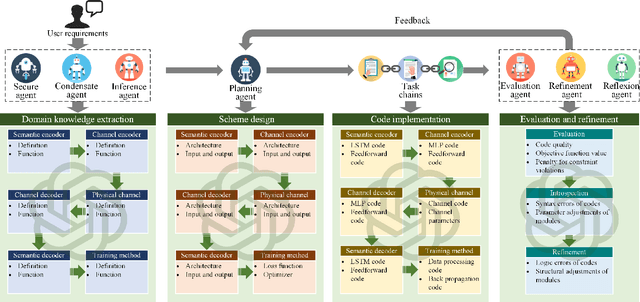

The rapid development of the Large Language Model (LLM) presents huge opportunities for 6G communications, e.g., network optimization and management by allowing users to input task requirements to LLMs by nature language. However, directly applying native LLMs in 6G encounters various challenges, such as a lack of private communication data and knowledge, limited logical reasoning, evaluation, and refinement abilities. Integrating LLMs with the capabilities of retrieval, planning, memory, evaluation and reflection in agents can greatly enhance the potential of LLMs for 6G communications. To this end, we propose a multi-agent system with customized communication knowledge and tools for solving communication related tasks using natural language, comprising three components: (1) Multi-agent Data Retrieval (MDR), which employs the condensate and inference agents to refine and summarize communication knowledge from the knowledge base, expanding the knowledge boundaries of LLMs in 6G communications; (2) Multi-agent Collaborative Planning (MCP), which utilizes multiple planning agents to generate feasible solutions for the communication related task from different perspectives based on the retrieved knowledge; (3) Multi-agent Evaluation and Reflecxion (MER), which utilizes the evaluation agent to assess the solutions, and applies the reflexion agent and refinement agent to provide improvement suggestions for current solutions. Finally, we validate the effectiveness of the proposed multi-agent system by designing a semantic communication system, as a case study of 6G communications.
Large AI Model Empowered Multimodal Semantic Communications
Sep 03, 2023

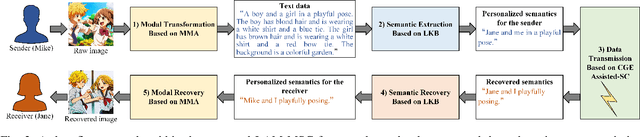

Multimodal signals, including text, audio, image and video, can be integrated into Semantic Communication (SC) for providing an immersive experience with low latency and high quality at the semantic level. However, the multimodal SC has several challenges, including data heterogeneity, semantic ambiguity, and signal fading. Recent advancements in large AI models, particularly in Multimodal Language Model (MLM) and Large Language Model (LLM), offer potential solutions for these issues. To this end, we propose a Large AI Model-based Multimodal SC (LAM-MSC) framework, in which we first present the MLM-based Multimodal Alignment (MMA) that utilizes the MLM to enable the transformation between multimodal and unimodal data while preserving semantic consistency. Then, a personalized LLM-based Knowledge Base (LKB) is proposed, which allows users to perform personalized semantic extraction or recovery through the LLM. This effectively addresses the semantic ambiguity. Finally, we apply the Conditional Generative adversarial networks-based channel Estimation (CGE) to obtain Channel State Information (CSI). This approach effectively mitigates the impact of fading channels in SC. Finally, we conduct simulations that demonstrate the superior performance of the LAM-MSC framework.